 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiffusion Models and Representation Learning: A Survey
Jun 30, 2024


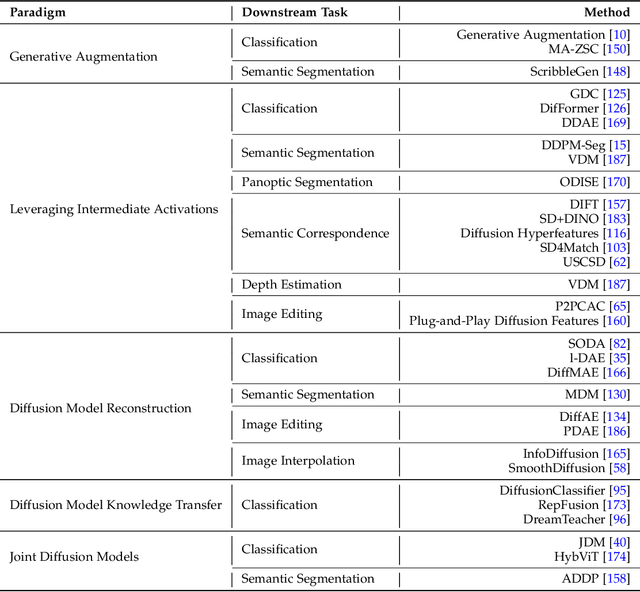
Diffusion Models are popular generative modeling methods in various vision tasks, attracting significant attention. They can be considered a unique instance of self-supervised learning methods due to their independence from label annotation. This survey explores the interplay between diffusion models and representation learning. It provides an overview of diffusion models' essential aspects, including mathematical foundations, popular denoising network architectures, and guidance methods. Various approaches related to diffusion models and representation learning are detailed. These include frameworks that leverage representations learned from pre-trained diffusion models for subsequent recognition tasks and methods that utilize advancements in representation and self-supervised learning to enhance diffusion models. This survey aims to offer a comprehensive overview of the taxonomy between diffusion models and representation learning, identifying key areas of existing concerns and potential exploration. Github link: https://github.com/dongzhuoyao/Diffusion-Representation-Learning-Survey-Taxonomy
ZigMa: Zigzag Mamba Diffusion Model
Mar 20, 2024



The diffusion model has long been plagued by scalability and quadratic complexity issues, especially within transformer-based structures. In this study, we aim to leverage the long sequence modeling capability of a State-Space Model called Mamba to extend its applicability to visual data generation. Firstly, we identify a critical oversight in most current Mamba-based vision methods, namely the lack of consideration for spatial continuity in the scan scheme of Mamba. Secondly, building upon this insight, we introduce a simple, plug-and-play, zero-parameter method named Zigzag Mamba, which outperforms Mamba-based baselines and demonstrates improved speed and memory utilization compared to transformer-based baselines. Lastly, we integrate Zigzag Mamba with the Stochastic Interpolant framework to investigate the scalability of the model on large-resolution visual datasets, such as FacesHQ $1024\times 1024$ and UCF101, MultiModal-CelebA-HQ, and MS COCO $256\times 256$. Code will be released at https://taohu.me/zigma/
Motion Flow Matching for Human Motion Synthesis and Editing
Dec 14, 2023Human motion synthesis is a fundamental task in computer animation. Recent methods based on diffusion models or GPT structure demonstrate commendable performance but exhibit drawbacks in terms of slow sampling speeds and error accumulation. In this paper, we propose \emph{Motion Flow Matching}, a novel generative model designed for human motion generation featuring efficient sampling and effectiveness in motion editing applications. Our method reduces the sampling complexity from thousand steps in previous diffusion models to just ten steps, while achieving comparable performance in text-to-motion and action-to-motion generation benchmarks. Noticeably, our approach establishes a new state-of-the-art Fr\'echet Inception Distance on the KIT-ML dataset. What is more, we tailor a straightforward motion editing paradigm named \emph{sampling trajectory rewriting} leveraging the ODE-style generative models and apply it to various editing scenarios including motion prediction, motion in-between prediction, motion interpolation, and upper-body editing. Our code will be released.
Guided Diffusion from Self-Supervised Diffusion Features
Dec 14, 2023



Guidance serves as a key concept in diffusion models, yet its effectiveness is often limited by the need for extra data annotation or classifier pretraining. That is why guidance was harnessed from self-supervised learning backbones, like DINO. However, recent studies have revealed that the feature representation derived from diffusion model itself is discriminative for numerous downstream tasks as well, which prompts us to propose a framework to extract guidance from, and specifically for, diffusion models. Our research has yielded several significant contributions. Firstly, the guidance signals from diffusion models are on par with those from class-conditioned diffusion models. Secondly, feature regularization, when based on the Sinkhorn-Knopp algorithm, can further enhance feature discriminability in comparison to unconditional diffusion models. Thirdly, we have constructed an online training approach that can concurrently derive guidance from diffusion models for diffusion models. Lastly, we have extended the application of diffusion models along the constant velocity path of ODE to achieve a more favorable balance between sampling steps and fidelity. The performance of our methods has been outstanding, outperforming related baseline comparisons in large-resolution datasets, such as ImageNet256, ImageNet256-100 and LSUN-Churches. Our code will be released.
Shape or Texture: Understanding Discriminative Features in CNNs
Jan 27, 2021
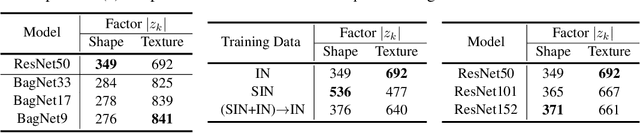

