 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChinese Labor Law Large Language Model Benchmark
Jan 15, 2026Recent advances in large language models (LLMs) have led to substantial progress in domain-specific applications, particularly within the legal domain. However, general-purpose models such as GPT-4 often struggle with specialized subdomains that require precise legal knowledge, complex reasoning, and contextual sensitivity. To address these limitations, we present LabourLawLLM, a legal large language model tailored to Chinese labor law. We also introduce LabourLawBench, a comprehensive benchmark covering diverse labor-law tasks, including legal provision citation, knowledge-based question answering, case classification, compensation computation, named entity recognition, and legal case analysis. Our evaluation framework combines objective metrics (e.g., ROUGE-L, accuracy, F1, and soft-F1) with subjective assessment based on GPT-4 scoring. Experiments show that LabourLawLLM consistently outperforms general-purpose and existing legal-specific LLMs across task categories. Beyond labor law, our methodology provides a scalable approach for building specialized LLMs in other legal subfields, improving accuracy, reliability, and societal value of legal AI applications.
Yume: An Interactive World Generation Model
Jul 23, 2025

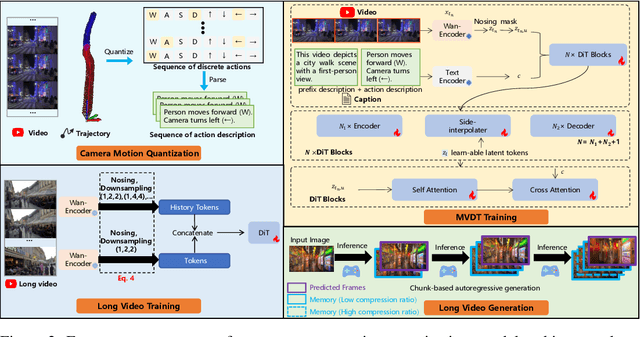

Yume aims to use images, text, or videos to create an interactive, realistic, and dynamic world, which allows exploration and control using peripheral devices or neural signals. In this report, we present a preview version of \method, which creates a dynamic world from an input image and allows exploration of the world using keyboard actions. To achieve this high-fidelity and interactive video world generation, we introduce a well-designed framework, which consists of four main components, including camera motion quantization, video generation architecture, advanced sampler, and model acceleration. First, we quantize camera motions for stable training and user-friendly interaction using keyboard inputs. Then, we introduce the Masked Video Diffusion Transformer~(MVDT) with a memory module for infinite video generation in an autoregressive manner. After that, training-free Anti-Artifact Mechanism (AAM) and Time Travel Sampling based on Stochastic Differential Equations (TTS-SDE) are introduced to the sampler for better visual quality and more precise control. Moreover, we investigate model acceleration by synergistic optimization of adversarial distillation and caching mechanisms. We use the high-quality world exploration dataset \sekai to train \method, and it achieves remarkable results in diverse scenes and applications. All data, codebase, and model weights are available on https://github.com/stdstu12/YUME. Yume will update monthly to achieve its original goal. Project page: https://stdstu12.github.io/YUME-Project/.
Real-IAD D3: A Real-World 2D/Pseudo-3D/3D Dataset for Industrial Anomaly Detection
Apr 19, 2025The increasing complexity of industrial anomaly detection (IAD) has positioned multimodal detection methods as a focal area of machine vision research. However, dedicated multimodal datasets specifically tailored for IAD remain limited. Pioneering datasets like MVTec 3D have laid essential groundwork in multimodal IAD by incorporating RGB+3D data, but still face challenges in bridging the gap with real industrial environments due to limitations in scale and resolution. To address these challenges, we introduce Real-IAD D3, a high-precision multimodal dataset that uniquely incorporates an additional pseudo3D modality generated through photometric stereo, alongside high-resolution RGB images and micrometer-level 3D point clouds. Real-IAD D3 features finer defects, diverse anomalies, and greater scale across 20 categories, providing a challenging benchmark for multimodal IAD Additionally, we introduce an effective approach that integrates RGB, point cloud, and pseudo-3D depth information to leverage the complementary strengths of each modality, enhancing detection performance. Our experiments highlight the importance of these modalities in boosting detection robustness and overall IAD performance. The dataset and code are publicly accessible for research purposes at https://realiad4ad.github.io/Real-IAD D3
GraphTEN: Graph Enhanced Texture Encoding Network
Mar 18, 2025
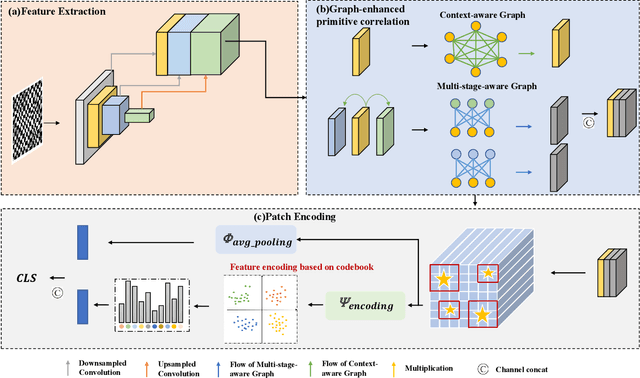


