 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDMTG: One-Shot Differentiable Multi-Task Grouping
Jul 06, 2024We aim to address Multi-Task Learning (MTL) with a large number of tasks by Multi-Task Grouping (MTG). Given N tasks, we propose to simultaneously identify the best task groups from 2^N candidates and train the model weights simultaneously in one-shot, with the high-order task-affinity fully exploited. This is distinct from the pioneering methods which sequentially identify the groups and train the model weights, where the group identification often relies on heuristics. As a result, our method not only improves the training efficiency, but also mitigates the objective bias introduced by the sequential procedures that potentially lead to a suboptimal solution. Specifically, we formulate MTG as a fully differentiable pruning problem on an adaptive network architecture determined by an underlying Categorical distribution. To categorize N tasks into K groups (represented by K encoder branches), we initially set up KN task heads, where each branch connects to all N task heads to exploit the high-order task-affinity. Then, we gradually prune the KN heads down to N by learning a relaxed differentiable Categorical distribution, ensuring that each task is exclusively and uniquely categorized into only one branch. Extensive experiments on CelebA and Taskonomy datasets with detailed ablations show the promising performance and efficiency of our method. The codes are available at https://github.com/ethanygao/DMTG.
* Accepted to ICML 2024
Portrait3D: 3D Head Generation from Single In-the-wild Portrait Image
Jun 24, 2024While recent works have achieved great success on one-shot 3D common object generation, high quality and fidelity 3D head generation from a single image remains a great challenge. Previous text-based methods for generating 3D heads were limited by text descriptions and image-based methods struggled to produce high-quality head geometry. To handle this challenging problem, we propose a novel framework, Portrait3D, to generate high-quality 3D heads while preserving their identities. Our work incorporates the identity information of the portrait image into three parts: 1) geometry initialization, 2) geometry sculpting, and 3) texture generation stages. Given a reference portrait image, we first align the identity features with text features to realize ID-aware guidance enhancement, which contains the control signals representing the face information. We then use the canny map, ID features of the portrait image, and a pre-trained text-to-normal/depth diffusion model to generate ID-aware geometry supervision, and 3D-GAN inversion is employed to generate ID-aware geometry initialization. Furthermore, with the ability to inject identity information into 3D head generation, we use ID-aware guidance to calculate ID-aware Score Distillation (ISD) for geometry sculpting. For texture generation, we adopt the ID Consistent Texture Inpainting and Refinement which progressively expands the view for texture inpainting to obtain an initialization UV texture map. We then use the id-aware guidance to provide image-level supervision for noisy multi-view images to obtain a refined texture map. Extensive experiments demonstrate that we can generate high-quality 3D heads with accurate geometry and texture from single in-the-wild portrait images. The project page is at https://jinkun-hao.github.io/Portrait3D/.
FreeMotion: A Unified Framework for Number-free Text-to-Motion Synthesis
May 24, 2024



Text-to-motion synthesis is a crucial task in computer vision. Existing methods are limited in their universality, as they are tailored for single-person or two-person scenarios and can not be applied to generate motions for more individuals. To achieve the number-free motion synthesis, this paper reconsiders motion generation and proposes to unify the single and multi-person motion by the conditional motion distribution. Furthermore, a generation module and an interaction module are designed for our FreeMotion framework to decouple the process of conditional motion generation and finally support the number-free motion synthesis. Besides, based on our framework, the current single-person motion spatial control method could be seamlessly integrated, achieving precise control of multi-person motion. Extensive experiments demonstrate the superior performance of our method and our capability to infer single and multi-human motions simultaneously.
HairStep: Transfer Synthetic to Real Using Strand and Depth Maps for Single-View 3D Hair Modeling
Mar 05, 2023



In this work, we tackle the challenging problem of learning-based single-view 3D hair modeling. Due to the great difficulty of collecting paired real image and 3D hair data, using synthetic data to provide prior knowledge for real domain becomes a leading solution. This unfortunately introduces the challenge of domain gap. Due to the inherent difficulty of realistic hair rendering, existing methods typically use orientation maps instead of hair images as input to bridge the gap. We firmly think an intermediate representation is essential, but we argue that orientation map using the dominant filtering-based methods is sensitive to uncertain noise and far from a competent representation. Thus, we first raise this issue up and propose a novel intermediate representation, termed as HairStep, which consists of a strand map and a depth map. It is found that HairStep not only provides sufficient information for accurate 3D hair modeling, but also is feasible to be inferred from real images. Specifically, we collect a dataset of 1,250 portrait images with two types of annotations. A learning framework is further designed to transfer real images to the strand map and depth map. It is noted that, an extra bonus of our new dataset is the first quantitative metric for 3D hair modeling. Our experiments show that HairStep narrows the domain gap between synthetic and real and achieves state-of-the-art performance on single-view 3D hair reconstruction.
Implicit Neural Deformation for Multi-View Face Reconstruction
Dec 05, 2021


