 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSoul: Breathe Life into Digital Human for High-fidelity Long-term Multimodal Animation
Dec 15, 2025We propose a multimodal-driven framework for high-fidelity long-term digital human animation termed $\textbf{Soul}$, which generates semantically coherent videos from a single-frame portrait image, text prompts, and audio, achieving precise lip synchronization, vivid facial expressions, and robust identity preservation. We construct Soul-1M, containing 1 million finely annotated samples with a precise automated annotation pipeline (covering portrait, upper-body, full-body, and multi-person scenes) to mitigate data scarcity, and we carefully curate Soul-Bench for comprehensive and fair evaluation of audio-/text-guided animation methods. The model is built on the Wan2.2-5B backbone, integrating audio-injection layers and multiple training strategies together with threshold-aware codebook replacement to ensure long-term generation consistency. Meanwhile, step/CFG distillation and a lightweight VAE are used to optimize inference efficiency, achieving an 11.4$\times$ speedup with negligible quality loss. Extensive experiments show that Soul significantly outperforms current leading open-source and commercial models on video quality, video-text alignment, identity preservation, and lip-synchronization accuracy, demonstrating broad applicability in real-world scenarios such as virtual anchors and film production. Project page at https://zhangzjn.github.io/projects/Soul/
Transform Trained Transformer: Accelerating Naive 4K Video Generation Over 10$\times$
Dec 15, 2025Native 4K (2160$\times$3840) video generation remains a critical challenge due to the quadratic computational explosion of full-attention as spatiotemporal resolution increases, making it difficult for models to strike a balance between efficiency and quality. This paper proposes a novel Transformer retrofit strategy termed $\textbf{T3}$ ($\textbf{T}$ransform $\textbf{T}$rained $\textbf{T}$ransformer) that, without altering the core architecture of full-attention pretrained models, significantly reduces compute requirements by optimizing their forward logic. Specifically, $\textbf{T3-Video}$ introduces a multi-scale weight-sharing window attention mechanism and, via hierarchical blocking together with an axis-preserving full-attention design, can effect an "attention pattern" transformation of a pretrained model using only modest compute and data. Results on 4K-VBench show that $\textbf{T3-Video}$ substantially outperforms existing approaches: while delivering performance improvements (+4.29$\uparrow$ VQA and +0.08$\uparrow$ VTC), it accelerates native 4K video generation by more than 10$\times$. Project page at https://zhangzjn.github.io/projects/T3-Video
SwiftVideo: A Unified Framework for Few-Step Video Generation through Trajectory-Distribution Alignment
Aug 08, 2025Diffusion-based or flow-based models have achieved significant progress in video synthesis but require multiple iterative sampling steps, which incurs substantial computational overhead. While many distillation methods that are solely based on trajectory-preserving or distribution-matching have been developed to accelerate video generation models, these approaches often suffer from performance breakdown or increased artifacts under few-step settings. To address these limitations, we propose \textbf{\emph{SwiftVideo}}, a unified and stable distillation framework that combines the advantages of trajectory-preserving and distribution-matching strategies. Our approach introduces continuous-time consistency distillation to ensure precise preservation of ODE trajectories. Subsequently, we propose a dual-perspective alignment that includes distribution alignment between synthetic and real data along with trajectory alignment across different inference steps. Our method maintains high-quality video generation while substantially reducing the number of inference steps. Quantitative evaluations on the OpenVid-1M benchmark demonstrate that our method significantly outperforms existing approaches in few-step video generation.
