 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProbabilistic Interactive 3D Segmentation with Hierarchical Neural Processes
May 03, 2025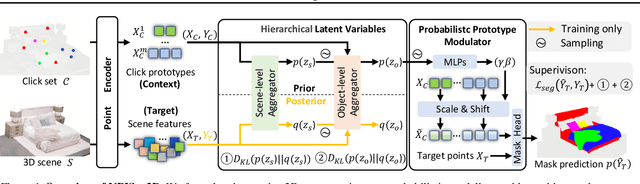
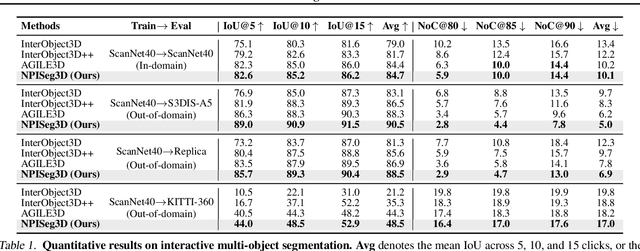
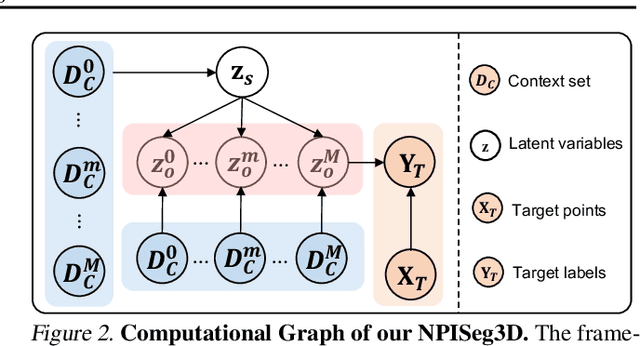
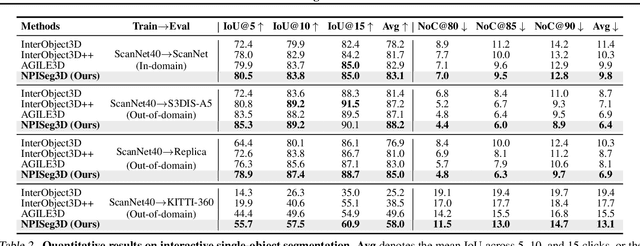
Interactive 3D segmentation has emerged as a promising solution for generating accurate object masks in complex 3D scenes by incorporating user-provided clicks. However, two critical challenges remain underexplored: (1) effectively generalizing from sparse user clicks to produce accurate segmentation, and (2) quantifying predictive uncertainty to help users identify unreliable regions. In this work, we propose NPISeg3D, a novel probabilistic framework that builds upon Neural Processes (NPs) to address these challenges. Specifically, NPISeg3D introduces a hierarchical latent variable structure with scene-specific and object-specific latent variables to enhance few-shot generalization by capturing both global context and object-specific characteristics. Additionally, we design a probabilistic prototype modulator that adaptively modulates click prototypes with object-specific latent variables, improving the model's ability to capture object-aware context and quantify predictive uncertainty. Experiments on four 3D point cloud datasets demonstrate that NPISeg3D achieves superior segmentation performance with fewer clicks while providing reliable uncertainty estimations.
Distributional Vision-Language Alignment by Cauchy-Schwarz Divergence
Feb 24, 2025Multimodal alignment is crucial for various downstream tasks such as cross-modal generation and retrieval. Previous multimodal approaches like CLIP maximize the mutual information mainly by aligning pairwise samples across modalities while overlooking the distributional differences, leading to suboptimal alignment with modality gaps. In this paper, to overcome the limitation, we propose CS-Aligner, a novel and straightforward framework that performs distributional vision-language alignment by integrating Cauchy-Schwarz (CS) divergence with mutual information. In the proposed framework, we find that the CS divergence and mutual information serve complementary roles in multimodal alignment, capturing both the global distribution information of each modality and the pairwise semantic relationships, yielding tighter and more precise alignment. Moreover, CS-Aligher enables incorporating additional information from unpaired data and token-level representations, enhancing flexible and fine-grained alignment in practice. Experiments on text-to-image generation and cross-modality retrieval tasks demonstrate the effectiveness of our method on vision-language alignment.
