 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Video to Piano Music Generation with Chain-of-Perform Support Benchmarks
May 26, 2025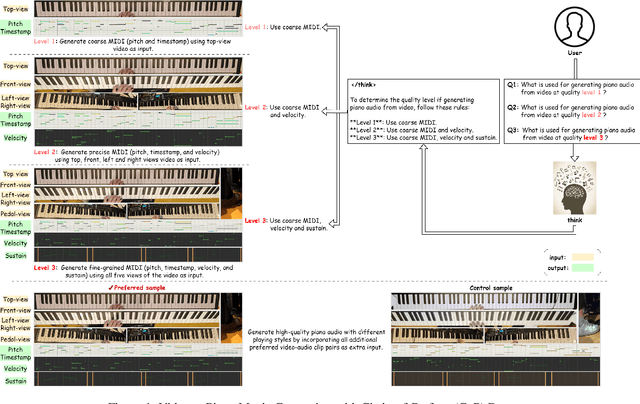
Generating high-quality piano audio from video requires precise synchronization between visual cues and musical output, ensuring accurate semantic and temporal alignment.However, existing evaluation datasets do not fully capture the intricate synchronization required for piano music generation. A comprehensive benchmark is essential for two primary reasons: (1) existing metrics fail to reflect the complexity of video-to-piano music interactions, and (2) a dedicated benchmark dataset can provide valuable insights to accelerate progress in high-quality piano music generation. To address these challenges, we introduce the CoP Benchmark Dataset-a fully open-sourced, multimodal benchmark designed specifically for video-guided piano music generation. The proposed Chain-of-Perform (CoP) benchmark offers several compelling features: (1) detailed multimodal annotations, enabling precise semantic and temporal alignment between video content and piano audio via step-by-step Chain-of-Perform guidance; (2) a versatile evaluation framework for rigorous assessment of both general-purpose and specialized video-to-piano generation tasks; and (3) full open-sourcing of the dataset, annotations, and evaluation protocols. The dataset is publicly available at https://github.com/acappemin/Video-to-Audio-and-Piano, with a continuously updated leaderboard to promote ongoing research in this domain.
Enhance Generation Quality of Flow Matching V2A Model via Multi-Step CoT-Like Guidance and Combined Preference Optimization
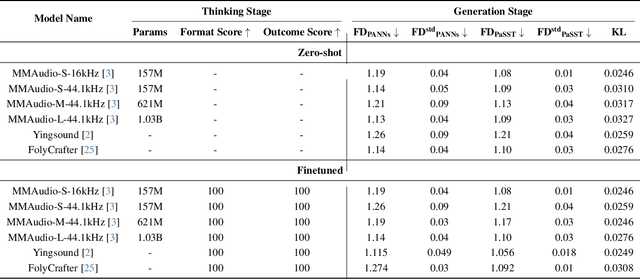
Mar 28, 2025Creating high-quality sound effects from videos and text prompts requires precise alignment between visual and audio domains, both semantically and temporally, along with step-by-step guidance for professional audio generation. However, current state-of-the-art video-guided audio generation models often fall short of producing high-quality audio for both general and specialized use cases. To address this challenge, we introduce a multi-stage, multi-modal, end-to-end generative framework with Chain-of-Thought-like (CoT-like) guidance learning, termed Chain-of-Perform (CoP). First, we employ a transformer-based network architecture designed to achieve CoP guidance, enabling the generation of both general and professional audio. Second, we implement a multi-stage training framework that follows step-by-step guidance to ensure the generation of high-quality sound effects. Third, we develop a CoP multi-modal dataset, guided by video, to support step-by-step sound effects generation. Evaluation results highlight the advantages of the proposed multi-stage CoP generative framework compared to the state-of-the-art models on a variety of datasets, with FAD 0.79 to 0.74 (+6.33%), CLIP 16.12 to 17.70 (+9.80%) on VGGSound, SI-SDR 1.98dB to 3.35dB (+69.19%), MOS 2.94 to 3.49(+18.71%) on PianoYT-2h, and SI-SDR 2.22dB to 3.21dB (+44.59%), MOS 3.07 to 3.42 (+11.40%) on Piano-10h.
DeepAudio-V1:Towards Multi-Modal Multi-Stage End-to-End Video to Speech and Audio Generation
Mar 28, 2025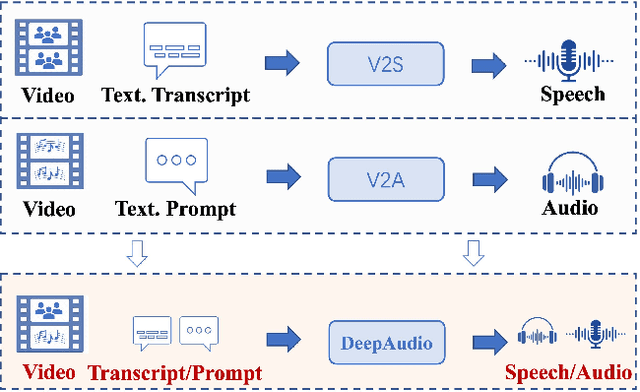
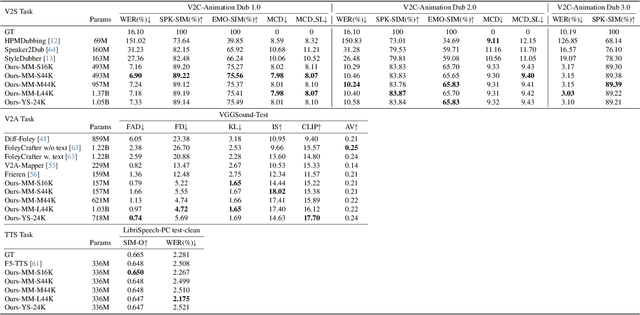
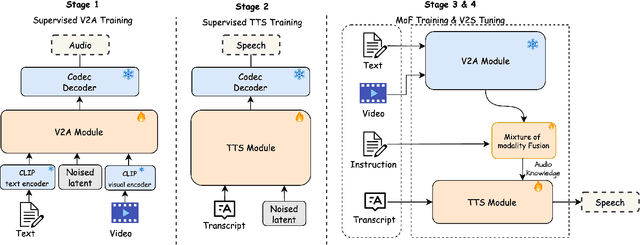

