 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLaVIDE: A Language-Vision Discriminator for Detecting Changes in Satellite Image with Map References
Nov 29, 2024Change detection, which typically relies on the comparison of bi-temporal images, is significantly hindered when only a single image is available. Comparing a single image with an existing map, such as OpenStreetMap, which is continuously updated through crowd-sourcing, offers a viable solution to this challenge. Unlike images that carry low-level visual details of ground objects, maps convey high-level categorical information. This discrepancy in abstraction levels complicates the alignment and comparison of the two data types. In this paper, we propose a \textbf{La}nguage-\textbf{VI}sion \textbf{D}iscriminator for d\textbf{E}tecting changes in satellite image with map references, namely \ours{}, which leverages language to bridge the information gap between maps and images. Specifically, \ours{} formulates change detection as the problem of ``{\textit Does the pixel belong to [class]?}'', aligning maps and images within the feature space of the language-vision model to associate high-level map categories with low-level image details. Moreover, we build a mixture-of-experts discriminative module, which compares linguistic features from maps with visual features from images across various semantic perspectives, achieving comprehensive semantic comparison for change detection. Extensive evaluation on four benchmark datasets demonstrates that \ours{} can effectively detect changes in satellite image with map references, outperforming state-of-the-art change detection algorithms, e.g., with gains of about $13.8$\% on the DynamicEarthNet dataset and $4.3$\% on the SECOND dataset.
Exploring Scene Coherence for Semi-Supervised 3D Semantic Segmentation
Aug 21, 2024



Semi-supervised semantic segmentation, which efficiently addresses the limitation of acquiring dense annotations, is essential for 3D scene understanding. Most methods leverage the teacher model to generate pseudo labels, and then guide the learning of the student model on unlabeled scenes. However, they focus only on points with pseudo labels while directly overlooking points without pseudo labels, namely intra-scene inconsistency, leading to semantic ambiguity. Moreover, inter-scene correlation between labeled and unlabeled scenes contribute to transferring rich annotation information, yet this has not been explored for the semi-supervised tasks. To address these two problems, we propose to explore scene coherence for semi-supervised 3D semantic segmentation, dubbed CoScene. Inspired by the unstructured and unordered nature of the point clouds, our CoScene adopts the straightforward point erasure strategy to ensure the intra-scene consistency. Moreover, patch-based data augmentation is proposed to enhance the inter-scene information transfer between labeled and unlabeled scenes at both scene and instance levels. Extensive experimental results on SemanticKITTI and nuScenes show that our approach outperforms existing methods.
DMTG: One-Shot Differentiable Multi-Task Grouping
Jul 06, 2024We aim to address Multi-Task Learning (MTL) with a large number of tasks by Multi-Task Grouping (MTG). Given N tasks, we propose to simultaneously identify the best task groups from 2^N candidates and train the model weights simultaneously in one-shot, with the high-order task-affinity fully exploited. This is distinct from the pioneering methods which sequentially identify the groups and train the model weights, where the group identification often relies on heuristics. As a result, our method not only improves the training efficiency, but also mitigates the objective bias introduced by the sequential procedures that potentially lead to a suboptimal solution. Specifically, we formulate MTG as a fully differentiable pruning problem on an adaptive network architecture determined by an underlying Categorical distribution. To categorize N tasks into K groups (represented by K encoder branches), we initially set up KN task heads, where each branch connects to all N task heads to exploit the high-order task-affinity. Then, we gradually prune the KN heads down to N by learning a relaxed differentiable Categorical distribution, ensuring that each task is exclusively and uniquely categorized into only one branch. Extensive experiments on CelebA and Taskonomy datasets with detailed ablations show the promising performance and efficiency of our method. The codes are available at https://github.com/ethanygao/DMTG.
* Accepted to ICML 2024
A Survey: Deep Learning for Hyperspectral Image Classification with Few Labeled Samples
Dec 03, 2021

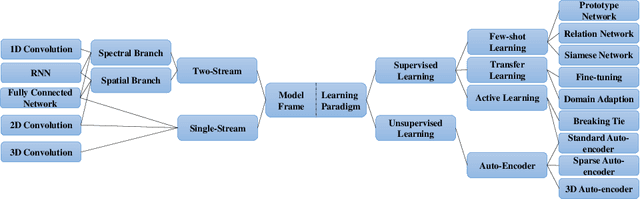
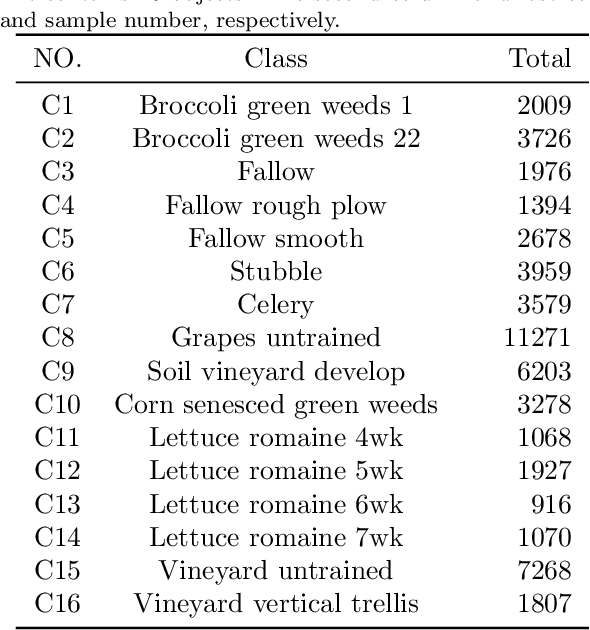
With the rapid development of deep learning technology and improvement in computing capability, deep learning has been widely used in the field of hyperspectral image (HSI) classification. In general, deep learning models often contain many trainable parameters and require a massive number of labeled samples to achieve optimal performance. However, in regard to HSI classification, a large number of labeled samples is generally difficult to acquire due to the difficulty and time-consuming nature of manual labeling. Therefore, many research works focus on building a deep learning model for HSI classification with few labeled samples. In this article, we concentrate on this topic and provide a systematic review of the relevant literature. Specifically, the contributions of this paper are twofold. First, the research progress of related methods is categorized according to the learning paradigm, including transfer learning, active learning and few-shot learning. Second, a number of experiments with various state-of-the-art approaches has been carried out, and the results are summarized to reveal the potential research directions. More importantly, it is notable that although there is a vast gap between deep learning models (that usually need sufficient labeled samples) and the HSI scenario with few labeled samples, the issues of small-sample sets can be well characterized by fusion of deep learning methods and related techniques, such as transfer learning and a lightweight model. For reproducibility, the source codes of the methods assessed in the paper can be found at https://github.com/ShuGuoJ/HSI-Classification.git.