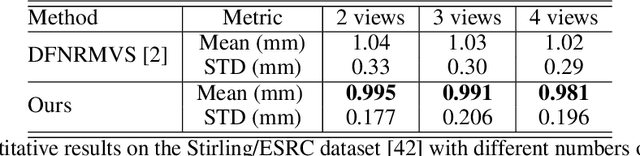
In this work, we present a new method for 3D face reconstruction from multi-view RGB images. Unlike previous methods which are built upon 3D morphable models (3DMMs) with limited details, our method leverages an implicit representation to encode rich geometric features. Our overall pipeline consists of two major components, including a geometry network, which learns a deformable neural signed distance function (SDF) as the 3D face representation, and a rendering network, which learns to render on-surface points of the neural SDF to match the input images via self-supervised optimization. To handle in-the-wild sparse-view input of the same target with different expressions at test time, we further propose residual latent code to effectively expand the shape space of the learned implicit face representation, as well as a novel view-switch loss to enforce consistency among different views. Our experimental results on several benchmark datasets demonstrate that our approach outperforms alternative baselines and achieves superior face reconstruction results compared to state-of-the-art methods.
Exploiting Learnable Joint Groups for Hand Pose Estimation
Dec 17, 2020
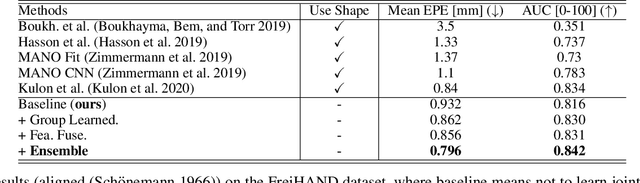
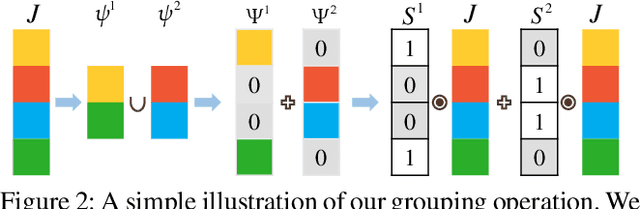
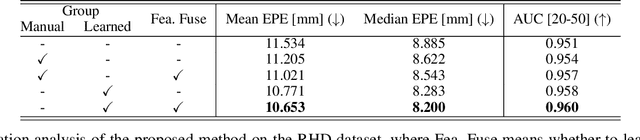
In this paper, we propose to estimate 3D hand pose by recovering the 3D coordinates of joints in a group-wise manner, where less-related joints are automatically categorized into different groups and exhibit different features. This is different from the previous methods where all the joints are considered holistically and share the same feature. The benefits of our method are illustrated by the principle of multi-task learning (MTL), i.e., by separating less-related joints into different groups (as different tasks), our method learns different features for each of them, therefore efficiently avoids the negative transfer (among less related tasks/groups of joints). The key of our method is a novel binary selector that automatically selects related joints into the same group. We implement such a selector with binary values stochastically sampled from a Concrete distribution, which is constructed using Gumbel softmax on trainable parameters. This enables us to preserve the differentiable property of the whole network. We further exploit features from those less-related groups by carrying out an additional feature fusing scheme among them, to learn more discriminative features. This is realized by implementing multiple 1x1 convolutions on the concatenated features, where each joint group contains a unique 1x1 convolution for feature fusion. The detailed ablation analysis and the extensive experiments on several benchmark datasets demonstrate the promising performance of the proposed method over the state-of-the-art (SOTA) methods. Besides, our method achieves top-1 among all the methods that do not exploit the dense 3D shape labels on the most recently released FreiHAND competition at the submission date. The source code and models are available at https://github.com/ moranli-aca/LearnableGroups-Hand.