 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Uniformity and Alignment for Multimodal Representation Learning
Feb 10, 2026Multimodal representation learning aims to construct a shared embedding space in which heterogeneous modalities are semantically aligned. Despite strong empirical results, InfoNCE-based objectives introduce inherent conflicts that yield distribution gaps across modalities. In this work, we identify two conflicts in the multimodal regime, both exacerbated as the number of modalities increases: (i) an alignment-uniformity conflict, whereby the repulsion of uniformity undermines pairwise alignment, and (ii) an intra-alignment conflict, where aligning multiple modalities induces competing alignment directions. To address these issues, we propose a principled decoupling of alignment and uniformity for multimodal representations, providing a conflict-free recipe for multimodal learning that simultaneously supports discriminative and generative use cases without task-specific modules. We then provide a theoretical guarantee that our method acts as an efficient proxy for a global Hölder divergence over multiple modality distributions, and thus reduces the distribution gap among modalities. Extensive experiments on retrieval and UnCLIP-style generation demonstrate consistent gains.
Progressive Scaling Visual Object Tracking
May 26, 2025In this work, we propose a progressive scaling training strategy for visual object tracking, systematically analyzing the influence of training data volume, model size, and input resolution on tracking performance. Our empirical study reveals that while scaling each factor leads to significant improvements in tracking accuracy, naive training suffers from suboptimal optimization and limited iterative refinement. To address this issue, we introduce DT-Training, a progressive scaling framework that integrates small teacher transfer and dual-branch alignment to maximize model potential. The resulting scaled tracker consistently outperforms state-of-the-art methods across multiple benchmarks, demonstrating strong generalization and transferability of the proposed method. Furthermore, we validate the broader applicability of our approach to additional tasks, underscoring its versatility beyond tracking.
Probabilistic Interactive 3D Segmentation with Hierarchical Neural Processes
May 03, 2025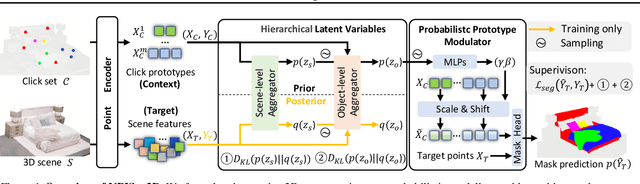
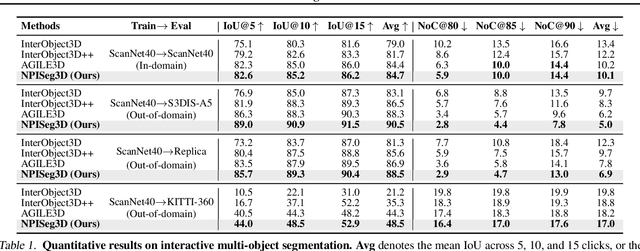
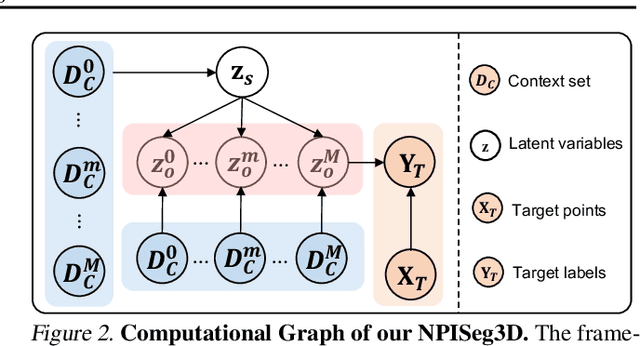
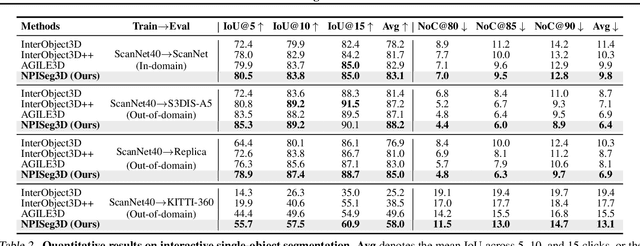
Interactive 3D segmentation has emerged as a promising solution for generating accurate object masks in complex 3D scenes by incorporating user-provided clicks. However, two critical challenges remain underexplored: (1) effectively generalizing from sparse user clicks to produce accurate segmentation, and (2) quantifying predictive uncertainty to help users identify unreliable regions. In this work, we propose NPISeg3D, a novel probabilistic framework that builds upon Neural Processes (NPs) to address these challenges. Specifically, NPISeg3D introduces a hierarchical latent variable structure with scene-specific and object-specific latent variables to enhance few-shot generalization by capturing both global context and object-specific characteristics. Additionally, we design a probabilistic prototype modulator that adaptively modulates click prototypes with object-specific latent variables, improving the model's ability to capture object-aware context and quantify predictive uncertainty. Experiments on four 3D point cloud datasets demonstrate that NPISeg3D achieves superior segmentation performance with fewer clicks while providing reliable uncertainty estimations.
