 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSUIT: Spatial-Spectral Union-Intersection Interaction Network for Hyperspectral Object Tracking
Aug 10, 2025Hyperspectral videos (HSVs), with their inherent spatial-spectral-temporal structure, offer distinct advantages in challenging tracking scenarios such as cluttered backgrounds and small objects. However, existing methods primarily focus on spatial interactions between the template and search regions, often overlooking spectral interactions, leading to suboptimal performance. To address this issue, this paper investigates spectral interactions from both the architectural and training perspectives. At the architectural level, we first establish band-wise long-range spatial relationships between the template and search regions using Transformers. We then model spectral interactions using the inclusion-exclusion principle from set theory, treating them as the union of spatial interactions across all bands. This enables the effective integration of both shared and band-specific spatial cues. At the training level, we introduce a spectral loss to enforce material distribution alignment between the template and predicted regions, enhancing robustness to shape deformation and appearance variations. Extensive experiments demonstrate that our tracker achieves state-of-the-art tracking performance. The source code, trained models and results will be publicly available via https://github.com/bearshng/suit to support reproducibility.
COEF-VQ: Cost-Efficient Video Quality Understanding through a Cascaded Multimodal LLM Framework
Dec 11, 2024



Recently, with the emergence of recent Multimodal Large Language Model (MLLM) technology, it has become possible to exploit its video understanding capability on different classification tasks. In practice, we face the difficulty of huge requirements for GPU resource if we need to deploy MLLMs online. In this paper, we propose COEF-VQ, a novel cascaded MLLM framework for better video quality understanding on TikTok. To this end, we first propose a MLLM fusing all visual, textual and audio signals, and then develop a cascade framework with a lightweight model as pre-filtering stage and MLLM as fine-consideration stage, significantly reducing the need for GPU resource, while retaining the performance demonstrated solely by MLLM. To demonstrate the effectiveness of COEF-VQ, we deployed this new framework onto the video management platform (VMP) at TikTok, and performed a series of detailed experiments on two in-house tasks related to video quality understanding. We show that COEF-VQ leads to substantial performance gains with limit resource consumption in these two tasks.
Diff5T: Benchmarking Human Brain Diffusion MRI with an Extensive 5.0 Tesla K-Space and Spatial Dataset
Dec 09, 2024