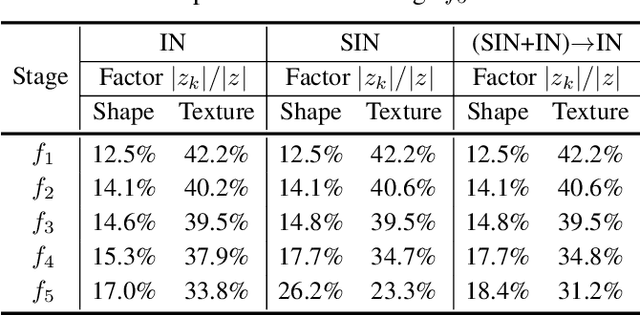
Contrasting the previous evidence that neurons in the later layers of a Convolutional Neural Network (CNN) respond to complex object shapes, recent studies have shown that CNNs actually exhibit a `texture bias': given an image with both texture and shape cues (e.g., a stylized image), a CNN is biased towards predicting the category corresponding to the texture. However, these previous studies conduct experiments on the final classification output of the network, and fail to robustly evaluate the bias contained (i) in the latent representations, and (ii) on a per-pixel level. In this paper, we design a series of experiments that overcome these issues. We do this with the goal of better understanding what type of shape information contained in the network is discriminative, where shape information is encoded, as well as when the network learns about object shape during training. We show that a network learns the majority of overall shape information at the first few epochs of training and that this information is largely encoded in the last few layers of a CNN. Finally, we show that the encoding of shape does not imply the encoding of localized per-pixel semantic information. The experimental results and findings provide a more accurate understanding of the behaviour of current CNNs, thus helping to inform future design choices.
Unsupervised Video Understanding by Reconciliation of Posture Similarities
Aug 03, 2017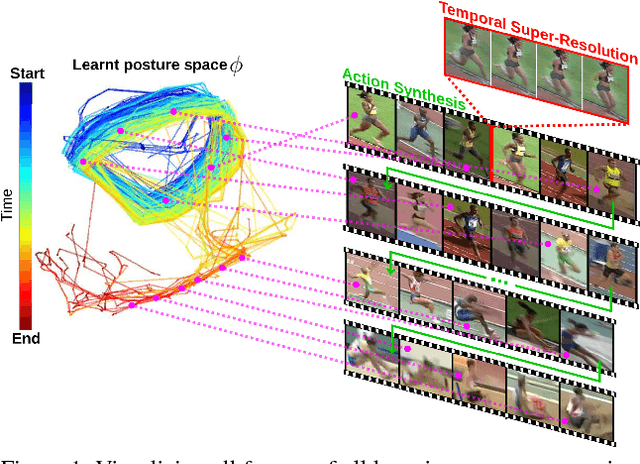
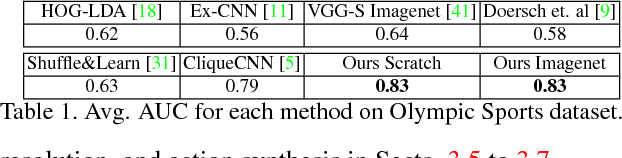

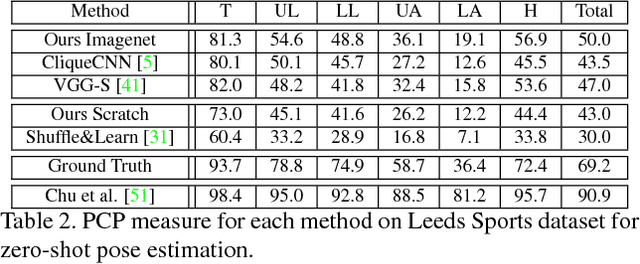
Understanding human activity and being able to explain it in detail surpasses mere action classification by far in both complexity and value. The challenge is thus to describe an activity on the basis of its most fundamental constituents, the individual postures and their distinctive transitions. Supervised learning of such a fine-grained representation based on elementary poses is very tedious and does not scale. Therefore, we propose a completely unsupervised deep learning procedure based solely on video sequences, which starts from scratch without requiring pre-trained networks, predefined body models, or keypoints. A combinatorial sequence matching algorithm proposes relations between frames from subsets of the training data, while a CNN is reconciling the transitivity conflicts of the different subsets to learn a single concerted pose embedding despite changes in appearance across sequences. Without any manual annotation, the model learns a structured representation of postures and their temporal development. The model not only enables retrieval of similar postures but also temporal super-resolution. Additionally, based on a recurrent formulation, next frames can be synthesized.