 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe devil is in the details: Enhancing Video Virtual Try-On via Keyframe-Driven Details Injection
Dec 23, 2025Although diffusion transformer (DiT)-based video virtual try-on (VVT) has made significant progress in synthesizing realistic videos, existing methods still struggle to capture fine-grained garment dynamics and preserve background integrity across video frames. They also incur high computational costs due to additional interaction modules introduced into DiTs, while the limited scale and quality of existing public datasets also restrict model generalization and effective training. To address these challenges, we propose a novel framework, KeyTailor, along with a large-scale, high-definition dataset, ViT-HD. The core idea of KeyTailor is a keyframe-driven details injection strategy, motivated by the fact that keyframes inherently contain both foreground dynamics and background consistency. Specifically, KeyTailor adopts an instruction-guided keyframe sampling strategy to filter informative frames from the input video. Subsequently,two tailored keyframe-driven modules, the garment details enhancement module and the collaborative background optimization module, are employed to distill garment dynamics into garment-related latents and to optimize the integrity of background latents, both guided by keyframes.These enriched details are then injected into standard DiT blocks together with pose, mask, and noise latents, enabling efficient and realistic try-on video synthesis. This design ensures consistency without explicitly modifying the DiT architecture, while simultaneously avoiding additional complexity. In addition, our dataset ViT-HD comprises 15, 070 high-quality video samples at a resolution of 810*1080, covering diverse garments. Extensive experiments demonstrate that KeyTailor outperforms state-of-the-art baselines in terms of garment fidelity and background integrity across both dynamic and static scenarios.
Reasoning to Edit: Hypothetical Instruction-Based Image Editing with Visual Reasoning
Jul 02, 2025Instruction-based image editing (IIE) has advanced rapidly with the success of diffusion models. However, existing efforts primarily focus on simple and explicit instructions to execute editing operations such as adding, deleting, moving, or swapping objects. They struggle to handle more complex implicit hypothetical instructions that require deeper reasoning to infer plausible visual changes and user intent. Additionally, current datasets provide limited support for training and evaluating reasoning-aware editing capabilities. Architecturally, these methods also lack mechanisms for fine-grained detail extraction that support such reasoning. To address these limitations, we propose Reason50K, a large-scale dataset specifically curated for training and evaluating hypothetical instruction reasoning image editing, along with ReasonBrain, a novel framework designed to reason over and execute implicit hypothetical instructions across diverse scenarios. Reason50K includes over 50K samples spanning four key reasoning scenarios: Physical, Temporal, Causal, and Story reasoning. ReasonBrain leverages Multimodal Large Language Models (MLLMs) for editing guidance generation and a diffusion model for image synthesis, incorporating a Fine-grained Reasoning Cue Extraction (FRCE) module to capture detailed visual and textual semantics essential for supporting instruction reasoning. To mitigate the semantic loss, we further introduce a Cross-Modal Enhancer (CME) that enables rich interactions between the fine-grained cues and MLLM-derived features. Extensive experiments demonstrate that ReasonBrain consistently outperforms state-of-the-art baselines on reasoning scenarios while exhibiting strong zero-shot generalization to conventional IIE tasks. Our dataset and code will be released publicly.