Distributional Vision-Language Alignment by Cauchy-Schwarz Divergence
Feb 24, 2025Multimodal alignment is crucial for various downstream tasks such as cross-modal generation and retrieval. Previous multimodal approaches like CLIP maximize the mutual information mainly by aligning pairwise samples across modalities while overlooking the distributional differences, leading to suboptimal alignment with modality gaps. In this paper, to overcome the limitation, we propose CS-Aligner, a novel and straightforward framework that performs distributional vision-language alignment by integrating Cauchy-Schwarz (CS) divergence with mutual information. In the proposed framework, we find that the CS divergence and mutual information serve complementary roles in multimodal alignment, capturing both the global distribution information of each modality and the pairwise semantic relationships, yielding tighter and more precise alignment. Moreover, CS-Aligher enables incorporating additional information from unpaired data and token-level representations, enhancing flexible and fine-grained alignment in practice. Experiments on text-to-image generation and cross-modality retrieval tasks demonstrate the effectiveness of our method on vision-language alignment.
Geometric Neural Process Fields
Feb 04, 2025This paper addresses the challenge of Neural Field (NeF) generalization, where models must efficiently adapt to new signals given only a few observations. To tackle this, we propose Geometric Neural Process Fields (G-NPF), a probabilistic framework for neural radiance fields that explicitly captures uncertainty. We formulate NeF generalization as a probabilistic problem, enabling direct inference of NeF function distributions from limited context observations. To incorporate structural inductive biases, we introduce a set of geometric bases that encode spatial structure and facilitate the inference of NeF function distributions. Building on these bases, we design a hierarchical latent variable model, allowing G-NPF to integrate structural information across multiple spatial levels and effectively parameterize INR functions. This hierarchical approach improves generalization to novel scenes and unseen signals. Experiments on novel-view synthesis for 3D scenes, as well as 2D image and 1D signal regression, demonstrate the effectiveness of our method in capturing uncertainty and leveraging structural information for improved generalization.
Beyond Any-Shot Adaptation: Predicting Optimization Outcome for Robustness Gains without Extra Pay
Jan 19, 2025



The foundation model enables fast problem-solving without learning from scratch, and such a desirable adaptation property benefits from its adopted cross-task generalization paradigms, e.g., pretraining, meta-training, or finetuning. Recent trends have focused on the curation of task datasets during optimization, which includes task selection as an indispensable consideration for either adaptation robustness or sampling efficiency purposes. Despite some progress, selecting crucial task batches to optimize over iteration mostly exhausts massive task queries and requires intensive evaluation and computations to secure robust adaptation. This work underscores the criticality of both robustness and learning efficiency, especially in scenarios where tasks are risky to collect or costly to evaluate. To this end, we present Model Predictive Task Sampling (MPTS), a novel active task sampling framework to establish connections between the task space and adaptation risk landscape achieve robust adaptation. Technically, MPTS characterizes the task episodic information with a generative model and predicts optimization outcome after adaptation from posterior inference, i.e., forecasting task-specific adaptation risk values. The resulting risk learner amortizes expensive annotation, evaluation, or computation operations in task robust adaptation learning paradigms. Extensive experimental results show that MPTS can be seamlessly integrated into zero-shot, few-shot, and many-shot learning paradigms, increases adaptation robustness, and retains learning efficiency without affording extra cost. The code will be available at the project site https://github.com/thu-rllab/MPTS.
