 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntensity Field Decomposition for Tissue-Guided Neural Tomography
Nov 01, 2024Cone-beam computed tomography (CBCT) typically requires hundreds of X-ray projections, which raises concerns about radiation exposure. While sparse-view reconstruction reduces the exposure by using fewer projections, it struggles to achieve satisfactory image quality. To address this challenge, this article introduces a novel sparse-view CBCT reconstruction method, which empowers the neural field with human tissue regularization. Our approach, termed tissue-guided neural tomography (TNT), is motivated by the distinct intensity differences between bone and soft tissue in CBCT. Intuitively, separating these components may aid the learning process of the neural field. More precisely, TNT comprises a heterogeneous quadruple network and the corresponding training strategy. The network represents the intensity field as a combination of soft and hard tissue components, along with their respective textures. We train the network with guidance from estimated tissue projections, enabling efficient learning of the desired patterns for the network heads. Extensive experiments demonstrate that the proposed method significantly improves the sparse-view CBCT reconstruction with a limited number of projections ranging from 10 to 60. Our method achieves comparable reconstruction quality with fewer projections and faster convergence compared to state-of-the-art neural rendering based methods.
DMTG: One-Shot Differentiable Multi-Task Grouping
Jul 06, 2024We aim to address Multi-Task Learning (MTL) with a large number of tasks by Multi-Task Grouping (MTG). Given N tasks, we propose to simultaneously identify the best task groups from 2^N candidates and train the model weights simultaneously in one-shot, with the high-order task-affinity fully exploited. This is distinct from the pioneering methods which sequentially identify the groups and train the model weights, where the group identification often relies on heuristics. As a result, our method not only improves the training efficiency, but also mitigates the objective bias introduced by the sequential procedures that potentially lead to a suboptimal solution. Specifically, we formulate MTG as a fully differentiable pruning problem on an adaptive network architecture determined by an underlying Categorical distribution. To categorize N tasks into K groups (represented by K encoder branches), we initially set up KN task heads, where each branch connects to all N task heads to exploit the high-order task-affinity. Then, we gradually prune the KN heads down to N by learning a relaxed differentiable Categorical distribution, ensuring that each task is exclusively and uniquely categorized into only one branch. Extensive experiments on CelebA and Taskonomy datasets with detailed ablations show the promising performance and efficiency of our method. The codes are available at https://github.com/ethanygao/DMTG.
* Accepted to ICML 2024
Aux-NAS: Exploiting Auxiliary Labels with Negligibly Extra Inference Cost
May 09, 2024

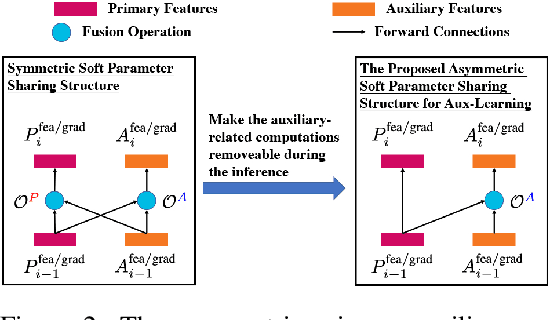

We aim at exploiting additional auxiliary labels from an independent (auxiliary) task to boost the primary task performance which we focus on, while preserving a single task inference cost of the primary task. While most existing auxiliary learning methods are optimization-based relying on loss weights/gradients manipulation, our method is architecture-based with a flexible asymmetric structure for the primary and auxiliary tasks, which produces different networks for training and inference. Specifically, starting from two single task networks/branches (each representing a task), we propose a novel method with evolving networks where only primary-to-auxiliary links exist as the cross-task connections after convergence. These connections can be removed during the primary task inference, resulting in a single-task inference cost. We achieve this by formulating a Neural Architecture Search (NAS) problem, where we initialize bi-directional connections in the search space and guide the NAS optimization converging to an architecture with only the single-side primary-to-auxiliary connections. Moreover, our method can be incorporated with optimization-based auxiliary learning approaches. Extensive experiments with six tasks on NYU v2, CityScapes, and Taskonomy datasets using VGG, ResNet, and ViT backbones validate the promising performance. The codes are available at https://github.com/ethanygao/Aux-NAS.
