 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeR2-SVC: Towards Real-World Robust and Expressive Zero-shot Singing Voice Conversion
Oct 23, 2025In real-world singing voice conversion (SVC) applications, environmental noise and the demand for expressive output pose significant challenges. Conventional methods, however, are typically designed without accounting for real deployment scenarios, as both training and inference usually rely on clean data. This mismatch hinders practical use, given the inevitable presence of diverse noise sources and artifacts from music separation. To tackle these issues, we propose R2-SVC, a robust and expressive SVC framework. First, we introduce simulation-based robustness enhancement through random fundamental frequency ($F_0$) perturbations and music separation artifact simulations (e.g., reverberation, echo), substantially improving performance under noisy conditions. Second, we enrich speaker representation using domain-specific singing data: alongside clean vocals, we incorporate DNSMOS-filtered separated vocals and public singing corpora, enabling the model to preserve speaker timbre while capturing singing style nuances. Third, we integrate the Neural Source-Filter (NSF) model to explicitly represent harmonic and noise components, enhancing the naturalness and controllability of converted singing. R2-SVC achieves state-of-the-art results on multiple SVC benchmarks under both clean and noisy conditions.
Towards Video to Piano Music Generation with Chain-of-Perform Support Benchmarks
May 26, 2025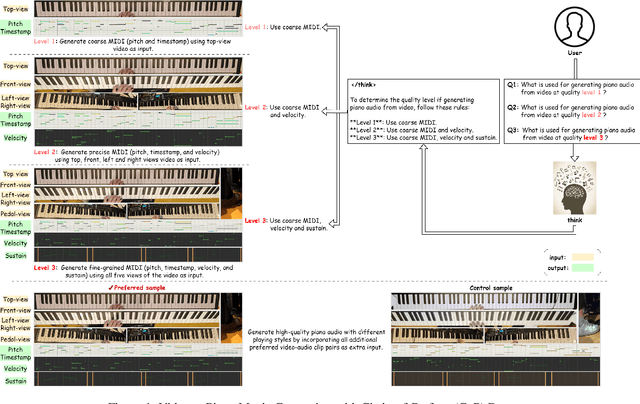
Generating high-quality piano audio from video requires precise synchronization between visual cues and musical output, ensuring accurate semantic and temporal alignment.However, existing evaluation datasets do not fully capture the intricate synchronization required for piano music generation. A comprehensive benchmark is essential for two primary reasons: (1) existing metrics fail to reflect the complexity of video-to-piano music interactions, and (2) a dedicated benchmark dataset can provide valuable insights to accelerate progress in high-quality piano music generation. To address these challenges, we introduce the CoP Benchmark Dataset-a fully open-sourced, multimodal benchmark designed specifically for video-guided piano music generation. The proposed Chain-of-Perform (CoP) benchmark offers several compelling features: (1) detailed multimodal annotations, enabling precise semantic and temporal alignment between video content and piano audio via step-by-step Chain-of-Perform guidance; (2) a versatile evaluation framework for rigorous assessment of both general-purpose and specialized video-to-piano generation tasks; and (3) full open-sourcing of the dataset, annotations, and evaluation protocols. The dataset is publicly available at https://github.com/acappemin/Video-to-Audio-and-Piano, with a continuously updated leaderboard to promote ongoing research in this domain.
MM-MovieDubber: Towards Multi-Modal Learning for Multi-Modal Movie Dubbing
May 22, 2025Current movie dubbing technology can produce the desired speech using a reference voice and input video, maintaining perfect synchronization with the visuals while effectively conveying the intended emotions. However, crucial aspects of movie dubbing, including adaptation to various dubbing styles, effective handling of dialogue, narration, and monologues, as well as consideration of subtle details such as speaker age and gender, remain insufficiently explored. To tackle these challenges, we introduce a multi-modal generative framework. First, it utilizes a multi-modal large vision-language model (VLM) to analyze visual inputs, enabling the recognition of dubbing types and fine-grained attributes. Second, it produces high-quality dubbing using large speech generation models, guided by multi-modal inputs. Additionally, a movie dubbing dataset with annotations for dubbing types and subtle details is constructed to enhance movie understanding and improve dubbing quality for the proposed multi-modal framework. Experimental results across multiple benchmark datasets show superior performance compared to state-of-the-art (SOTA) methods. In details, the LSE-D, SPK-SIM, EMO-SIM, and MCD exhibit improvements of up to 1.09%, 8.80%, 19.08%, and 18.74%, respectively.
