 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBridging Latent Reasoning and Target-Language Generation via Retrieval-Transition Heads
Feb 25, 2026Recent work has identified a subset of attention heads in Transformer as retrieval heads, which are responsible for retrieving information from the context. In this work, we first investigate retrieval heads in multilingual contexts. In multilingual language models, we find that retrieval heads are often shared across multiple languages. Expanding the study to cross-lingual setting, we identify Retrieval-Transition heads(RTH), which govern the transition to specific target-language output. Our experiments reveal that RTHs are distinct from retrieval heads and more vital for Chain-of-Thought reasoning in multilingual LLMs. Across four multilingual benchmarks (MMLU-ProX, MGSM, MLQA, and XQuaD) and two model families (Qwen-2.5 and Llama-3.1), we demonstrate that masking RTH induces bigger performance drop than masking Retrieval Heads (RH). Our work advances understanding of multilingual LMs by isolating the attention heads responsible for mapping to target languages.
Compatibility of Max and Sum Objectives for Committee Selection and $k$-Facility Location
Jul 22, 2025We study a version of the metric facility location problem (or, equivalently, variants of the committee selection problem) in which we must choose $k$ facilities in an arbitrary metric space to serve some set of clients $C$. We consider four different objectives, where each client $i\in C$ attempts to minimize either the sum or the maximum of its distance to the chosen facilities, and where the overall objective either considers the sum or the maximum of the individual client costs. Rather than optimizing a single objective at a time, we study how compatible these objectives are with each other, and show the existence of solutions which are simultaneously close-to-optimum for any pair of the above objectives. Our results show that when choosing a set of facilities or a representative committee, it is often possible to form a solution which is good for several objectives at the same time, instead of sacrificing one desideratum to achieve another.
Face Adapter for Pre-Trained Diffusion Models with Fine-Grained ID and Attribute Control
May 21, 2024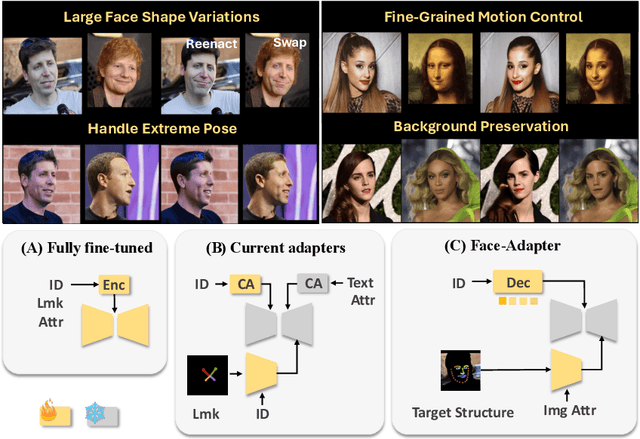
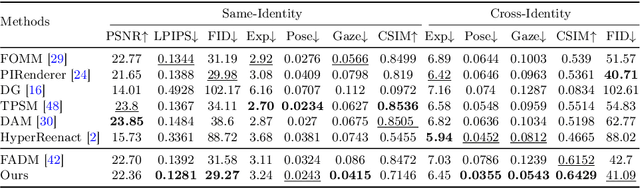
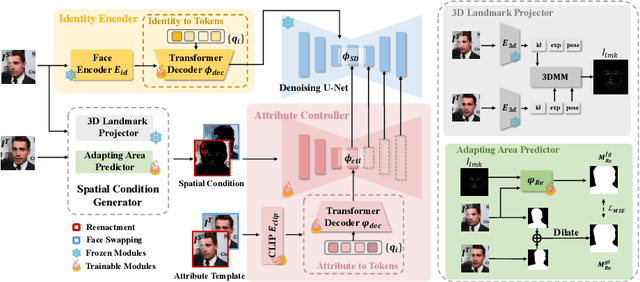
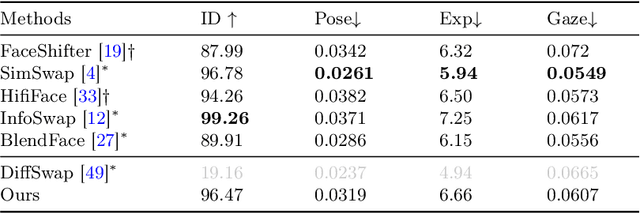
Current face reenactment and swapping methods mainly rely on GAN frameworks, but recent focus has shifted to pre-trained diffusion models for their superior generation capabilities. However, training these models is resource-intensive, and the results have not yet achieved satisfactory performance levels. To address this issue, we introduce Face-Adapter, an efficient and effective adapter designed for high-precision and high-fidelity face editing for pre-trained diffusion models. We observe that both face reenactment/swapping tasks essentially involve combinations of target structure, ID and attribute. We aim to sufficiently decouple the control of these factors to achieve both tasks in one model. Specifically, our method contains: 1) A Spatial Condition Generator that provides precise landmarks and background; 2) A Plug-and-play Identity Encoder that transfers face embeddings to the text space by a transformer decoder. 3) An Attribute Controller that integrates spatial conditions and detailed attributes. Face-Adapter achieves comparable or even superior performance in terms of motion control precision, ID retention capability, and generation quality compared to fully fine-tuned face reenactment/swapping models. Additionally, Face-Adapter seamlessly integrates with various StableDiffusion models.