* Accepted to ICLR 2024
Few-Shot Learning for Annotation-Efficient Nucleus Instance Segmentation
Feb 28, 2024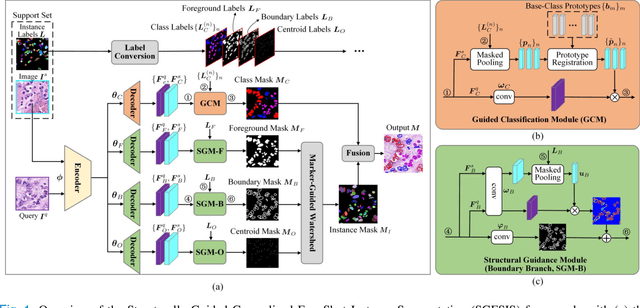
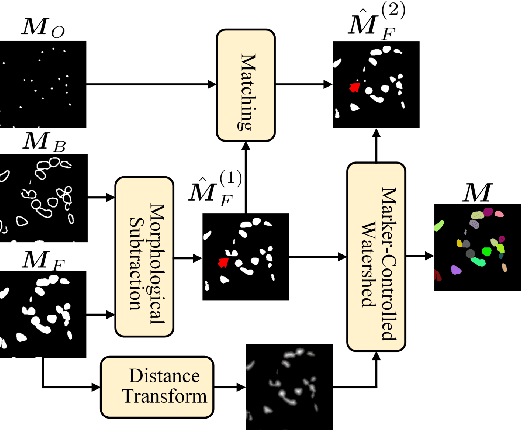
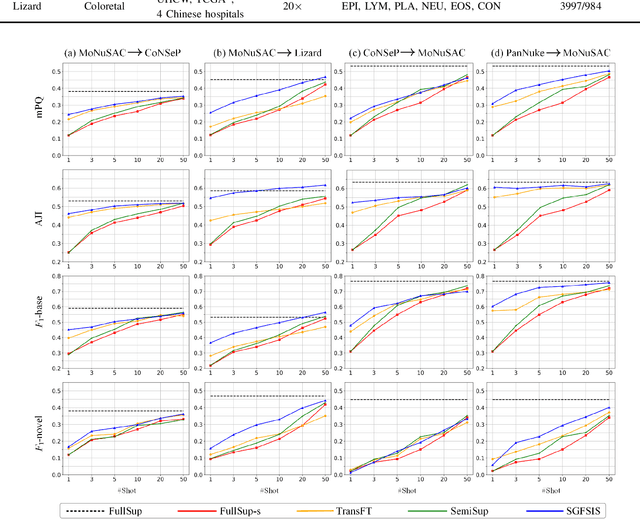
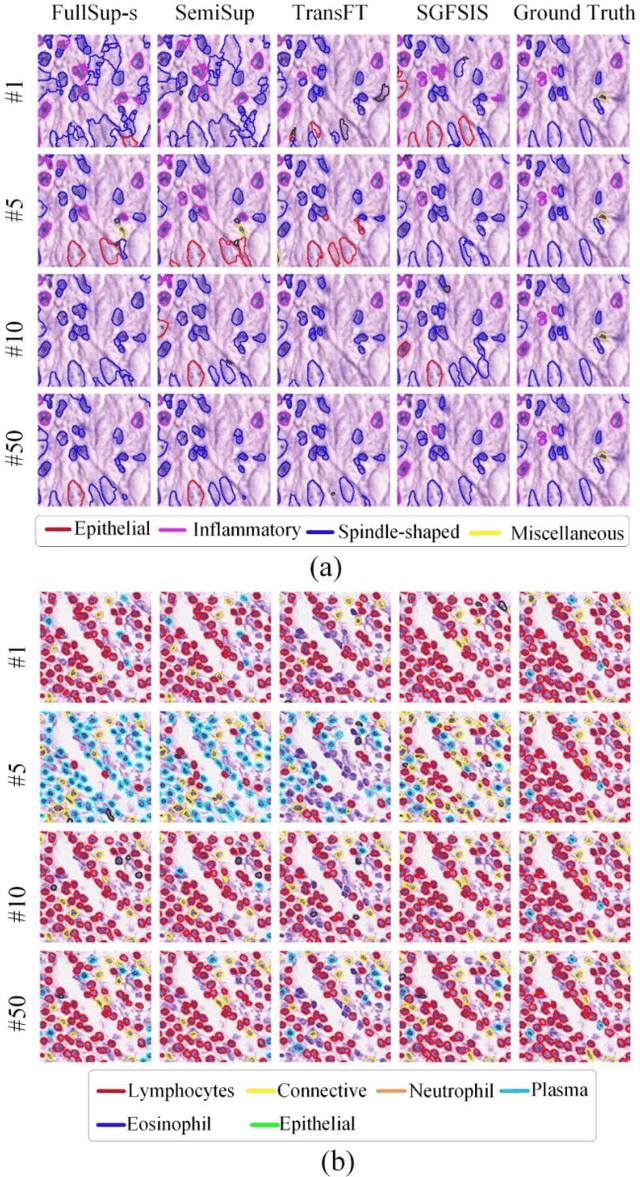
Nucleus instance segmentation from histopathology images suffers from the extremely laborious and expert-dependent annotation of nucleus instances. As a promising solution to this task, annotation-efficient deep learning paradigms have recently attracted much research interest, such as weakly-/semi-supervised learning, generative adversarial learning, etc. In this paper, we propose to formulate annotation-efficient nucleus instance segmentation from the perspective of few-shot learning (FSL). Our work was motivated by that, with the prosperity of computational pathology, an increasing number of fully-annotated datasets are publicly accessible, and we hope to leverage these external datasets to assist nucleus instance segmentation on the target dataset which only has very limited annotation. To achieve this goal, we adopt the meta-learning based FSL paradigm, which however has to be tailored in two substantial aspects before adapting to our task. First, since the novel classes may be inconsistent with those of the external dataset, we extend the basic definition of few-shot instance segmentation (FSIS) to generalized few-shot instance segmentation (GFSIS). Second, to cope with the intrinsic challenges of nucleus segmentation, including touching between adjacent cells, cellular heterogeneity, etc., we further introduce a structural guidance mechanism into the GFSIS network, finally leading to a unified Structurally-Guided Generalized Few-Shot Instance Segmentation (SGFSIS) framework. Extensive experiments on a couple of publicly accessible datasets demonstrate that, SGFSIS can outperform other annotation-efficient learning baselines, including semi-supervised learning, simple transfer learning, etc., with comparable performance to fully supervised learning with less than 5% annotations.
Complete Instances Mining for Weakly Supervised Instance Segmentation
Feb 12, 2024



Weakly supervised instance segmentation (WSIS) using only image-level labels is a challenging task due to the difficulty of aligning coarse annotations with the finer task. However, with the advancement of deep neural networks (DNNs), WSIS has garnered significant attention. Following a proposal-based paradigm, we encounter a redundant segmentation problem resulting from a single instance being represented by multiple proposals. For example, we feed a picture of a dog and proposals into the network