Diffusion magnetic resonance imaging (dMRI) provides critical insights into the microstructural and connectional organization of the human brain. However, the availability of high-field, open-access datasets that include raw k-space data for advanced research remains limited. To address this gap, we introduce Diff5T, a first comprehensive 5.0 Tesla diffusion MRI dataset focusing on the human brain. This dataset includes raw k-space data and reconstructed diffusion images, acquired using a variety of imaging protocols. Diff5T is designed to support the development and benchmarking of innovative methods in artifact correction, image reconstruction, image preprocessing, diffusion modelling and tractography. The dataset features a wide range of diffusion parameters, including multiple b-values and gradient directions, allowing extensive research applications in studying human brain microstructure and connectivity. With its emphasis on open accessibility and detailed benchmarks, Diff5T serves as a valuable resource for advancing human brain mapping research using diffusion MRI, fostering reproducibility, and enabling collaboration across the neuroscience and medical imaging communities.
LaVIDE: A Language-Vision Discriminator for Detecting Changes in Satellite Image with Map References
Nov 29, 2024Change detection, which typically relies on the comparison of bi-temporal images, is significantly hindered when only a single image is available. Comparing a single image with an existing map, such as OpenStreetMap, which is continuously updated through crowd-sourcing, offers a viable solution to this challenge. Unlike images that carry low-level visual details of ground objects, maps convey high-level categorical information. This discrepancy in abstraction levels complicates the alignment and comparison of the two data types. In this paper, we propose a \textbf{La}nguage-\textbf{VI}sion \textbf{D}iscriminator for d\textbf{E}tecting changes in satellite image with map references, namely \ours{}, which leverages language to bridge the information gap between maps and images. Specifically, \ours{} formulates change detection as the problem of ``{\textit Does the pixel belong to [class]?}'', aligning maps and images within the feature space of the language-vision model to associate high-level map categories with low-level image details. Moreover, we build a mixture-of-experts discriminative module, which compares linguistic features from maps with visual features from images across various semantic perspectives, achieving comprehensive semantic comparison for change detection. Extensive evaluation on four benchmark datasets demonstrates that \ours{} can effectively detect changes in satellite image with map references, outperforming state-of-the-art change detection algorithms, e.g., with gains of about $13.8$\% on the DynamicEarthNet dataset and $4.3$\% on the SECOND dataset.
Graph Canvas for Controllable 3D Scene Generation
Nov 27, 2024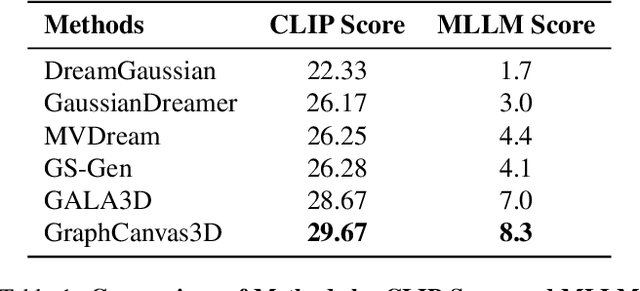
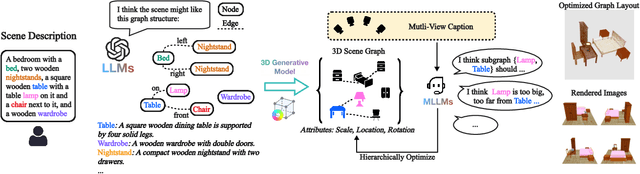
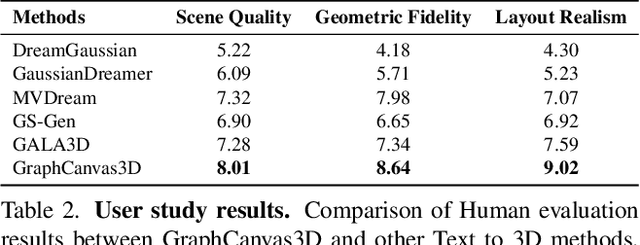
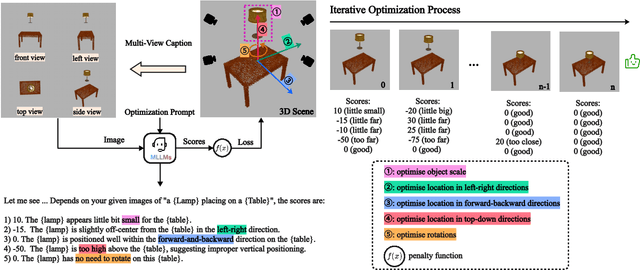
Spatial intelligence is foundational to AI systems that interact with the physical world, particularly in 3D scene generation and spatial comprehension. Current methodologies for 3D scene generation often rely heavily on predefined datasets, and struggle to adapt dynamically to changing spatial relationships. In this paper, we introduce \textbf{GraphCanvas3D}, a programmable, extensible, and adaptable framework for controllable 3D scene generation. Leveraging in-context learning, GraphCanvas3D enables dynamic adaptability without the need for retraining, supporting flexible and customizable scene creation. Our framework employs hierarchical, graph-driven scene descriptions, representing spatial elements as graph nodes and establishing coherent relationships among objects in 3D environments. Unlike conventional approaches, which are constrained in adaptability and often require predefined input masks or retraining for modifications, GraphCanvas3D allows for seamless object manipulation and scene adjustments on the fly. Additionally, GraphCanvas3D supports 4D scene generation, incorporating temporal dynamics to model changes over time. Experimental results and user studies demonstrate that GraphCanvas3D enhances usability, flexibility, and adaptability for scene generation. Our code and models are available on the project website: https://github.com/ILGLJ/Graph-Canvas.
Human Motion Instruction Tuning
Nov 25, 2024



This paper presents LLaMo (Large Language and Human Motion Assistant), a multimodal framework for human motion instruction tuning. In contrast to conventional instruction-tuning approaches that convert non-linguistic inputs, such as video or motion sequences, into language tokens, LLaMo retains motion in its native form for instruction tuning. This method preserves motion-specific details that are often diminished in tokenization, thereby improving the model's ability to interpret complex human behaviors. By processing both video and motion data alongside textual inputs, LLaMo enables a flexible, human-centric analysis. Experimental evaluations across high-complexity domains, including human behaviors and professional activities, indicate that LLaMo effectively captures domain-specific knowledge, enhancing comprehension and prediction in motion-intensive scenarios. We hope LLaMo offers a foundation for future multimodal AI systems with broad applications, from sports analytics to behavioral prediction. Our code and models are available on the project website: https://github.com/ILGLJ/LLaMo.
Adaptive Masking Enhances Visual Grounding
Oct 04, 2024