DiffFAE: Advancing High-fidelity One-shot Facial Appearance Editing with Space-sensitive Customization and Semantic Preservation
Mar 26, 2024
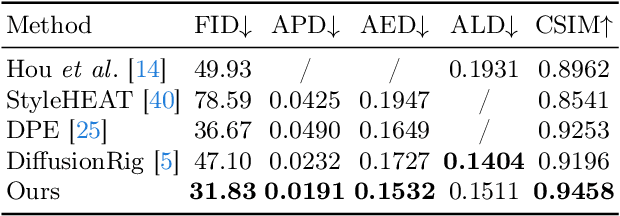
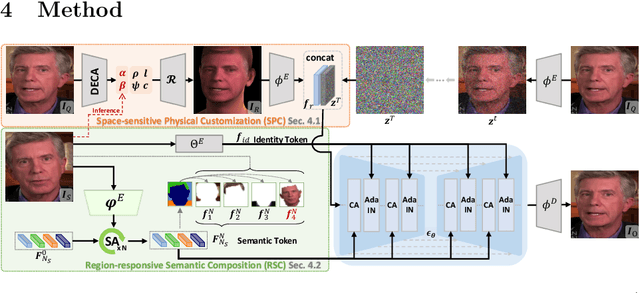

Facial Appearance Editing (FAE) aims to modify physical attributes, such as pose, expression and lighting, of human facial images while preserving attributes like identity and background, showing great importance in photograph. In spite of the great progress in this area, current researches generally meet three challenges: low generation fidelity, poor attribute preservation, and inefficient inference. To overcome above challenges, this paper presents DiffFAE, a one-stage and highly-efficient diffusion-based framework tailored for high-fidelity FAE. For high-fidelity query attributes transfer, we adopt Space-sensitive Physical Customization (SPC), which ensures the fidelity and generalization ability by utilizing rendering texture derived from 3D Morphable Model (3DMM). In order to preserve source attributes, we introduce the Region-responsive Semantic Composition (RSC). This module is guided to learn decoupled source-regarding features, thereby better preserving the identity and alleviating artifacts from non-facial attributes such as hair, clothes, and background. We further introduce a consistency regularization for our pipeline to enhance editing controllability by leveraging prior knowledge in the attention matrices of diffusion model. Extensive experiments demonstrate the superiority of DiffFAE over existing methods, achieving state-of-the-art performance in facial appearance editing.
A Generalist FaceX via Learning Unified Facial Representation
Dec 31, 2023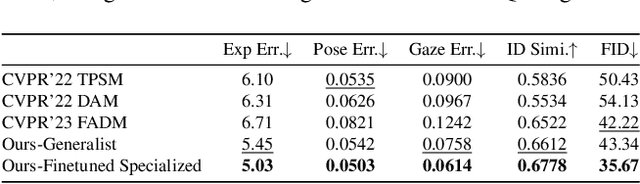

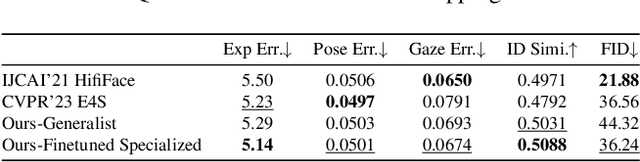
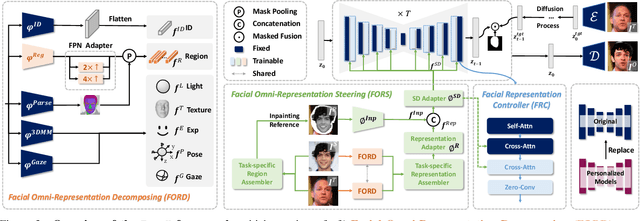
This work presents FaceX framework, a novel facial generalist model capable of handling diverse facial tasks simultaneously. To achieve this goal, we initially formulate a unified facial representation for a broad spectrum of facial editing tasks, which macroscopically decomposes a face into fundamental identity, intra-personal variation, and environmental factors. Based on this, we introduce Facial Omni-Representation Decomposing (FORD) for seamless manipulation of various facial components, microscopically decomposing the core aspects of most facial editing tasks. Furthermore, by leveraging the prior of a pretrained StableDiffusion (SD) to enhance generation quality and accelerate training, we design Facial Omni-Representation Steering (FORS) to first assemble unified facial representations and then effectively steer the SD-aware generation process by the efficient Facial Representation Controller (FRC). %Without any additional features, Our versatile FaceX achieves competitive performance compared to elaborate task-specific models on popular facial editing tasks. Full codes and models will be available at https://github.com/diffusion-facex/FaceX.