Currently, high-quality, synchronized audio is synthesized using various multi-modal joint learning frameworks, leveraging video and optional text inputs. In the video-to-audio benchmarks, video-to-audio quality, semantic alignment, and audio-visual synchronization are effectively achieved. However, in real-world scenarios, speech and audio often coexist in videos simultaneously, and the end-to-end generation of synchronous speech and audio given video and text conditions are not well studied. Therefore, we propose an end-to-end multi-modal generation framework that simultaneously produces speech and audio based on video and text conditions. Furthermore, the advantages of video-to-audio (V2A) models for generating speech from videos remain unclear. The proposed framework, DeepAudio, consists of a video-to-audio (V2A) module, a text-to-speech (TTS) module, and a dynamic mixture of modality fusion (MoF) module. In the evaluation, the proposed end-to-end framework achieves state-of-the-art performance on the video-audio benchmark, video-speech benchmark, and text-speech benchmark. In detail, our framework achieves comparable results in the comparison with state-of-the-art models for the video-audio and text-speech benchmarks, and surpassing state-of-the-art models in the video-speech benchmark, with WER 16.57% to 3.15% (+80.99%), SPK-SIM 78.30% to 89.38% (+14.15%), EMO-SIM 66.24% to 75.56% (+14.07%), MCD 8.59 to 7.98 (+7.10%), MCD SL 11.05 to 9.40 (+14.93%) across a variety of dubbing settings.
Multiple Consistency-guided Test-Time Adaptation for Contrastive Audio-Language Models with Unlabeled Audio
Dec 23, 2024



One fascinating aspect of pre-trained Audio-Language Models (ALMs) learning is their impressive zero-shot generalization capability and test-time adaptation (TTA) methods aiming to improve domain performance without annotations. However, previous test time adaptation (TTA) methods for ALMs in zero-shot classification tend to be stuck in incorrect model predictions. In order to further boost the performance, we propose multiple guidance on prompt learning without annotated labels. First, guidance of consistency on both context tokens and domain tokens of ALMs is set. Second, guidance of both consistency across multiple augmented views of each single test sample and contrastive learning across different test samples is set. Third, we propose a corresponding end-end learning framework for the proposed test-time adaptation method without annotated labels. We extensively evaluate our approach on 12 downstream tasks across domains, our proposed adaptation method leads to 4.41% (max 7.50%) average zero-shot performance improvement in comparison with the state-of-the-art models.
YingSound: Video-Guided Sound Effects Generation with Multi-modal Chain-of-Thought Controls
Dec 12, 2024



Generating sound effects for product-level videos, where only a small amount of labeled data is available for diverse scenes, requires the production of high-quality sounds in few-shot settings. To tackle the challenge of limited labeled data in real-world scenes, we introduce YingSound, a foundation model designed for video-guided sound generation that supports high-quality audio generation in few-shot settings. Specifically, YingSound consists of two major modules. The first module uses a conditional flow matching transformer to achieve effective semantic alignment in sound generation across audio and visual modalities. This module aims to build a learnable audio-visual aggregator (AVA) that integrates high-resolution visual features with corresponding audio features at multiple stages. The second module is developed with a proposed multi-modal visual-audio chain-of-thought (CoT) approach to generate finer sound effects in few-shot settings. Finally, an industry-standard video-to-audio (V2A) dataset that encompasses various real-world scenarios is presented. We show that YingSound effectively generates high-quality synchronized sounds across diverse conditional inputs through automated evaluations and human studies. Project Page: \url{https://giantailab.github.io/yingsound/}