In recent years, zero-shot and few-shot learning in visual grounding have garnered considerable attention, largely due to the success of large-scale vision-language pre-training on expansive datasets such as LAION-5B and DataComp-1B. However, the continuous expansion of these datasets presents significant challenges, particularly with respect to data availability and computational overhead, thus creating a bottleneck in the advancement of low-shot learning capabilities. In this paper, we propose IMAGE, Interpretative MAsking with Gaussian radiation modEling, aimed at enhancing vocabulary grounding in low-shot learning scenarios without necessitating an increase in dataset size. Drawing inspiration from cognitive science and the recent success of masked autoencoders (MAE), our method leverages adaptive masking on salient regions of the feature maps generated by the vision backbone. This enables the model to learn robust, generalized representations through the reconstruction of occluded information, thereby facilitating effective attention to both local and global features. We evaluate the efficacy of our approach on benchmark datasets, including COCO and ODinW, demonstrating its superior performance in zero-shot and few-shot tasks. Experimental results consistently show that IMAGE outperforms baseline models, achieving enhanced generalization and improved performance in low-shot scenarios. These findings highlight the potential of adaptive feature manipulation through attention mechanisms and Gaussian modeling as a promising alternative to approaches that rely on the continual scaling of dataset sizes for the advancement of zero-shot and few-shot learning. Our code is publicly available at https://github.com/git-lenny/IMAGE.
MR Optimized Reconstruction of Simultaneous Multi-Slice Imaging Using Diffusion Model
Aug 21, 2024Diffusion model has been successfully applied to MRI reconstruction, including single and multi-coil acquisition of MRI data. Simultaneous multi-slice imaging (SMS), as a method for accelerating MR acquisition, can significantly reduce scanning time, but further optimization of reconstruction results is still possible. In order to optimize the reconstruction of SMS, we proposed a method to use diffusion model based on slice-GRAPPA and SPIRiT method. approach: Specifically, our method characterizes the prior distribution of SMS data by score matching and characterizes the k-space redundant prior between coils and slices based on self-consistency. With the utilization of diffusion model, we achieved better reconstruction results.The application of diffusion model can further reduce the scanning time of MRI without compromising image quality, making it more advantageous for clinical application
* Accepted as ISMRM 2024 Digital Poster 4024
Technique Report of CVPR 2024 PBDL Challenges
Jun 15, 2024



The intersection of physics-based vision and deep learning presents an exciting frontier for advancing computer vision technologies. By leveraging the principles of physics to inform and enhance deep learning models, we can develop more robust and accurate vision systems. Physics-based vision aims to invert the processes to recover scene properties such as shape, reflectance, light distribution, and medium properties from images. In recent years, deep learning has shown promising improvements for various vision tasks, and when combined with physics-based vision, these approaches can enhance the robustness and accuracy of vision systems. This technical report summarizes the outcomes of the Physics-Based Vision Meets Deep Learning (PBDL) 2024 challenge, held in CVPR 2024 workshop. The challenge consisted of eight tracks, focusing on Low-Light Enhancement and Detection as well as High Dynamic Range (HDR) Imaging. This report details the objectives, methodologies, and results of each track, highlighting the top-performing solutions and their innovative approaches.
Knowledge-driven deep learning for fast MR imaging: undersampled MR image reconstruction from supervised to un-supervised learning
Feb 05, 2024Deep learning (DL) has emerged as a leading approach in accelerating MR imaging. It employs deep neural networks to extract knowledge from available datasets and then applies the trained networks to reconstruct accurate images from limited measurements. Unlike natural image restoration problems, MR imaging involves physics-based imaging processes, unique data properties, and diverse imaging tasks. This domain knowledge needs to be integrated with data-driven approaches. Our review will introduce the significant challenges faced by such knowledge-driven DL approaches in the context of fast MR imaging along with several notable solutions, which include learning neural networks and addressing different imaging application scenarios. The traits and trends of these techniques have also been given which have shifted from supervised learning to semi-supervised learning, and finally, to unsupervised learning methods. In addition, MR vendors' choices of DL reconstruction have been provided along with some discussions on open questions and future directions, which are critical for the reliable imaging systems.