Diffusion Model with Clustering-based Conditioning for Food Image Generation
Sep 01, 2023



Image-based dietary assessment serves as an efficient and accurate solution for recording and analyzing nutrition intake using eating occasion images as input. Deep learning-based techniques are commonly used to perform image analysis such as food classification, segmentation, and portion size estimation, which rely on large amounts of food images with annotations for training. However, such data dependency poses significant barriers to real-world applications, because acquiring a substantial, diverse, and balanced set of food images can be challenging. One potential solution is to use synthetic food images for data augmentation. Although existing work has explored the use of generative adversarial networks (GAN) based structures for generation, the quality of synthetic food images still remains subpar. In addition, while diffusion-based generative models have shown promising results for general image generation tasks, the generation of food images can be challenging due to the substantial intra-class variance. In this paper, we investigate the generation of synthetic food images based on the conditional diffusion model and propose an effective clustering-based training framework, named ClusDiff, for generating high-quality and representative food images. The proposed method is evaluated on the Food-101 dataset and shows improved performance when compared with existing image generation works. We also demonstrate that the synthetic food images generated by ClusDiff can help address the severe class imbalance issue in long-tailed food classification using the VFN-LT dataset.
A Zero-/Few-Shot Anomaly Classification and Segmentation Method for CVPR 2023 VAND Workshop Challenge Tracks 1&2: 1st Place on Zero-shot AD and 4th Place on Few-shot AD
Jun 13, 2023



In this technical report, we briefly introduce our solution for the Zero/Few-shot Track of the Visual Anomaly and Novelty Detection (VAND) 2023 Challenge. For industrial visual inspection, building a single model that can be rapidly adapted to numerous categories without or with only a few normal reference images is a promising research direction. This is primarily because of the vast variety of the product types. For the zero-shot track, we propose a solution based on the CLIP model by adding extra linear layers. These layers are used to map the image features to the joint embedding space, so that they can compare with the text features to generate the anomaly maps. Besides, when the reference images are available, we utilize multiple memory banks to store their features and compare them with the features of the test images during the testing phase. In this challenge, our method achieved first place in the zero-shot track, especially excelling in segmentation with an impressive F1 score improvement of 0.0489 over the second-ranked participant. Furthermore, in the few-shot track, we secured the fourth position overall, with our classification F1 score of 0.8687 ranking first among all participating teams.
Learning Global-aware Kernel for Image Harmonization
May 19, 2023Image harmonization aims to solve the visual inconsistency problem in composited images by adaptively adjusting the foreground pixels with the background as references. Existing methods employ local color transformation or region matching between foreground and background, which neglects powerful proximity prior and independently distinguishes fore-/back-ground as a whole part for harmonization. As a result, they still show a limited performance across varied foreground objects and scenes. To address this issue, we propose a novel Global-aware Kernel Network (GKNet) to harmonize local regions with comprehensive consideration of long-distance background references. Specifically, GKNet includes two parts, \ie, harmony kernel prediction and harmony kernel modulation branches. The former includes a Long-distance Reference Extractor (LRE) to obtain long-distance context and Kernel Prediction Blocks (KPB) to predict multi-level harmony kernels by fusing global information with local features. To achieve this goal, a novel Selective Correlation Fusion (SCF) module is proposed to better select relevant long-distance background references for local harmonization. The latter employs the predicted kernels to harmonize foreground regions with both local and global awareness. Abundant experiments demonstrate the superiority of our method for image harmonization over state-of-the-art methods, \eg, achieving 39.53dB PSNR that surpasses the best counterpart by +0.78dB $\uparrow$; decreasing fMSE/MSE by 11.5\%$\downarrow$/6.7\%$\downarrow$ compared with the SoTA method. Code will be available at \href{https://github.com/XintianShen/GKNet}{here}.
