 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePreview WB-DH: Towards Whole Body Digital Human Bench for the Generation of Whole-body Talking Avatar Videos
Aug 12, 2025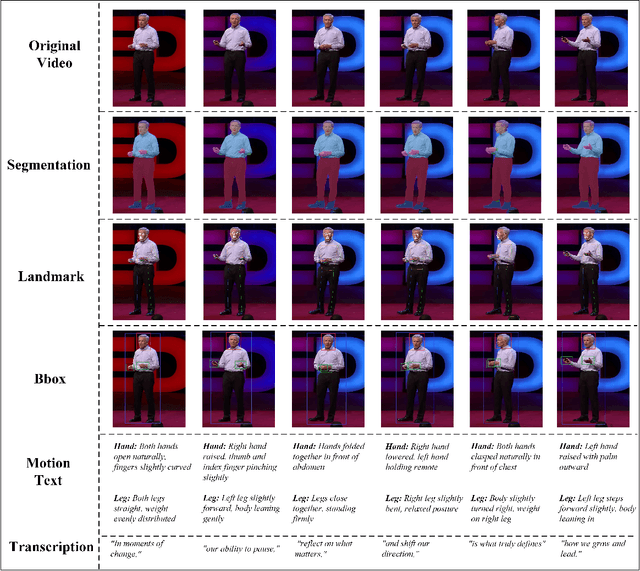


Creating realistic, fully animatable whole-body avatars from a single portrait is challenging due to limitations in capturing subtle expressions, body movements, and dynamic backgrounds. Current evaluation datasets and metrics fall short in addressing these complexities. To bridge this gap, we introduce the Whole-Body Benchmark Dataset (WB-DH), an open-source, multi-modal benchmark designed for evaluating whole-body animatable avatar generation. Key features include: (1) detailed multi-modal annotations for fine-grained guidance, (2) a versatile evaluation framework, and (3) public access to the dataset and tools at https://github.com/deepreasonings/WholeBodyBenchmark.
Reasoning to Edit: Hypothetical Instruction-Based Image Editing with Visual Reasoning
Jul 02, 2025Instruction-based image editing (IIE) has advanced rapidly with the success of diffusion models. However, existing efforts primarily focus on simple and explicit instructions to execute editing operations such as adding, deleting, moving, or swapping objects. They struggle to handle more complex implicit hypothetical instructions that require deeper reasoning to infer plausible visual changes and user intent. Additionally, current datasets provide limited support for training and evaluating reasoning-aware editing capabilities. Architecturally, these methods also lack mechanisms for fine-grained detail extraction that support such reasoning. To address these limitations, we propose Reason50K, a large-scale dataset specifically curated for training and evaluating hypothetical instruction reasoning image editing, along with ReasonBrain, a novel framework designed to reason over and execute implicit hypothetical instructions across diverse scenarios. Reason50K includes over 50K samples spanning four key reasoning scenarios: Physical, Temporal, Causal, and Story reasoning. ReasonBrain leverages Multimodal Large Language Models (MLLMs) for editing guidance generation and a diffusion model for image synthesis, incorporating a Fine-grained Reasoning Cue Extraction (FRCE) module to capture detailed visual and textual semantics essential for supporting instruction reasoning. To mitigate the semantic loss, we further introduce a Cross-Modal Enhancer (CME) that enables rich interactions between the fine-grained cues and MLLM-derived features. Extensive experiments demonstrate that ReasonBrain consistently outperforms state-of-the-art baselines on reasoning scenarios while exhibiting strong zero-shot generalization to conventional IIE tasks. Our dataset and code will be released publicly.