Geometric Neural Process Fields
Feb 04, 2025This paper addresses the challenge of Neural Field (NeF) generalization, where models must efficiently adapt to new signals given only a few observations. To tackle this, we propose Geometric Neural Process Fields (G-NPF), a probabilistic framework for neural radiance fields that explicitly captures uncertainty. We formulate NeF generalization as a probabilistic problem, enabling direct inference of NeF function distributions from limited context observations. To incorporate structural inductive biases, we introduce a set of geometric bases that encode spatial structure and facilitate the inference of NeF function distributions. Building on these bases, we design a hierarchical latent variable model, allowing G-NPF to integrate structural information across multiple spatial levels and effectively parameterize INR functions. This hierarchical approach improves generalization to novel scenes and unseen signals. Experiments on novel-view synthesis for 3D scenes, as well as 2D image and 1D signal regression, demonstrate the effectiveness of our method in capturing uncertainty and leveraging structural information for improved generalization.
Domain Adaptation with Cauchy-Schwarz Divergence
May 30, 2024



Domain adaptation aims to use training data from one or multiple source domains to learn a hypothesis that can be generalized to a different, but related, target domain. As such, having a reliable measure for evaluating the discrepancy of both marginal and conditional distributions is crucial. We introduce Cauchy-Schwarz (CS) divergence to the problem of unsupervised domain adaptation (UDA). The CS divergence offers a theoretically tighter generalization error bound than the popular Kullback-Leibler divergence. This holds for the general case of supervised learning, including multi-class classification and regression. Furthermore, we illustrate that the CS divergence enables a simple estimator on the discrepancy of both marginal and conditional distributions between source and target domains in the representation space, without requiring any distributional assumptions. We provide multiple examples to illustrate how the CS divergence can be conveniently used in both distance metric- or adversarial training-based UDA frameworks, resulting in compelling performance.
Dynamic Prototype Adaptation with Distillation for Few-shot Point Cloud Segmentation
Jan 29, 2024Few-shot point cloud segmentation seeks to generate per-point masks for previously unseen categories, using only a minimal set of annotated point clouds as reference. Existing prototype-based methods rely on support prototypes to guide the segmentation of query point clouds, but they encounter challenges when significant object variations exist between the support prototypes and query features. In this work, we present dynamic prototype adaptation (DPA), which explicitly learns task-specific prototypes for each query point cloud to tackle the object variation problem. DPA achieves the adaptation through prototype rectification, aligning vanilla prototypes from support with the query feature distribution, and prototype-to-query attention, extracting task-specific context from query point clouds. Furthermore, we introduce a prototype distillation regularization term, enabling knowledge transfer between early-stage prototypes and their deeper counterparts during adaption. By iteratively applying these adaptations, we generate task-specific prototypes for accurate mask predictions on query point clouds. Extensive experiments on two popular benchmarks show that DPA surpasses state-of-the-art methods by a significant margin, e.g., 7.43\% and 6.39\% under the 2-way 1-shot setting on S3DIS and ScanNet, respectively. Code is available at https://github.com/jliu4ai/DPA.
Motion Flow Matching for Human Motion Synthesis and Editing
Dec 14, 2023Human motion synthesis is a fundamental task in computer animation. Recent methods based on diffusion models or GPT structure demonstrate commendable performance but exhibit drawbacks in terms of slow sampling speeds and error accumulation. In this paper, we propose \emph{Motion Flow Matching}, a novel generative model designed for human motion generation featuring efficient sampling and effectiveness in motion editing applications. Our method reduces the sampling complexity from thousand steps in previous diffusion models to just ten steps, while achieving comparable performance in text-to-motion and action-to-motion generation benchmarks. Noticeably, our approach establishes a new state-of-the-art Fr\'echet Inception Distance on the KIT-ML dataset. What is more, we tailor a straightforward motion editing paradigm named \emph{sampling trajectory rewriting} leveraging the ODE-style generative models and apply it to various editing scenarios including motion prediction, motion in-between prediction, motion interpolation, and upper-body editing. Our code will be released.
