 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFRIREN: Beyond Trajectories -- A Spectral Lens on Time
May 23, 2025Long-term time-series forecasting (LTSF) models are often presented as general-purpose solutions that can be applied across domains, implicitly assuming that all data is pointwise predictable. Using chaotic systems such as Lorenz-63 as a case study, we argue that geometric structure - not pointwise prediction - is the right abstraction for a dynamic-agnostic foundational model. Minimizing the Wasserstein-2 distance (W2), which captures geometric changes, and providing a spectral view of dynamics are essential for long-horizon forecasting. Our model, FRIREN (Flow-inspired Representations via Interpretable Eigen-networks), implements an augmented normalizing-flow block that embeds data into a normally distributed latent representation. It then generates a W2-efficient optimal path that can be decomposed into rotation, scaling, inverse rotation, and translation. This architecture yields locally generated, geometry-preserving predictions that are independent of the underlying dynamics, and a global spectral representation that functions as a finite Koopman operator with a small modification. This enables practitioners to identify which modes grow, decay, or oscillate, both locally and system-wide. FRIREN achieves an MSE of 11.4, MAE of 1.6, and SWD of 0.96 on Lorenz-63 in a 336-in, 336-out, dt=0.01 setting, surpassing TimeMixer (MSE 27.3, MAE 2.8, SWD 2.1). The model maintains effective prediction for 274 out of 336 steps, approximately 2.5 Lyapunov times. On Rossler (96-in, 336-out), FRIREN achieves an MSE of 0.0349, MAE of 0.0953, and SWD of 0.0170, outperforming TimeMixer's MSE of 4.3988, MAE of 0.886, and SWD of 3.2065. FRIREN is also competitive on standard LTSF datasets such as ETT and Weather. By connecting modern generative flows with classical spectral analysis, FRIREN makes long-term forecasting both accurate and interpretable, setting a new benchmark for LTSF model design.
MDT-A2G: Exploring Masked Diffusion Transformers for Co-Speech Gesture Generation
Aug 06, 2024



Recent advancements in the field of Diffusion Transformers have substantially improved the generation of high-quality 2D images, 3D videos, and 3D shapes. However, the effectiveness of the Transformer architecture in the domain of co-speech gesture generation remains relatively unexplored, as prior methodologies have predominantly employed the Convolutional Neural Network (CNNs) or simple a few transformer layers. In an attempt to bridge this research gap, we introduce a novel Masked Diffusion Transformer for co-speech gesture generation, referred to as MDT-A2G, which directly implements the denoising process on gesture sequences. To enhance the contextual reasoning capability of temporally aligned speech-driven gestures, we incorporate a novel Masked Diffusion Transformer. This model employs a mask modeling scheme specifically designed to strengthen temporal relation learning among sequence gestures, thereby expediting the learning process and leading to coherent and realistic motions. Apart from audio, Our MDT-A2G model also integrates multi-modal information, encompassing text, emotion, and identity. Furthermore, we propose an efficient inference strategy that diminishes the denoising computation by leveraging previously calculated results, thereby achieving a speedup with negligible performance degradation. Experimental results demonstrate that MDT-A2G excels in gesture generation, boasting a learning speed that is over 6$\times$ faster than traditional diffusion transformers and an inference speed that is 5.7$\times$ than the standard diffusion model.
