 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntegrating Fine-Grained Audio-Visual Evidence for Robust Multimodal Emotion Reasoning
Jan 26, 2026Multimodal emotion analysis is shifting from static classification to generative reasoning. Beyond simple label prediction, robust affective reasoning must synthesize fine-grained signals such as facial micro-expressions and prosodic which shifts to decode the latent causality within complex social contexts. However, current Multimodal Large Language Models (MLLMs) face significant limitations in fine-grained perception, primarily due to data scarcity and insufficient cross-modal fusion. As a result, these models often exhibit unimodal dominance which leads to hallucinations in complex multimodal interactions, particularly when visual and acoustic cues are subtle, ambiguous, or even contradictory (e.g., in sarcastic scenery). To address this, we introduce SABER-LLM, a framework designed for robust multimodal reasoning. First, we construct SABER, a large-scale emotion reasoning dataset comprising 600K video clips, annotated with a novel six-dimensional schema that jointly captures audiovisual cues and causal logic. Second, we propose the structured evidence decomposition paradigm, which enforces a "perceive-then-reason" separation between evidence extraction and reasoning to alleviate unimodal dominance. The ability to perceive complex scenes is further reinforced by consistency-aware direct preference optimization, which explicitly encourages alignment among modalities under ambiguous or conflicting perceptual conditions. Experiments on EMER, EmoBench-M, and SABER-Test demonstrate that SABER-LLM significantly outperforms open-source baselines and achieves robustness competitive with closed-source models in decoding complex emotional dynamics. The dataset and model are available at https://github.com/zxzhao0/SABER-LLM.
dLLM-ASR: A Faster Diffusion LLM-based Framework for Speech Recognition
Jan 25, 2026Automatic speech recognition (ASR) systems based on large language models (LLMs) achieve superior performance by leveraging pretrained LLMs as decoders, but their token-by-token generation mechanism leads to inference latency that grows linearly with sequence length. Meanwhile, discrete diffusion large language models (dLLMs) offer a promising alternative, enabling high-quality parallel sequence generation with pretrained decoders. However, directly applying native text-oriented dLLMs to ASR leads to a fundamental mismatch between open-ended text generation and the acoustically conditioned transcription paradigm required by ASR. As a result, it introduces unnecessary difficulty and computational redundancy, such as denoising from pure noise, inflexible generation lengths, and fixed denoising steps. We propose dLLM-ASR, an efficient dLLM-based ASR framework that formulates dLLM's decoding as a prior-guided and adaptive denoising process. It leverages an ASR prior to initialize the denoising process and provide an anchor for sequence length. Building upon this prior, length-adaptive pruning dynamically removes redundant tokens, while confidence-based denoising allows converged tokens to exit the denoising loop early, enabling token-level adaptive computation. Experiments demonstrate that dLLM-ASR achieves recognition accuracy comparable to autoregressive LLM-based ASR systems and delivers a 4.44$\times$ inference speedup, establishing a practical and efficient paradigm for ASR.
VoiceSculptor: Your Voice, Designed By You
Jan 15, 2026Despite rapid progress in text-to-speech (TTS), open-source systems still lack truly instruction-following, fine-grained control over core speech attributes (e.g., pitch, speaking rate, age, emotion, and style). We present VoiceSculptor, an open-source unified system that bridges this gap by integrating instruction-based voice design and high-fidelity voice cloning in a single framework. It generates controllable speaker timbre directly from natural-language descriptions, supports iterative refinement via Retrieval-Augmented Generation (RAG), and provides attribute-level edits across multiple dimensions. The designed voice is then rendered into a prompt waveform and fed into a cloning model to enable high-fidelity timbre transfer for downstream speech synthesis. VoiceSculptor achieves open-source state-of-the-art (SOTA) on InstructTTSEval-Zh, and is fully open-sourced, including code and pretrained models, to advance reproducible instruction-controlled TTS research.