Beyond Model Adaptation at Test Time: A Survey
Nov 06, 2024Machine learning algorithms have achieved remarkable success across various disciplines, use cases and applications, under the prevailing assumption that training and test samples are drawn from the same distribution. Consequently, these algorithms struggle and become brittle even when samples in the test distribution start to deviate from the ones observed during training. Domain adaptation and domain generalization have been studied extensively as approaches to address distribution shifts across test and train domains, but each has its limitations. Test-time adaptation, a recently emerging learning paradigm, combines the benefits of domain adaptation and domain generalization by training models only on source data and adapting them to target data during test-time inference. In this survey, we provide a comprehensive and systematic review on test-time adaptation, covering more than 400 recent papers. We structure our review by categorizing existing methods into five distinct categories based on what component of the method is adjusted for test-time adaptation: the model, the inference, the normalization, the sample, or the prompt, providing detailed analysis of each. We further discuss the various preparation and adaptation settings for methods within these categories, offering deeper insights into the effective deployment for the evaluation of distribution shifts and their real-world application in understanding images, video and 3D, as well as modalities beyond vision. We close the survey with an outlook on emerging research opportunities for test-time adaptation.
Multi-Modal Adapter for Vision-Language Models
Sep 03, 2024



Large pre-trained vision-language models, such as CLIP, have demonstrated state-of-the-art performance across a wide range of image classification tasks, without requiring retraining. Few-shot CLIP is competitive with existing specialized architectures that were trained on the downstream tasks. Recent research demonstrates that the performance of CLIP can be further improved using lightweight adaptation approaches. However, previous methods adapt different modalities of the CLIP model individually, ignoring the interactions and relationships between visual and textual representations. In this work, we propose Multi-Modal Adapter, an approach for Multi-Modal adaptation of CLIP. Specifically, we add a trainable Multi-Head Attention layer that combines text and image features to produce an additive adaptation of both. Multi-Modal Adapter demonstrates improved generalizability, based on its performance on unseen classes compared to existing adaptation methods. We perform additional ablations and investigations to validate and interpret the proposed approach.
GO4Align: Group Optimization for Multi-Task Alignment
Apr 09, 2024



This paper proposes \textit{GO4Align}, a multi-task optimization approach that tackles task imbalance by explicitly aligning the optimization across tasks. To achieve this, we design an adaptive group risk minimization strategy, compromising two crucial techniques in implementation: (i) dynamical group assignment, which clusters similar tasks based on task interactions; (ii) risk-guided group indicators, which exploit consistent task correlations with risk information from previous iterations. Comprehensive experimental results on diverse typical benchmarks demonstrate our method's performance superiority with even lower computational costs.
Any-Shift Prompting for Generalization over Distributions
Feb 15, 2024Image-language models with prompt learning have shown remarkable advances in numerous downstream vision tasks. Nevertheless, conventional prompt learning methods overfit their training distribution and lose the generalization ability on test distributions. To improve generalization across various distribution shifts, we propose any-shift prompting: a general probabilistic inference framework that considers the relationship between training and test distributions during prompt learning. We explicitly connect training and test distributions in the latent space by constructing training and test prompts in a hierarchical architecture. Within this framework, the test prompt exploits the distribution relationships to guide the generalization of the CLIP image-language model from training to any test distribution. To effectively encode the distribution information and their relationships, we further introduce a transformer inference network with a pseudo-shift training mechanism. The network generates the tailored test prompt with both training and test information in a feedforward pass, avoiding extra training costs at test time. Extensive experiments on twenty-three datasets demonstrate the effectiveness of any-shift prompting on the generalization over various distribution shifts.