Towards Film-Making Production Dialogue, Narration, Monologue Adaptive Moving Dubbing Benchmarks
Apr 30, 2025Movie dubbing has advanced significantly, yet assessing the real-world effectiveness of these models remains challenging. A comprehensive evaluation benchmark is crucial for two key reasons: 1) Existing metrics fail to fully capture the complexities of dialogue, narration, monologue, and actor adaptability in movie dubbing. 2) A practical evaluation system should offer valuable insights to improve movie dubbing quality and advancement in film production. To this end, we introduce Talking Adaptive Dubbing Benchmarks (TA-Dubbing), designed to improve film production by adapting to dialogue, narration, monologue, and actors in movie dubbing. TA-Dubbing offers several key advantages: 1) Comprehensive Dimensions: TA-Dubbing covers a variety of dimensions of movie dubbing, incorporating metric evaluations for both movie understanding and speech generation. 2) Versatile Benchmarking: TA-Dubbing is designed to evaluate state-of-the-art movie dubbing models and advanced multi-modal large language models. 3) Full Open-Sourcing: We fully open-source TA-Dubbing at https://github.com/woka- 0a/DeepDubber- V1 including all video suits, evaluation methods, annotations. We also continuously integrate new movie dubbing models into the TA-Dubbing leaderboard at https://github.com/woka- 0a/DeepDubber-V1 to drive forward the field of movie dubbing.
DeepDubber-V1: Towards High Quality and Dialogue, Narration, Monologue Adaptive Movie Dubbing Via Multi-Modal Chain-of-Thoughts Reasoning Guidance
Mar 31, 2025Current movie dubbing technology can generate the desired voice from a given speech prompt, ensuring good synchronization between speech and visuals while accurately conveying the intended emotions. However, in movie dubbing, key aspects such as adapting to different dubbing styles, handling dialogue, narration, and monologue effectively, and understanding subtle details like the age and gender of speakers, have not been well studied. To address this challenge, we propose a framework of multi-modal large language model. First, it utilizes multimodal Chain-of-Thought (CoT) reasoning methods on visual inputs to understand dubbing styles and fine-grained attributes. Second, it generates high-quality dubbing through large speech generation models, guided by multimodal conditions. Additionally, we have developed a movie dubbing dataset with CoT annotations. The evaluation results demonstrate a performance improvement over state-of-the-art methods across multiple datasets. In particular, for the evaluation metrics, the SPK-SIM and EMO-SIM increases from 82.48% to 89.74%, 66.24% to 78.88% for dubbing setting 2.0 on V2C Animation dataset, LSE-D and MCD-SL decreases from 14.79 to 14.63, 5.24 to 4.74 for dubbing setting 2.0 on Grid dataset, SPK-SIM increases from 64.03 to 83.42 and WER decreases from 52.69% to 23.20% for initial reasoning setting on proposed CoT-Movie-Dubbing dataset in the comparison with the state-of-the art models.