Portrait3D: 3D Head Generation from Single In-the-wild Portrait Image
Jun 24, 2024While recent works have achieved great success on one-shot 3D common object generation, high quality and fidelity 3D head generation from a single image remains a great challenge. Previous text-based methods for generating 3D heads were limited by text descriptions and image-based methods struggled to produce high-quality head geometry. To handle this challenging problem, we propose a novel framework, Portrait3D, to generate high-quality 3D heads while preserving their identities. Our work incorporates the identity information of the portrait image into three parts: 1) geometry initialization, 2) geometry sculpting, and 3) texture generation stages. Given a reference portrait image, we first align the identity features with text features to realize ID-aware guidance enhancement, which contains the control signals representing the face information. We then use the canny map, ID features of the portrait image, and a pre-trained text-to-normal/depth diffusion model to generate ID-aware geometry supervision, and 3D-GAN inversion is employed to generate ID-aware geometry initialization. Furthermore, with the ability to inject identity information into 3D head generation, we use ID-aware guidance to calculate ID-aware Score Distillation (ISD) for geometry sculpting. For texture generation, we adopt the ID Consistent Texture Inpainting and Refinement which progressively expands the view for texture inpainting to obtain an initialization UV texture map. We then use the id-aware guidance to provide image-level supervision for noisy multi-view images to obtain a refined texture map. Extensive experiments demonstrate that we can generate high-quality 3D heads with accurate geometry and texture from single in-the-wild portrait images. The project page is at https://jinkun-hao.github.io/Portrait3D/.
VividPose: Advancing Stable Video Diffusion for Realistic Human Image Animation
May 28, 2024
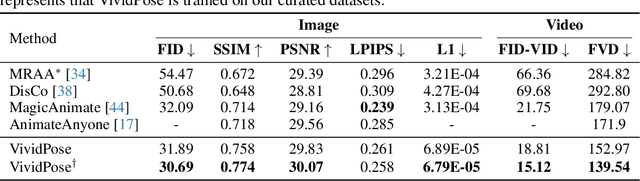
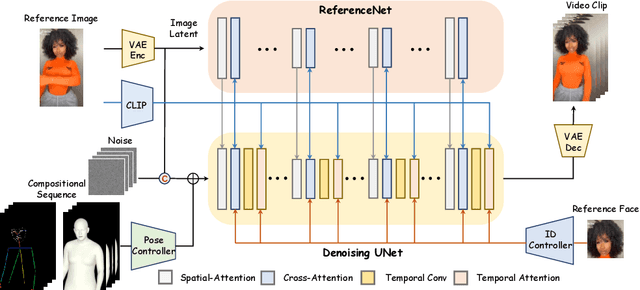
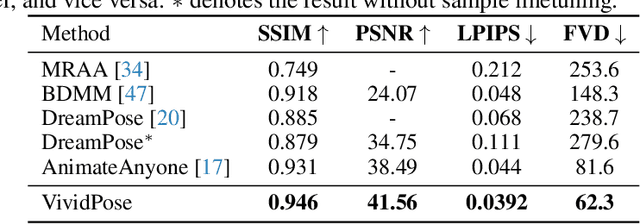
Human image animation involves generating a video from a static image by following a specified pose sequence. Current approaches typically adopt a multi-stage pipeline that separately learns appearance and motion, which often leads to appearance degradation and temporal inconsistencies. To address these issues, we propose VividPose, an innovative end-to-end pipeline based on Stable Video Diffusion (SVD) that ensures superior temporal stability. To enhance the retention of human identity, we propose an identity-aware appearance controller that integrates additional facial information without compromising other appearance details such as clothing texture and background. This approach ensures that the generated videos maintain high fidelity to the identity of human subject, preserving key facial features across various poses. To accommodate diverse human body shapes and hand movements, we introduce a geometry-aware pose controller that utilizes both dense rendering maps from SMPL-X and sparse skeleton maps. This enables accurate alignment of pose and shape in the generated videos, providing a robust framework capable of handling a wide range of body shapes and dynamic hand movements. Extensive qualitative and quantitative experiments on the UBCFashion and TikTok benchmarks demonstrate that our method achieves state-of-the-art performance. Furthermore, VividPose exhibits superior generalization capabilities on our proposed in-the-wild dataset. Codes and models will be available.