Towards Film-Making Production Dialogue, Narration, Monologue Adaptive Moving Dubbing Benchmarks
Apr 30, 2025Movie dubbing has advanced significantly, yet assessing the real-world effectiveness of these models remains challenging. A comprehensive evaluation benchmark is crucial for two key reasons: 1) Existing metrics fail to fully capture the complexities of dialogue, narration, monologue, and actor adaptability in movie dubbing. 2) A practical evaluation system should offer valuable insights to improve movie dubbing quality and advancement in film production. To this end, we introduce Talking Adaptive Dubbing Benchmarks (TA-Dubbing), designed to improve film production by adapting to dialogue, narration, monologue, and actors in movie dubbing. TA-Dubbing offers several key advantages: 1) Comprehensive Dimensions: TA-Dubbing covers a variety of dimensions of movie dubbing, incorporating metric evaluations for both movie understanding and speech generation. 2) Versatile Benchmarking: TA-Dubbing is designed to evaluate state-of-the-art movie dubbing models and advanced multi-modal large language models. 3) Full Open-Sourcing: We fully open-source TA-Dubbing at https://github.com/woka- 0a/DeepDubber- V1 including all video suits, evaluation methods, annotations. We also continuously integrate new movie dubbing models into the TA-Dubbing leaderboard at https://github.com/woka- 0a/DeepDubber-V1 to drive forward the field of movie dubbing.
OCC-MLLM-CoT-Alpha: Towards Multi-stage Occlusion Recognition Based on Large Language Models via 3D-Aware Supervision and Chain-of-Thoughts Guidance
Apr 07, 2025


Comprehending occluded objects are not well studied in existing large-scale visual-language multi-modal models. Current state-of-the-art multi-modal large models struggles to provide satisfactory results in understanding occluded objects through universal visual encoders and supervised learning strategies. Therefore, we propose OCC-MLLM-CoT-Alpha, a multi-modal large vision language framework that integrates 3D-aware supervision and Chain-of-Thoughts guidance. Particularly, (1) we build a multi-modal large vision-language model framework which is consisted of a large multi-modal vision-language model and a 3D reconstruction expert model. (2) the corresponding multi-modal Chain-of-Thoughts is learned through a combination of supervised and reinforcement training strategies, allowing the multi-modal vision-language model to enhance the recognition ability with learned multi-modal chain-of-thoughts guidance. (3) A large-scale multi-modal chain-of-thoughts reasoning dataset, consisting of $110k$ samples of occluded objects held in hand, is built. In the evaluation, the proposed methods demonstrate decision score improvement of 15.75%,15.30%,16.98%,14.62%, and 4.42%,3.63%,6.94%,10.70% for two settings of a variety of state-of-the-art models.
PixelPonder: Dynamic Patch Adaptation for Enhanced Multi-Conditional Text-to-Image Generation
Mar 09, 2025Recent advances in diffusion-based text-to-image generation have demonstrated promising results through visual condition control. However, existing ControlNet-like methods struggle with compositional visual conditioning - simultaneously preserving semantic fidelity across multiple heterogeneous control signals while maintaining high visual quality, where they employ separate control branches that often introduce conflicting guidance during the denoising process, leading to structural distortions and artifacts in generated images. To address this issue, we present PixelPonder, a novel unified control framework, which allows for effective control of multiple visual conditions under a single control structure. Specifically, we design a patch-level adaptive condition selection mechanism that dynamically prioritizes spatially relevant control signals at the sub-region level, enabling precise local guidance without global interference. Additionally, a time-aware control injection scheme is deployed to modulate condition influence according to denoising timesteps, progressively transitioning from structural preservation to texture refinement and fully utilizing the control information from different categories to promote more harmonious image generation. Extensive experiments demonstrate that PixelPonder surpasses previous methods across different benchmark datasets, showing superior improvement in spatial alignment accuracy while maintaining high textual semantic consistency.