DeepSound-V1: Start to Think Step-by-Step in the Audio Generation from Videos
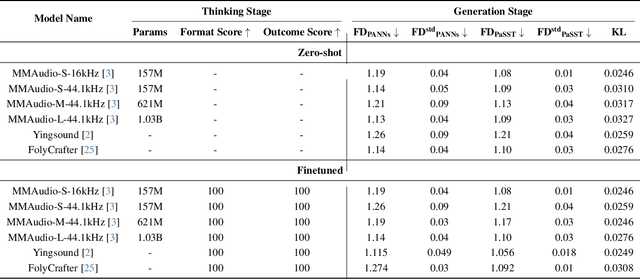
Mar 28, 2025Currently, high-quality, synchronized audio is synthesized from video and optional text inputs using various multi-modal joint learning frameworks. However, the precise alignment between the visual and generated audio domains remains far from satisfactory. One key factor is the lack of sufficient temporal and semantic alignment annotations in open-source video-audio and text-audio benchmarks. Therefore, we propose a framework for audio generation from videos, leveraging the internal chain-of-thought (CoT) of a multi-modal large language model (MLLM) to enable step-by-step reasoning without requiring additional annotations. Additionally, a corresponding multi-modal reasoning dataset is constructed to facilitate the learning of initial reasoning in audio generation. In the experiments, we demonstrate the effectiveness of the proposed framework in reducing misalignment (voice-over) in generated audio and achieving competitive performance compared to various state-of-the-art models. The evaluation results show that the proposed method outperforms state-of-the-art approaches across multiple metrics. Specifically, the F DP aSST indicator is reduced by up to 10.07%, the F DP AN N s indicator by up to 11.62%, and the F DV GG indicator by up to 38.61%. Furthermore, the IS indicator improves by up to 4.95%, the IB-score indicator increases by up to 6.39%, and the DeSync indicator is reduced by up to 0.89%.
DeepAudio-V1:Towards Multi-Modal Multi-Stage End-to-End Video to Speech and Audio Generation
Mar 28, 2025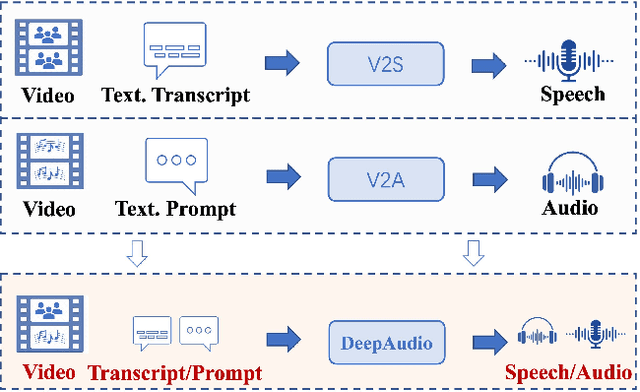
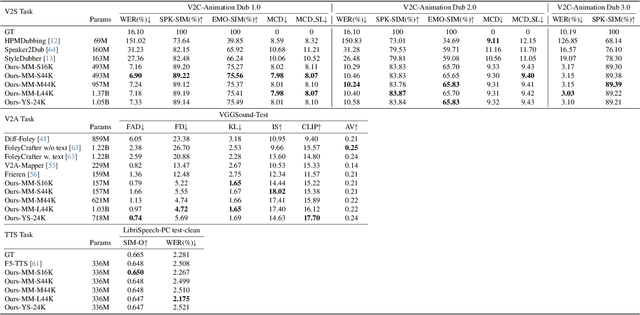
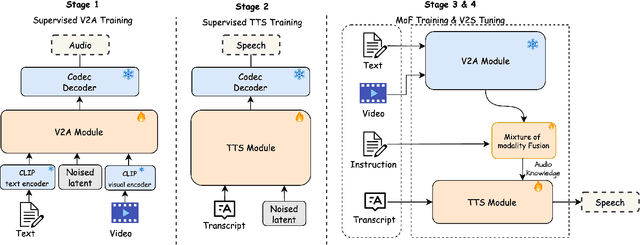

Currently, high-quality, synchronized audio is synthesized using various multi-modal joint learning frameworks, leveraging video and optional text inputs. In the video-to-audio benchmarks, video-to-audio quality, semantic alignment, and audio-visual synchronization are effectively achieved. However, in real-world scenarios, speech and audio often coexist in videos simultaneously, and the end-to-end generation of synchronous speech and audio given video and text conditions are not well studied. Therefore, we propose an end-to-end multi-modal generation framework that simultaneously produces speech and audio based on video and text conditions. Furthermore, the advantages of video-to-audio (V2A) models for generating speech from videos remain unclear. The proposed framework, DeepAudio, consists of a video-to-audio (V2A) module, a text-to-speech (TTS) module, and a dynamic mixture of modality fusion (MoF) module. In the evaluation, the proposed end-to-end framework achieves state-of-the-art performance on the video-audio benchmark, video-speech benchmark, and text-speech benchmark. In detail, our framework achieves comparable results in the comparison with state-of-the-art models for the video-audio and text-speech benchmarks, and surpassing state-of-the-art models in the video-speech benchmark, with WER 16.57% to 3.15% (+80.99%), SPK-SIM 78.30% to 89.38% (+14.15%), EMO-SIM 66.24% to 75.56% (+14.07%), MCD 8.59 to 7.98 (+7.10%), MCD SL 11.05 to 9.40 (+14.93%) across a variety of dubbing settings.