Principle of Relevant Information for Graph Sparsification
May 31, 2022



Graph sparsification aims to reduce the number of edges of a graph while maintaining its structural properties. In this paper, we propose the first general and effective information-theoretic formulation of graph sparsification, by taking inspiration from the Principle of Relevant Information (PRI). To this end, we extend the PRI from a standard scalar random variable setting to structured data (i.e., graphs). Our Graph-PRI objective is achieved by operating on the graph Laplacian, made possible by expressing the graph Laplacian of a subgraph in terms of a sparse edge selection vector $\mathbf{w}$. We provide both theoretical and empirical justifications on the validity of our Graph-PRI approach. We also analyze its analytical solutions in a few special cases. We finally present three representative real-world applications, namely graph sparsification, graph regularized multi-task learning, and medical imaging-derived brain network classification, to demonstrate the effectiveness, the versatility and the enhanced interpretability of our approach over prevalent sparsification techniques. Code of Graph-PRI is available at https://github.com/SJYuCNEL/PRI-Graphs
Bilevel Continual Learning
Nov 02, 2020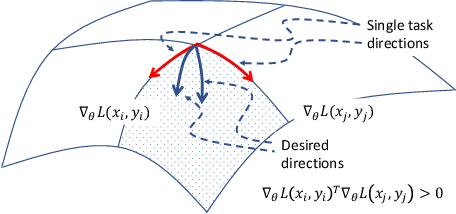
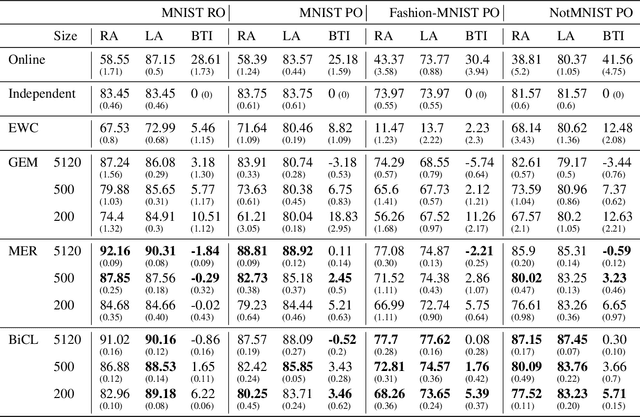
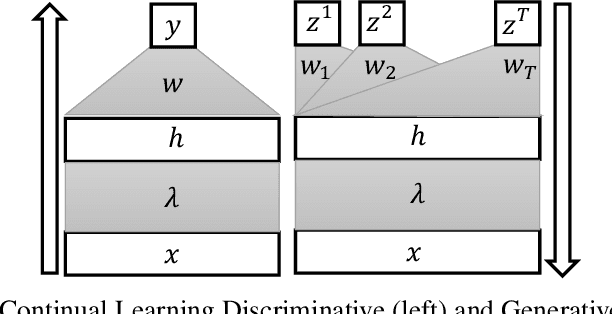

Continual learning (CL) studies the problem of learning a sequence of tasks, one at a time, such that the learning of each new task does not lead to the deterioration in performance on the previously seen ones while exploiting previously learned features. This paper presents Bilevel Continual Learning (BiCL), a general framework for continual learning that fuses bilevel optimization and recent advances in meta-learning for deep neural networks. BiCL is able to train both deep discriminative and generative models under the conservative setting of the online continual learning. Experimental results show that BiCL provides competitive performance in terms of accuracy for the current task while reducing the effect of catastrophic forgetting. This is a concurrent work with [1]. We submitted it to AAAI 2020 and IJCAI 2020. Now we put it on the arxiv for record. Different from [1], we also consider continual generative model as well. At the same time, the authors are aware of a recent proposal on bilevel optimization based coreset construction for continual learning [2]. [1] Q. Pham, D. Sahoo, C. Liu, and S. C. Hoi. Bilevel continual learning. arXiv preprint arXiv:2007.15553, 2020. [2] Z. Borsos, M. Mutny, and A. Krause. Coresets via bilevel optimization for continual learning and streaming. arXiv preprint arXiv:2006.03875, 2020