Bilateral Guided Radiance Field Processing
Jun 01, 2024
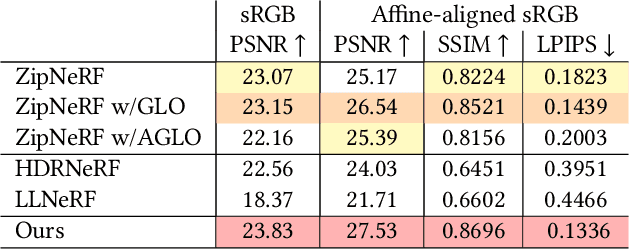

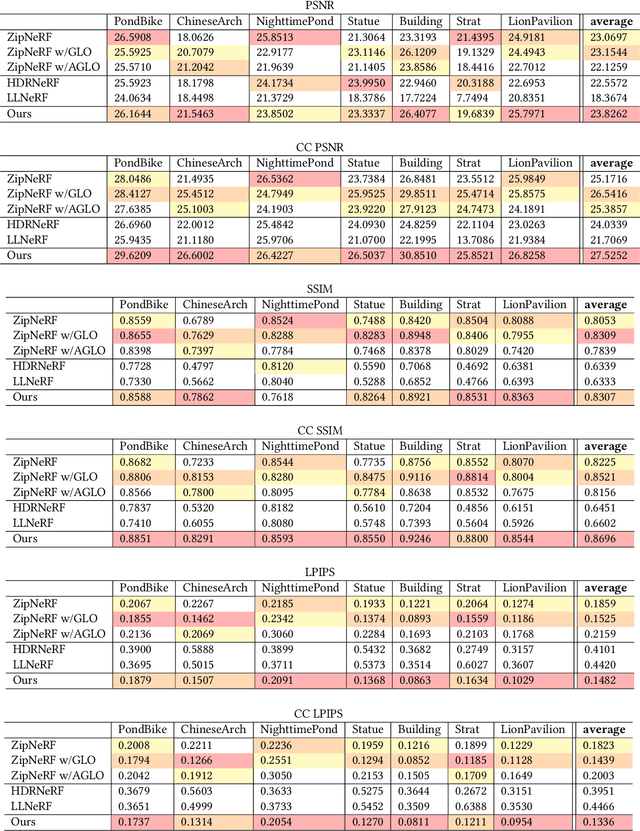
Neural Radiance Fields (NeRF) achieves unprecedented performance in synthesizing novel view synthesis, utilizing multi-view consistency. When capturing multiple inputs, image signal processing (ISP) in modern cameras will independently enhance them, including exposure adjustment, color correction, local tone mapping, etc. While these processings greatly improve image quality, they often break the multi-view consistency assumption, leading to "floaters" in the reconstructed radiance fields. To address this concern without compromising visual aesthetics, we aim to first disentangle the enhancement by ISP at the NeRF training stage and re-apply user-desired enhancements to the reconstructed radiance fields at the finishing stage. Furthermore, to make the re-applied enhancements consistent between novel views, we need to perform imaging signal processing in 3D space (i.e. "3D ISP"). For this goal, we adopt the bilateral grid, a locally-affine model, as a generalized representation of ISP processing. Specifically, we optimize per-view 3D bilateral grids with radiance fields to approximate the effects of camera pipelines for each input view. To achieve user-adjustable 3D finishing, we propose to learn a low-rank 4D bilateral grid from a given single view edit, lifting photo enhancements to the whole 3D scene. We demonstrate our approach can boost the visual quality of novel view synthesis by effectively removing floaters and performing enhancements from user retouching. The source code and our data are available at: https://bilarfpro.github.io.
Video Generation with Consistency Tuning
Mar 11, 2024


Currently, various studies have been exploring generation of long videos. However, the generated frames in these videos often exhibit jitter and noise. Therefore, in order to generate the videos without these noise, we propose a novel framework composed of four modules: separate tuning module, average fusion module, combined tuning module, and inter-frame consistency module. By applying our newly proposed modules subsequently, the consistency of the background and foreground in each video frames is optimized. Besides, the experimental results demonstrate that videos generated by our method exhibit a high quality in comparison of the state-of-the-art methods.