VividPose: Advancing Stable Video Diffusion for Realistic Human Image Animation
May 28, 2024
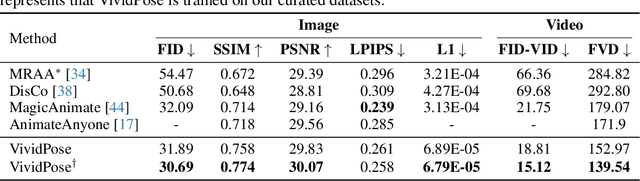
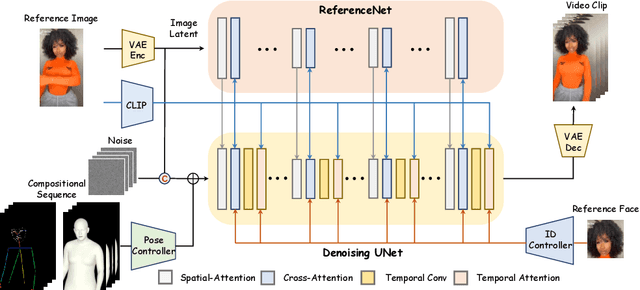
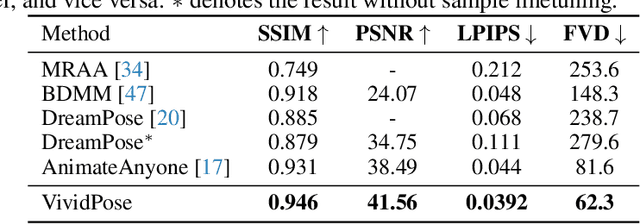
Human image animation involves generating a video from a static image by following a specified pose sequence. Current approaches typically adopt a multi-stage pipeline that separately learns appearance and motion, which often leads to appearance degradation and temporal inconsistencies. To address these issues, we propose VividPose, an innovative end-to-end pipeline based on Stable Video Diffusion (SVD) that ensures superior temporal stability. To enhance the retention of human identity, we propose an identity-aware appearance controller that integrates additional facial information without compromising other appearance details such as clothing texture and background. This approach ensures that the generated videos maintain high fidelity to the identity of human subject, preserving key facial features across various poses. To accommodate diverse human body shapes and hand movements, we introduce a geometry-aware pose controller that utilizes both dense rendering maps from SMPL-X and sparse skeleton maps. This enables accurate alignment of pose and shape in the generated videos, providing a robust framework capable of handling a wide range of body shapes and dynamic hand movements. Extensive qualitative and quantitative experiments on the UBCFashion and TikTok benchmarks demonstrate that our method achieves state-of-the-art performance. Furthermore, VividPose exhibits superior generalization capabilities on our proposed in-the-wild dataset. Codes and models will be available.
DiffFAE: Advancing High-fidelity One-shot Facial Appearance Editing with Space-sensitive Customization and Semantic Preservation
Mar 26, 2024
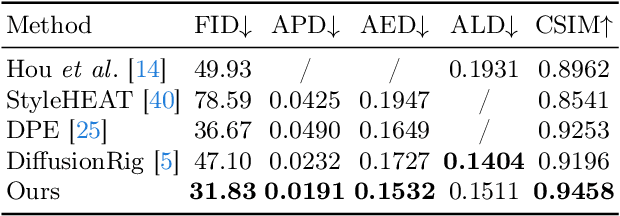
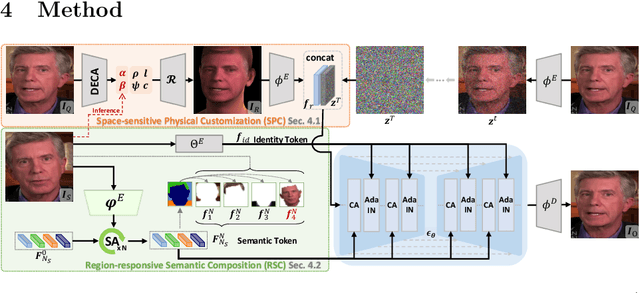

Facial Appearance Editing (FAE) aims to modify physical attributes, such as pose, expression and lighting, of human facial images while preserving attributes like identity and background, showing great importance in photograph. In spite of the great progress in this area, current researches generally meet three challenges: low generation fidelity, poor attribute preservation, and inefficient inference. To overcome above challenges, this paper presents DiffFAE, a one-stage and highly-efficient diffusion-based framework tailored for high-fidelity FAE. For high-fidelity query attributes transfer, we adopt Space-sensitive Physical Customization (SPC), which ensures the fidelity and generalization ability by utilizing rendering texture derived from 3D Morphable Model (3DMM). In order to preserve source attributes, we introduce the Region-responsive Semantic Composition (RSC). This module is guided to learn decoupled source-regarding features, thereby better preserving the identity and alleviating artifacts from non-facial attributes such as hair, clothes, and background. We further introduce a consistency regularization for our pipeline to enhance editing controllability by leveraging prior knowledge in the attention matrices of diffusion model. Extensive experiments demonstrate the superiority of DiffFAE over existing methods, achieving state-of-the-art performance in facial appearance editing.