Texture recognition is a fundamental problem in computer vision and pattern recognition. Recent progress leverages feature aggregation into discriminative descriptions based on convolutional neural networks (CNNs). However, modeling non-local context relations through visual primitives remains challenging due to the variability and randomness of texture primitives in spatial distributions. In this paper, we propose a graph-enhanced texture encoding network (GraphTEN) designed to capture both local and global features of texture primitives. GraphTEN models global associations through fully connected graphs and captures cross-scale dependencies of texture primitives via bipartite graphs. Additionally, we introduce a patch encoding module that utilizes a codebook to achieve an orderless representation of texture by encoding multi-scale patch features into a unified feature space. The proposed GraphTEN achieves superior performance compared to state-of-the-art methods across five publicly available datasets.
UniCombine: Unified Multi-Conditional Combination with Diffusion Transformer
Mar 12, 2025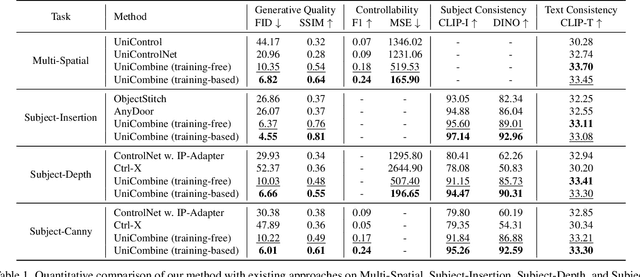
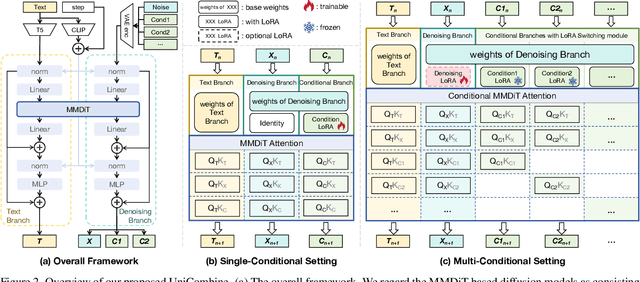
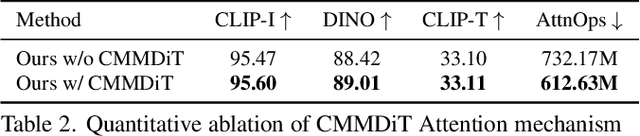
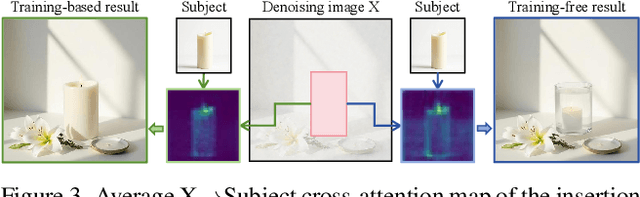
With the rapid development of diffusion models in image generation, the demand for more powerful and flexible controllable frameworks is increasing. Although existing methods can guide generation beyond text prompts, the challenge of effectively combining multiple conditional inputs while maintaining consistency with all of them remains unsolved. To address this, we introduce UniCombine, a DiT-based multi-conditional controllable generative framework capable of handling any combination of conditions, including but not limited to text prompts, spatial maps, and subject images. Specifically, we introduce a novel Conditional MMDiT Attention mechanism and incorporate a trainable LoRA module to build both the training-free and training-based versions. Additionally, we propose a new pipeline to construct SubjectSpatial200K, the first dataset designed for multi-conditional generative tasks covering both the subject-driven and spatially-aligned conditions. Extensive experimental results on multi-conditional generation demonstrate the outstanding universality and powerful capability of our approach with state-of-the-art performance.
PixelPonder: Dynamic Patch Adaptation for Enhanced Multi-Conditional Text-to-Image Generation
Mar 09, 2025Recent advances in diffusion-based text-to-image generation have demonstrated promising results through visual condition control. However, existing ControlNet-like methods struggle with compositional visual conditioning - simultaneously preserving semantic fidelity across multiple heterogeneous control signals while maintaining high visual quality, where they employ separate control branches that often introduce conflicting guidance during the denoising process, leading to structural distortions and artifacts in generated images. To address this issue, we present PixelPonder, a novel unified control framework, which allows for effective control of multiple visual conditions under a single control structure. Specifically, we design a patch-level adaptive condition selection mechanism that dynamically prioritizes spatially relevant control signals at the sub-region level, enabling precise local guidance without global interference. Additionally, a time-aware control injection scheme is deployed to modulate condition influence according to denoising timesteps, progressively transitioning from structural preservation to texture refinement and fully utilizing the control information from different categories to promote more harmonious image generation. Extensive experiments demonstrate that PixelPonder surpasses previous methods across different benchmark datasets, showing superior improvement in spatial alignment accuracy while maintaining high textual semantic consistency.
PA-CLIP: Enhancing Zero-Shot Anomaly Detection through Pseudo-Anomaly Awareness
Mar 03, 2025In industrial anomaly detection (IAD), accurately identifying defects amidst diverse anomalies and under varying imaging conditions remains a significant challenge. Traditional approaches often struggle with high false-positive rates, frequently misclassifying normal shadows and surface deformations as defects, an issue that becomes particularly pronounced in products with complex and intricate surface features. To address these challenges, we introduce PA-CLIP, a zero-shot anomaly detection method that reduces background noise and enhances defect detection through a pseudo-anomaly-based framework. The proposed method integrates a multiscale feature aggregation strategy for capturing detailed global and local information, two memory banks for distinguishing background information, including normal patterns and pseudo-anomalies, from true anomaly features, and a decision-making module designed to minimize false positives caused by environmental variations while maintaining high defect sensitivity. Demonstrated on the MVTec AD and VisA datasets, PA-CLIP outperforms existing zero-shot methods, providing a robust solution for industrial defect detection.
OSV: One Step is Enough for High-Quality Image to Video Generation
Sep 17, 2024