and expect to output only one proposal containing a dog, but the network outputs multiple proposals. To address this problem, we propose a novel approach for WSIS that focuses on the online refinement of complete instances through the use of MaskIoU heads to predict the integrity scores of proposals and a Complete Instances Mining (CIM) strategy to explicitly model the redundant segmentation problem and generate refined pseudo labels. Our approach allows the network to become aware of multiple instances and complete instances, and we further improve its robustness through the incorporation of an Anti-noise strategy. Empirical evaluations on the PASCAL VOC 2012 and MS COCO datasets demonstrate that our method achieves state-of-the-art performance with a notable margin. Our implementation will be made available at https://github.com/ZechengLi19/CIM.
* 7 pages
Learning to Holistically Detect Bridges from Large-Size VHR Remote Sensing Imagery
Dec 05, 2023



Bridge detection in remote sensing images (RSIs) plays a crucial role in various applications, but it poses unique challenges compared to the detection of other objects. In RSIs, bridges exhibit considerable variations in terms of their spatial scales and aspect ratios. Therefore, to ensure the visibility and integrity of bridges, it is essential to perform holistic bridge detection in large-size very-high-resolution (VHR) RSIs. However, the lack of datasets with large-size VHR RSIs limits the deep learning algorithms' performance on bridge detection. Due to the limitation of GPU memory in tackling large-size images, deep learning-based object detection methods commonly adopt the cropping strategy, which inevitably results in label fragmentation and discontinuous prediction. To ameliorate the scarcity of datasets, this paper proposes a large-scale dataset named GLH-Bridge comprising 6,000 VHR RSIs sampled from diverse geographic locations across the globe. These images encompass a wide range of sizes, varying from 2,048*2,048 to 16,38*16,384 pixels, and collectively feature 59,737 bridges. Furthermore, we present an efficient network for holistic bridge detection (HBD-Net) in large-size RSIs. The HBD-Net presents a separate detector-based feature fusion (SDFF) architecture and is optimized via a shape-sensitive sample re-weighting (SSRW) strategy. Based on the proposed GLH-Bridge dataset, we establish a bridge detection benchmark including the OBB and HBB tasks, and validate the effectiveness of the proposed HBD-Net. Additionally, cross-dataset generalization experiments on two publicly available datasets illustrate the strong generalization capability of the GLH-Bridge dataset.