PodEval: A Multimodal Evaluation Framework for Podcast Audio Generation
Oct 01, 2025Recently, an increasing number of multimodal (text and audio) benchmarks have emerged, primarily focusing on evaluating models' understanding capability. However, exploration into assessing generative capabilities remains limited, especially for open-ended long-form content generation. Significant challenges lie in no reference standard answer, no unified evaluation metrics and uncontrollable human judgments. In this work, we take podcast-like audio generation as a starting point and propose PodEval, a comprehensive and well-designed open-source evaluation framework. In this framework: 1) We construct a real-world podcast dataset spanning diverse topics, serving as a reference for human-level creative quality. 2) We introduce a multimodal evaluation strategy and decompose the complex task into three dimensions: text, speech and audio, with different evaluation emphasis on "Content" and "Format". 3) For each modality, we design corresponding evaluation methods, involving both objective metrics and subjective listening test. We leverage representative podcast generation systems (including open-source, close-source, and human-made) in our experiments. The results offer in-depth analysis and insights into podcast generation, demonstrating the effectiveness of PodEval in evaluating open-ended long-form audio. This project is open-source to facilitate public use: https://github.com/yujxx/PodEval.
Llasa+: Free Lunch for Accelerated and Streaming Llama-Based Speech Synthesis
Aug 08, 2025Recent progress in text-to-speech (TTS) has achieved impressive naturalness and flexibility, especially with the development of large language model (LLM)-based approaches. However, existing autoregressive (AR) structures and large-scale models, such as Llasa, still face significant challenges in inference latency and streaming synthesis. To deal with the limitations, we introduce Llasa+, an accelerated and streaming TTS model built on Llasa. Specifically, to accelerate the generation process, we introduce two plug-and-play Multi-Token Prediction (MTP) modules following the frozen backbone. These modules allow the model to predict multiple tokens in one AR step. Additionally, to mitigate potential error propagation caused by inaccurate MTP, we design a novel verification algorithm that leverages the frozen backbone to validate the generated tokens, thus allowing Llasa+ to achieve speedup without sacrificing generation quality. Furthermore, we design a causal decoder that enables streaming speech reconstruction from tokens. Extensive experiments show that Llasa+ achieves a 1.48X speedup without sacrificing generation quality, despite being trained only on LibriTTS. Moreover, the MTP-and-verification framework can be applied to accelerate any LLM-based model. All codes and models are publicly available at https://github.com/ASLP-lab/LLaSA_Plus.
Steering Language Model to Stable Speech Emotion Recognition via Contextual Perception and Chain of Thought
Feb 25, 2025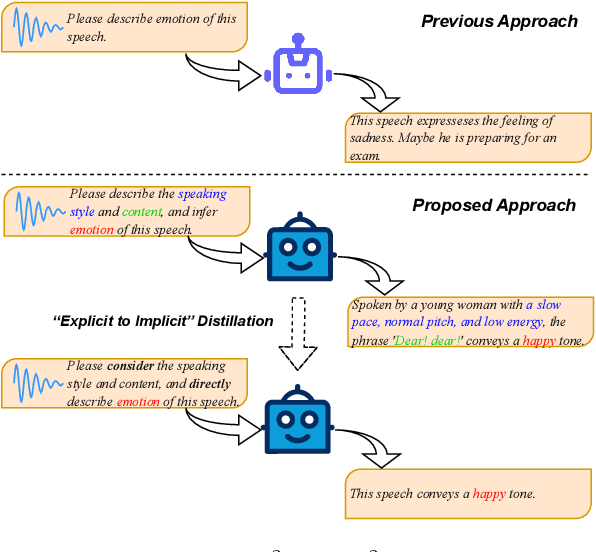


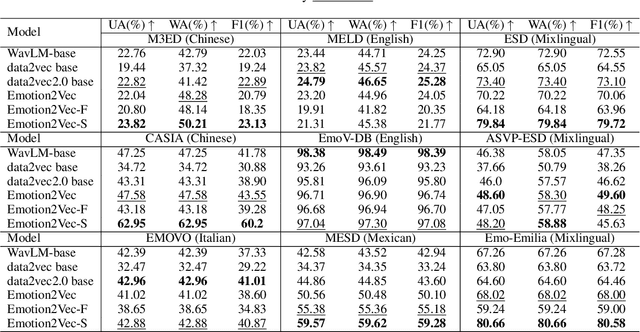
Large-scale audio language models (ALMs), such as Qwen2-Audio, are capable of comprehending diverse audio signal, performing audio analysis and generating textual responses. However, in speech emotion recognition (SER), ALMs often suffer from hallucinations, resulting in misclassifications or irrelevant outputs. To address these challenges, we propose C$^2$SER, a novel ALM designed to enhance the stability and accuracy of SER through Contextual perception and Chain of Thought (CoT). C$^2$SER integrates the Whisper encoder for semantic perception and Emotion2Vec-S for acoustic perception, where Emotion2Vec-S extends Emotion2Vec with semi-supervised learning to enhance emotional