FreeMotion: A Unified Framework for Number-free Text-to-Motion Synthesis
May 24, 2024



Text-to-motion synthesis is a crucial task in computer vision. Existing methods are limited in their universality, as they are tailored for single-person or two-person scenarios and can not be applied to generate motions for more individuals. To achieve the number-free motion synthesis, this paper reconsiders motion generation and proposes to unify the single and multi-person motion by the conditional motion distribution. Furthermore, a generation module and an interaction module are designed for our FreeMotion framework to decouple the process of conditional motion generation and finally support the number-free motion synthesis. Besides, based on our framework, the current single-person motion spatial control method could be seamlessly integrated, achieving precise control of multi-person motion. Extensive experiments demonstrate the superior performance of our method and our capability to infer single and multi-human motions simultaneously.
DiffFAE: Advancing High-fidelity One-shot Facial Appearance Editing with Space-sensitive Customization and Semantic Preservation
Mar 26, 2024
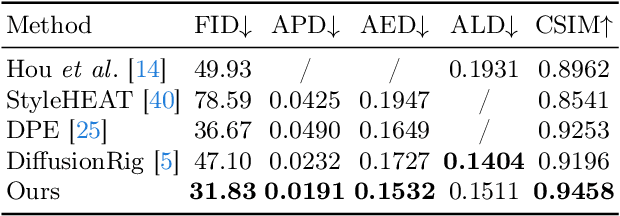
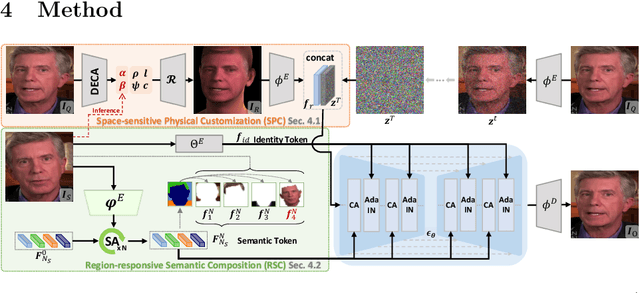

Facial Appearance Editing (FAE) aims to modify physical attributes, such as pose, expression and lighting, of human facial images while preserving attributes like identity and background, showing great importance in photograph. In spite of the great progress in this area, current researches generally meet three challenges: low generation fidelity, poor attribute preservation, and inefficient inference. To overcome above challenges, this paper presents DiffFAE, a one-stage and highly-efficient diffusion-based framework tailored for high-fidelity FAE. For high-fidelity query attributes transfer, we adopt Space-sensitive Physical Customization (SPC), which ensures the fidelity and generalization ability by utilizing rendering texture derived from 3D Morphable Model (3DMM). In order to preserve source attributes, we introduce the Region-responsive Semantic Composition (RSC). This module is guided to learn decoupled source-regarding features, thereby better preserving the identity and alleviating artifacts from non-facial attributes such as hair, clothes, and background. We further introduce a consistency regularization for our pipeline to enhance editing controllability by leveraging prior knowledge in the attention matrices of diffusion model. Extensive experiments demonstrate the superiority of DiffFAE over existing methods, achieving state-of-the-art performance in facial appearance editing.
TexDreamer: Towards Zero-Shot High-Fidelity 3D Human Texture Generation
Mar 19, 2024



Texturing 3D humans with semantic UV maps remains a challenge due to the difficulty of acquiring reasonably unfolded UV. Despite recent text-to-3D advancements in supervising multi-view renderings using large text-to-image (T2I) models, issues persist with generation speed, text consistency, and texture quality, resulting in data scarcity among existing datasets. We present TexDreamer, the first zero-shot multimodal high-fidelity 3D human texture generation model. Utilizing an efficient texture adaptation finetuning strategy, we adapt large T2I model to a semantic UV structure while preserving its original generalization capability. Leveraging a novel feature translator module, the trained model is capable of generating high-fidelity 3D human textures from either text or image within seconds. Furthermore, we introduce ArTicuLated humAn textureS (ATLAS), the largest high-resolution (1024 X 1024) 3D human texture dataset which contains 50k high-fidelity textures with text descriptions.