Context-Aware Selective Label Smoothing for Calibrating Sequence Recognition Model
Mar 13, 2023Despite the success of deep neural network (DNN) on sequential data (i.e., scene text and speech) recognition, it suffers from the over-confidence problem mainly due to overfitting in training with the cross-entropy loss, which may make the decision-making less reliable. Confidence calibration has been recently proposed as one effective solution to this problem. Nevertheless, the majority of existing confidence calibration methods aims at non-sequential data, which is limited if directly applied to sequential data since the intrinsic contextual dependency in sequences or the class-specific statistical prior is seldom exploited. To the end, we propose a Context-Aware Selective Label Smoothing (CASLS) method for calibrating sequential data. The proposed CASLS fully leverages the contextual dependency in sequences to construct confusion matrices of contextual prediction statistics over different classes. Class-specific error rates are then used to adjust the weights of smoothing strength in order to achieve adaptive calibration. Experimental results on sequence recognition tasks, including scene text recognition and speech recognition, demonstrate that our method can achieve the state-of-the-art performance.
Deep Graph Matching under Quadratic Constraint
Mar 14, 2021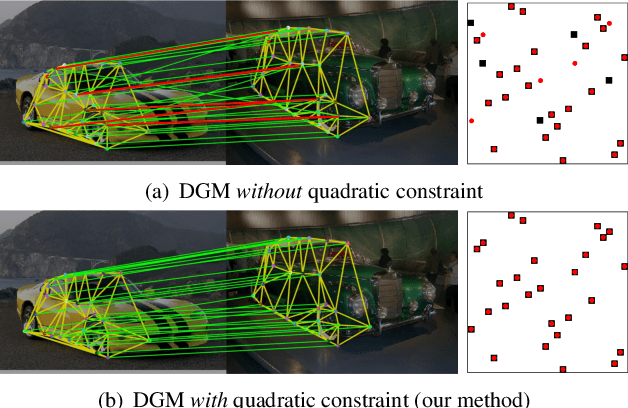
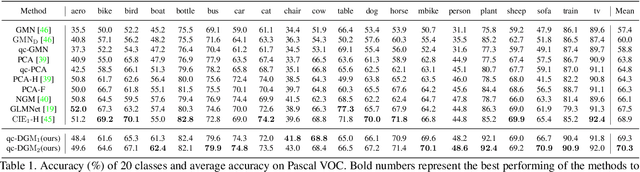
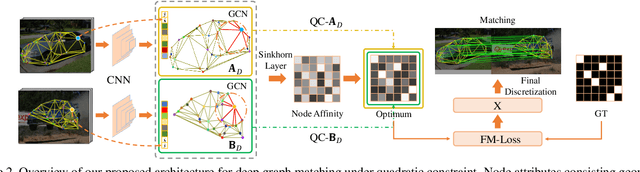

Recently, deep learning based methods have demonstrated promising results on the graph matching problem, by relying on the descriptive capability of deep features extracted on graph nodes. However, one main limitation with existing deep graph matching (DGM) methods lies in their ignorance of explicit constraint of graph structures, which may lead the model to be trapped into local minimum in training. In this paper, we propose to explicitly formulate pairwise graph structures as a \textbf{quadratic constraint} incorporated into the DGM framework. The quadratic constraint minimizes the pairwise structural discrepancy between graphs, which can reduce the ambiguities brought by only using the extracted CNN features. Moreover, we present a differentiable implementation to the quadratic constrained-optimization such that it is compatible with the unconstrained deep learning optimizer. To give more precise and proper supervision, a well-designed false matching loss against class imbalance is proposed, which can better penalize the false negatives and false positives with less overfitting. Exhaustive experiments demonstrate that our method competitive performance on real-world datasets.