Learning an Interpretable Graph Structure in Multi-Task Learning
Sep 11, 2020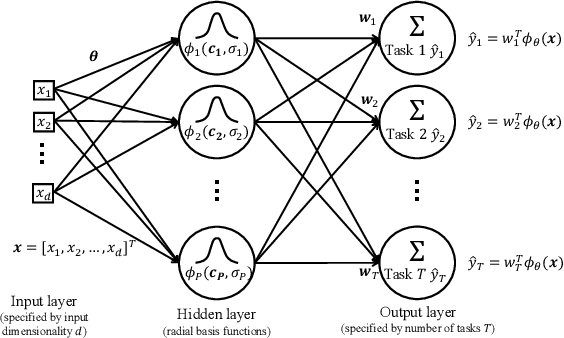
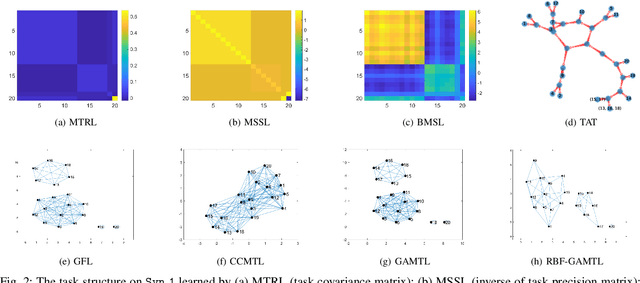
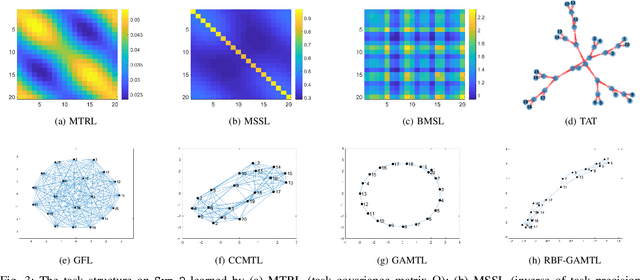
We present a novel methodology to jointly perform multi-task learning and infer intrinsic relationship among tasks by an interpretable and sparse graph. Unlike existing multi-task learning methodologies, the graph structure is not assumed to be known a priori or estimated separately in a preprocessing step. Instead, our graph is learned simultaneously with model parameters of each task, thus it reflects the critical relationship among tasks in the specific prediction problem. We characterize graph structure with its weighted adjacency matrix and show that the overall objective can be optimized alternatively until convergence. We also show that our methodology can be simply extended to a nonlinear form by being embedded into a multi-head radial basis function network (RBFN). Extensive experiments, against six state-of-the-art methodologies, on both synthetic data and real-world applications suggest that our methodology is able to reduce generalization error, and, at the same time, reveal a sparse graph over tasks that is much easier to interpret.
Towards Interpretable Multi-Task Learning Using Bilevel Programming
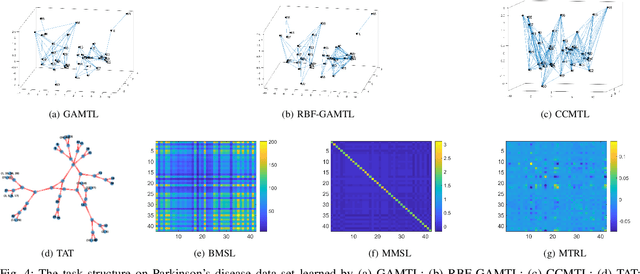
Sep 11, 2020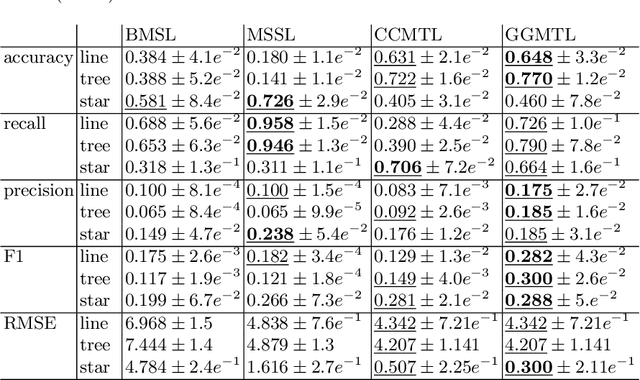



Interpretable Multi-Task Learning can be expressed as learning a sparse graph of the task relationship based on the prediction performance of the learned models. Since many natural phenomenon exhibit sparse structures, enforcing sparsity on learned models reveals the underlying task relationship. Moreover, different sparsification degrees from a fully connected graph uncover various types of structures, like cliques, trees, lines, clusters or fully disconnected graphs. In this paper, we propose a bilevel formulation of multi-task learning that induces sparse graphs, thus, revealing the underlying task relationships, and an efficient method for its computation. We show empirically how the induced sparse graph improves the interpretability of the learned models and their relationship on synthetic and real data, without sacrificing generalization performance. Code at https://bit.ly/GraphGuidedMTL