Video diffusion models have shown great potential in generating high-quality videos, making them an increasingly popular focus. However, their inherent iterative nature leads to substantial computational and time costs. While efforts have been made to accelerate video diffusion by reducing inference steps (through techniques like consistency distillation) and GAN training (these approaches often fall short in either performance or training stability). In this work, we introduce a two-stage training framework that effectively combines consistency distillation with GAN training to address these challenges. Additionally, we propose a novel video discriminator design, which eliminates the need for decoding the video latents and improves the final performance. Our model is capable of producing high-quality videos in merely one-step, with the flexibility to perform multi-step refinement for further performance enhancement. Our quantitative evaluation on the OpenWebVid-1M benchmark shows that our model significantly outperforms existing methods. Notably, our 1-step performance(FVD 171.15) exceeds the 8-step performance of the consistency distillation based method, AnimateLCM (FVD 184.79), and approaches the 25-step performance of advanced Stable Video Diffusion (FVD 156.94).
Mamba-YOLO-World: Marrying YOLO-World with Mamba for Open-Vocabulary Detection
Sep 16, 2024Open-vocabulary detection (OVD) aims to detect objects beyond a predefined set of categories. As a pioneering model incorporating the YOLO series into OVD, YOLO-World is well-suited for scenarios prioritizing speed and efficiency. However, its performance is hindered by its neck feature fusion mechanism, which causes the quadratic complexity and the limited guided receptive fields. To address these limitations, we present Mamba-YOLO-World, a novel YOLO-based OVD model employing the proposed MambaFusion Path Aggregation Network (MambaFusion-PAN) as its neck architecture. Specifically, we introduce an innovative State Space Model-based feature fusion mechanism consisting of a Parallel-Guided Selective Scan algorithm and a Serial-Guided Selective Scan algorithm with linear complexity and globally guided receptive fields. It leverages multi-modal input sequences and mamba hidden states to guide the selective scanning process. Experiments demonstrate that our model outperforms the original YOLO-World on the COCO and LVIS benchmarks in both zero-shot and fine-tuning settings while maintaining comparable parameters and FLOPs. Additionally, it surpasses existing state-of-the-art OVD methods with fewer parameters and FLOPs.
VI3DRM:Towards meticulous 3D Reconstruction from Sparse Views via Photo-Realistic Novel View Synthesis
Sep 12, 2024



Recently, methods like Zero-1-2-3 have focused on single-view based 3D reconstruction and have achieved remarkable success. However, their predictions for unseen areas heavily rely on the inductive bias of large-scale pretrained diffusion models. Although subsequent work, such as DreamComposer, attempts to make predictions more controllable by incorporating additional views, the results remain unrealistic due to feature entanglement in the vanilla latent space, including factors such as lighting, material, and structure. To address these issues, we introduce the Visual Isotropy 3D Reconstruction Model (VI3DRM), a diffusion-based sparse views 3D reconstruction model that operates within an ID consistent and perspective-disentangled 3D latent space. By facilitating the disentanglement of semantic information, color, material properties and lighting, VI3DRM is capable of generating highly realistic images that are indistinguishable from real photographs. By leveraging both real and synthesized images, our approach enables the accurate construction of pointmaps, ultimately producing finely textured meshes or point clouds. On the NVS task, tested on the GSO dataset, VI3DRM significantly outperforms state-of-the-art method DreamComposer, achieving a PSNR of 38.61, an SSIM of 0.929, and an LPIPS of 0.027. Code will be made available upon publication.