FGN: Fully Guided Network for Few-Shot Instance Segmentation
Mar 31, 2020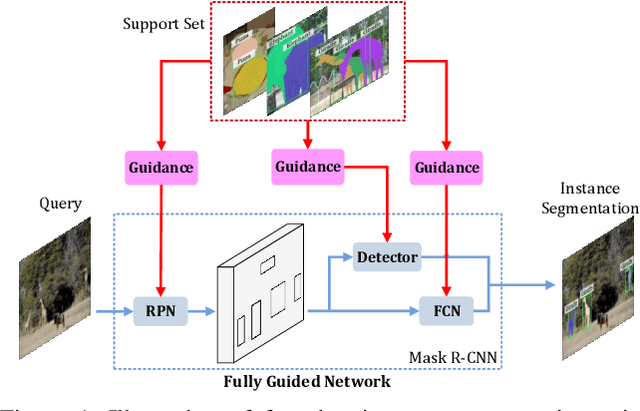

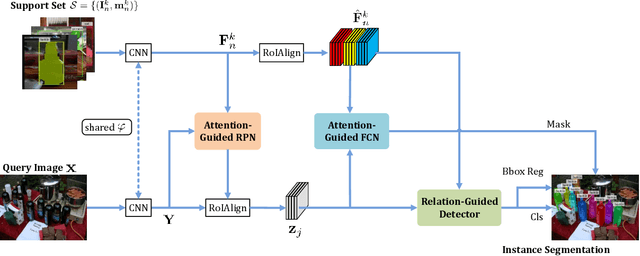
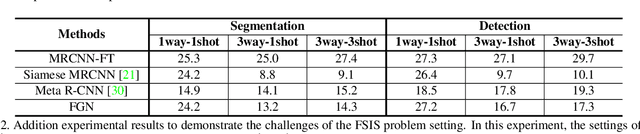
Few-shot instance segmentation (FSIS) conjoins the few-shot learning paradigm with general instance segmentation, which provides a possible way of tackling instance segmentation in the lack of abundant labeled data for training. This paper presents a Fully Guided Network (FGN) for few-shot instance segmentation. FGN perceives FSIS as a guided model where a so-called support set is encoded and utilized to guide the predictions of a base instance segmentation network (i.e., Mask R-CNN), critical to which is the guidance mechanism. In this view, FGN introduces different guidance mechanisms into the various key components in Mask R-CNN, including Attention-Guided RPN, Relation-Guided Detector, and Attention-Guided FCN, in order to make full use of the guidance effect from the support set and adapt better to the inter-class generalization. Experiments on public datasets demonstrate that our proposed FGN can outperform the state-of-the-art methods.
Zero-Assignment Constraint for Graph Matching with Outliers
Mar 26, 2020
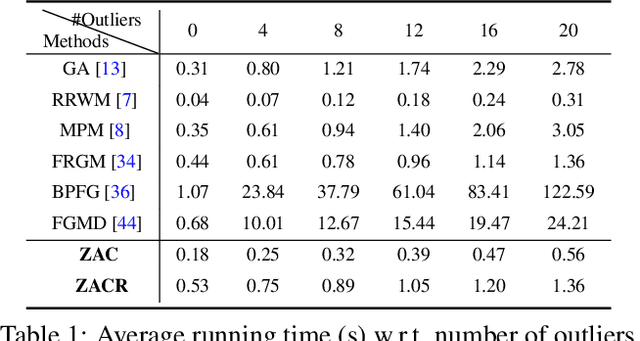

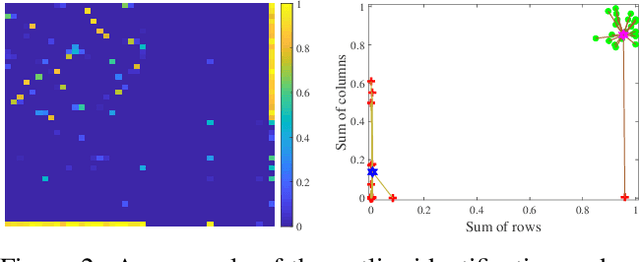
Graph matching (GM), as a longstanding problem in computer vision and pattern recognition, still suffers from numerous cluttered outliers in practical applications. To address this issue, we present the zero-assignment constraint (ZAC) for approaching the graph matching problem in the presence of outliers. The underlying idea is to suppress the matchings of outliers by assigning zero-valued vectors to the potential outliers in the obtained optimal correspondence matrix. We provide elaborate theoretical analysis to the problem, i.e., GM with ZAC, and figure out that the GM problem with and without outliers are intrinsically different, which enables us to put forward a sufficient condition to construct valid and reasonable objective function. Consequently, we design an efficient outlier-robust algorithm to significantly reduce the incorrect or redundant matchings caused by numerous outliers. Extensive experiments demonstrate that our method can achieve the state-of-the-art performance in terms of accuracy and efficiency, especially in the presence of numerous outliers.