 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSealD-NeRF: Interactive Pixel-Level Editing for Dynamic Scenes by Neural Radiance Fields
Feb 21, 2024



The widespread adoption of implicit neural representations, especially Neural Radiance Fields (NeRF), highlights a growing need for editing capabilities in implicit 3D models, essential for tasks like scene post-processing and 3D content creation. Despite previous efforts in NeRF editing, challenges remain due to limitations in editing flexibility and quality. The key issue is developing a neural representation that supports local edits for real-time updates. Current NeRF editing methods, offering pixel-level adjustments or detailed geometry and color modifications, are mostly limited to static scenes. This paper introduces SealD-NeRF, an extension of Seal-3D for pixel-level editing in dynamic settings, specifically targeting the D-NeRF network. It allows for consistent edits across sequences by mapping editing actions to a specific timeframe, freezing the deformation network responsible for dynamic scene representation, and using a teacher-student approach to integrate changes.
Shape or Texture: Understanding Discriminative Features in CNNs
Jan 27, 2021
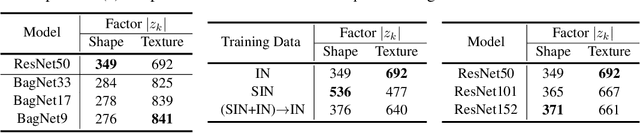

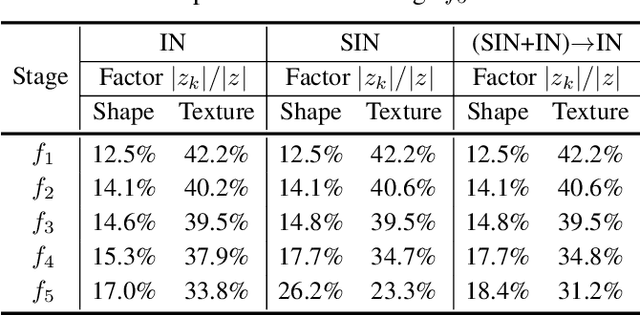
Contrasting the previous evidence that neurons in the later layers of a Convolutional Neural Network (CNN) respond to complex object shapes, recent studies have shown that CNNs actually exhibit a `texture bias': given an image with both texture and shape cues (e.g., a stylized image), a CNN is biased towards predicting the category corresponding to the texture. However, these previous studies conduct experiments on the final classification output of the network, and fail to robustly evaluate the bias contained (i) in the latent representations, and (ii) on a per-pixel level. In this paper, we design a series of experiments that overcome these issues. We do this with the goal of better understanding what type of shape information contained in the network is discriminative, where shape information is encoded, as well as when the network learns about object shape during training. We show that a network learns the majority of overall shape information at the first few epochs of training and that this information is largely encoded in the last few layers of a CNN. Finally, we show that the encoding of shape does not imply the encoding of localized per-pixel semantic information. The experimental results and findings provide a more accurate understanding of the behaviour of current CNNs, thus helping to inform future design choices.
Label Refinement Network for Coarse-to-Fine Semantic Segmentation
Mar 01, 2017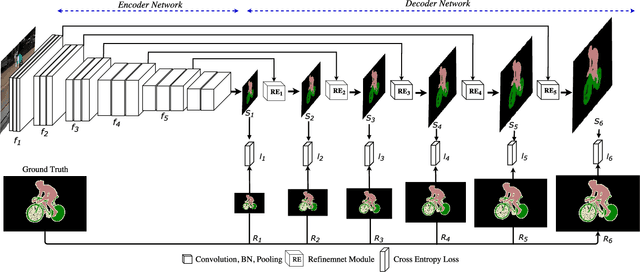


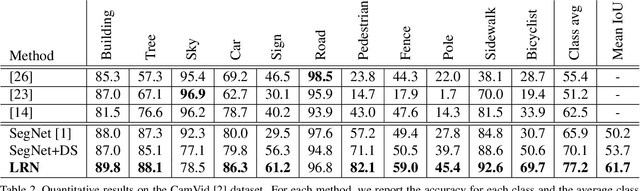
We consider the problem of semantic image segmentation using deep convolutional neural networks. We propose a novel network architecture called the label refinement network that predicts segmentation labels in a coarse-to-fine fashion at several resolutions. The segmentation labels at a coarse resolution are used together with convolutional features to obtain finer resolution segmentation labels. We define loss functions at several stages in the network to provide supervisions at different stages. Our experimental results on several standard datasets demonstrate that the proposed model provides an effective way of producing pixel-wise dense image labeling.