Enhance Generation Quality of Flow Matching V2A Model via Multi-Step CoT-Like Guidance and Combined Preference Optimization
Mar 28, 2025Creating high-quality sound effects from videos and text prompts requires precise alignment between visual and audio domains, both semantically and temporally, along with step-by-step guidance for professional audio generation. However, current state-of-the-art video-guided audio generation models often fall short of producing high-quality audio for both general and specialized use cases. To address this challenge, we introduce a multi-stage, multi-modal, end-to-end generative framework with Chain-of-Thought-like (CoT-like) guidance learning, termed Chain-of-Perform (CoP). First, we employ a transformer-based network architecture designed to achieve CoP guidance, enabling the generation of both general and professional audio. Second, we implement a multi-stage training framework that follows step-by-step guidance to ensure the generation of high-quality sound effects. Third, we develop a CoP multi-modal dataset, guided by video, to support step-by-step sound effects generation. Evaluation results highlight the advantages of the proposed multi-stage CoP generative framework compared to the state-of-the-art models on a variety of datasets, with FAD 0.79 to 0.74 (+6.33%), CLIP 16.12 to 17.70 (+9.80%) on VGGSound, SI-SDR 1.98dB to 3.35dB (+69.19%), MOS 2.94 to 3.49(+18.71%) on PianoYT-2h, and SI-SDR 2.22dB to 3.21dB (+44.59%), MOS 3.07 to 3.42 (+11.40%) on Piano-10h.
Enhancing Reasoning through Process Supervision with Monte Carlo Tree Search
Jan 02, 2025


Large language models (LLMs) have demonstrated their remarkable capacity across a variety of tasks. However, reasoning remains a challenge for LLMs. To improve LLMs' reasoning ability, process supervision has proven to be better than outcome supervision. In this work, we study using Monte Carlo Tree Search (MCTS) to generate process supervision data with LLMs themselves for training them. We sample reasoning steps with an LLM and assign each step a score that captures its "relative correctness," and the LLM is then trained by minimizing weighted log-likelihood of generating the reasoning steps. This generate-then-train process is repeated iteratively until convergence.Our experimental results demonstrate that the proposed methods considerably improve the performance of LLMs on two mathematical reasoning datasets. Furthermore, models trained on one dataset also exhibit improved performance on the other, showing the transferability of the enhanced reasoning ability.
Towards Intrinsic Self-Correction Enhancement in Monte Carlo Tree Search Boosted Reasoning via Iterative Preference Learning
Dec 23, 2024



With current state-of-the-art approaches aimed at enhancing the reasoning capabilities of Large Language Models(LLMs) through iterative preference learning inspired by AlphaZero, we propose to further enhance the step-wise reasoning capabilities through intrinsic self-correction to some extent. Our work leverages step-wise preference learning to enhance self-verification via reinforcement learning. We initially conduct our work through a two-stage training procedure. At the first stage, the self-correction reasoning ability of an LLM is enhanced through its own predictions, relying entirely on self-generated data within the intrinsic self-correction to some extent. At the second stage, the baseline step-wise preference learning is leveraged via the application of the enhanced self-correct policy achieved at the first stage. In the evaluation of arithmetic reasoning tasks, our approach outperforms OpenMath2-Llama3.1-8B, dart-math-mistral-7b-uniform on MATH with increases in accuracy to 71.34%(+4.18%) and 48.06%(+4.94%) and LLama-3.1-8B-Instruct, Mistral-7B-Instruct-v0.1 on GSM8K with increases in accuracy to 86.76%(+2.00%) and 38.06%(+2.28%).