UniCombine: Unified Multi-Conditional Combination with Diffusion Transformer
Mar 12, 2025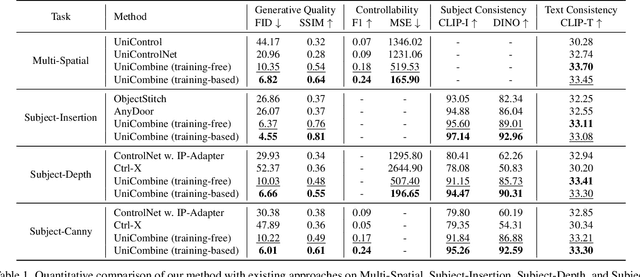
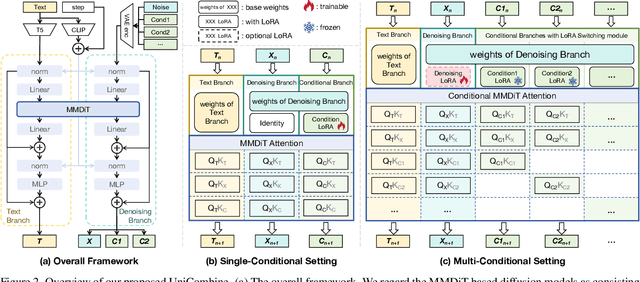
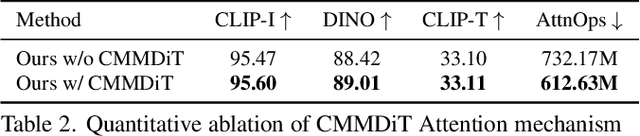
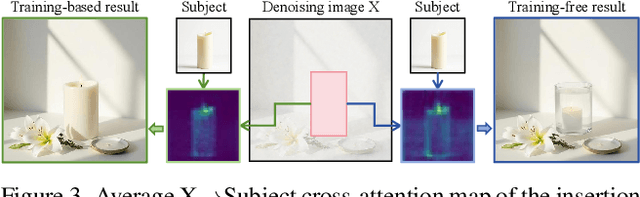
With the rapid development of diffusion models in image generation, the demand for more powerful and flexible controllable frameworks is increasing. Although existing methods can guide generation beyond text prompts, the challenge of effectively combining multiple conditional inputs while maintaining consistency with all of them remains unsolved. To address this, we introduce UniCombine, a DiT-based multi-conditional controllable generative framework capable of handling any combination of conditions, including but not limited to text prompts, spatial maps, and subject images. Specifically, we introduce a novel Conditional MMDiT Attention mechanism and incorporate a trainable LoRA module to build both the training-free and training-based versions. Additionally, we propose a new pipeline to construct SubjectSpatial200K, the first dataset designed for multi-conditional generative tasks covering both the subject-driven and spatially-aligned conditions. Extensive experimental results on multi-conditional generation demonstrate the outstanding universality and powerful capability of our approach with state-of-the-art performance.
PixelPonder: Dynamic Patch Adaptation for Enhanced Multi-Conditional Text-to-Image Generation
Mar 09, 2025Recent advances in diffusion-based text-to-image generation have demonstrated promising results through visual condition control. However, existing ControlNet-like methods struggle with compositional visual conditioning - simultaneously preserving semantic fidelity across multiple heterogeneous control signals while maintaining high visual quality, where they employ separate control branches that often introduce conflicting guidance during the denoising process, leading to structural distortions and artifacts in generated images. To address this issue, we present PixelPonder, a novel unified control framework, which allows for effective control of multiple visual conditions under a single control structure. Specifically, we design a patch-level adaptive condition selection mechanism that dynamically prioritizes spatially relevant control signals at the sub-region level, enabling precise local guidance without global interference. Additionally, a time-aware control injection scheme is deployed to modulate condition influence according to denoising timesteps, progressively transitioning from structural preservation to texture refinement and fully utilizing the control information from different categories to promote more harmonious image generation. Extensive experiments demonstrate that PixelPonder surpasses previous methods across different benchmark datasets, showing superior improvement in spatial alignment accuracy while maintaining high textual semantic consistency.
Frequency-Aware Re-Parameterization for Over-Fitting Based Image Compression
Oct 12, 2023



Over-fitting-based image compression requires weights compactness for compression and fast convergence for practical use, posing challenges for deep convolutional neural networks (CNNs) based methods. This paper presents a simple re-parameterization method to train CNNs with reduced weights storage and accelerated convergence. The convolution kernels are re-parameterized as a weighted sum of discrete cosine transform (DCT) kernels enabling direct optimization in the frequency domain. Combined with L1 regularization, the proposed method surpasses vanilla convolutions by achieving a significantly improved rate-distortion with low computational cost. The proposed method is verified with extensive experiments of over-fitting-based image restoration on various datasets, achieving up to -46.12% BD-rate on top of HEIF with only 200 iterations.