High-fidelity Generalized Emotional Talking Face Generation with Multi-modal Emotion Space Learning
May 04, 2023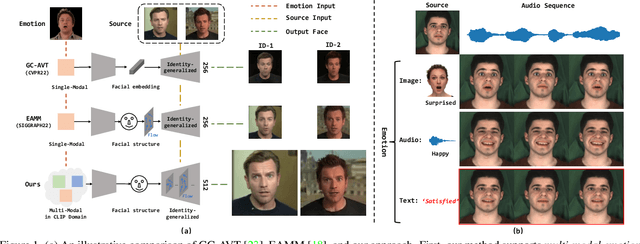
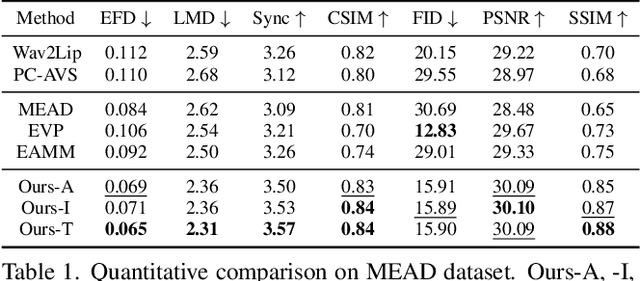
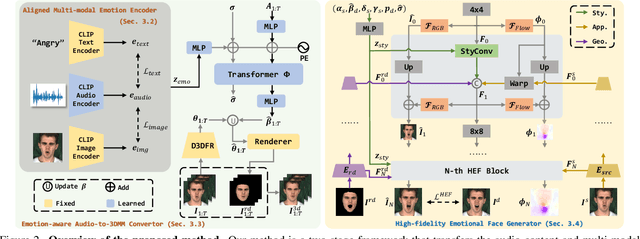
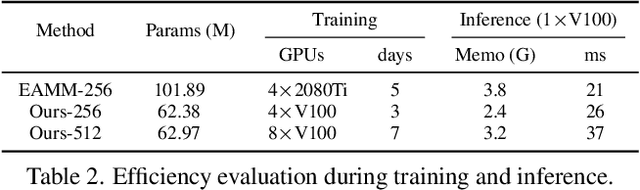
Recently, emotional talking face generation has received considerable attention. However, existing methods only adopt one-hot coding, image, or audio as emotion conditions, thus lacking flexible control in practical applications and failing to handle unseen emotion styles due to limited semantics. They either ignore the one-shot setting or the quality of generated faces. In this paper, we propose a more flexible and generalized framework. Specifically, we supplement the emotion style in text prompts and use an Aligned Multi-modal Emotion encoder to embed the text, image, and audio emotion modality into a unified space, which inherits rich semantic prior from CLIP. Consequently, effective multi-modal emotion space learning helps our method support arbitrary emotion modality during testing and could generalize to unseen emotion styles. Besides, an Emotion-aware Audio-to-3DMM Convertor is proposed to connect the emotion condition and the audio sequence to structural representation. A followed style-based High-fidelity Emotional Face generator is designed to generate arbitrary high-resolution realistic identities. Our texture generator hierarchically learns flow fields and animated faces in a residual manner. Extensive experiments demonstrate the flexibility and generalization of our method in emotion control and the effectiveness of high-quality face synthesis.
Conditional Synthetic Food Image Generation
Mar 16, 2023



Generative Adversarial Networks (GAN) have been widely investigated for image synthesis based on their powerful representation learning ability. In this work, we explore the StyleGAN and its application of synthetic food image generation. Despite the impressive performance of GAN for natural image generation, food images suffer from high intra-class diversity and inter-class similarity, resulting in overfitting and visual artifacts for synthetic images. Therefore, we aim to explore the capability and improve the performance of GAN methods for food image generation. Specifically, we first choose StyleGAN3 as the baseline method to generate synthetic food images and analyze the performance. Then, we identify two issues that can cause performance degradation on food images during the training phase: (1) inter-class feature entanglement during multi-food classes training and (2) loss of high-resolution detail during image downsampling. To address both issues, we propose to train one food category at a time to avoid feature entanglement and leverage image patches cropped from high-resolution datasets to retain fine details. We evaluate our method on the Food-101 dataset and show improved quality of generated synthetic food images compared with the baseline. Finally, we demonstrate the great potential of improving the performance of downstream tasks, such as food image classification by including high-quality synthetic training samples in the data augmentation.