discrimination. Additionally, C$^2$SER employs a CoT approach, processing SER in a step-by-step manner while leveraging speech content and speaking styles to improve recognition. To further enhance stability, C$^2$SER introduces self-distillation from explicit CoT to implicit CoT, mitigating error accumulation and boosting recognition accuracy. Extensive experiments show that C$^2$SER outperforms existing popular ALMs, such as Qwen2-Audio and SECap, delivering more stable and precise emotion recognition. We release the training code, checkpoints, and test sets to facilitate further research.
CosyAudio: Improving Audio Generation with Confidence Scores and Synthetic Captions
Jan 28, 2025Text-to-Audio (TTA) generation is an emerging area within AI-generated content (AIGC), where audio is created from natural language descriptions. Despite growing interest, developing robust TTA models remains challenging due to the scarcity of well-labeled datasets and the prevalence of noisy or inaccurate captions in large-scale, weakly labeled corpora. To address these challenges, we propose CosyAudio, a novel framework that utilizes confidence scores and synthetic captions to enhance the quality of audio generation. CosyAudio consists of two core components: AudioCapTeller and an audio generator. AudioCapTeller generates synthetic captions for audio and provides confidence scores to evaluate their accuracy. The audio generator uses these synthetic captions and confidence scores to enable quality-aware audio generation. Additionally, we introduce a self-evolving training strategy that iteratively optimizes CosyAudio across both well-labeled and weakly-labeled datasets. Initially trained with well-labeled data, AudioCapTeller leverages its assessment capabilities on weakly-labeled datasets for high-quality filtering and reinforcement learning, which further improves its performance. The well-trained AudioCapTeller refines corpora by generating new captions and confidence scores, serving for the audio generator training. Extensive experiments on open-source datasets demonstrate that CosyAudio outperforms existing models in automated audio captioning, generates more faithful audio, and exhibits strong generalization across diverse scenarios.
Autoregressive Speech Synthesis with Next-Distribution Prediction
Dec 22, 2024



We introduce KALL-E, a novel autoregressive (AR) language modeling approach with next-distribution prediction for text-to-speech (TTS) synthesis. Unlike existing methods, KALL-E directly models and predicts the continuous speech distribution conditioned on text without relying on VAE- or diffusion-based components. Specifically, we use WaveVAE to extract continuous speech distributions from waveforms instead of using discrete speech tokens. A single AR language model predicts these continuous speech distributions from text, with a Kullback-Leibler divergence loss as the constraint. Experimental results show that KALL-E outperforms open-source implementations of YourTTS, VALL-E, NaturalSpeech 2, and CosyVoice in terms of naturalness and speaker similarity in zero-shot TTS scenarios. Moreover, KALL-E demonstrates exceptional zero-shot capabilities in emotion and accent cloning. Importantly, KALL-E presents a more straightforward and effective paradigm for using continuous speech representations in TTS. Audio samples are available at: \url{https://zxf-icpc.github.io/kalle/}.
YingSound: Video-Guided Sound Effects Generation with Multi-modal Chain-of-Thought Controls
Dec 12, 2024



Generating sound effects for product-level videos, where only a small amount of labeled data is available for diverse scenes, requires the production of high-quality sounds in few-shot settings. To tackle the challenge of limited labeled data in real-world scenes, we introduce YingSound, a foundation model designed for video-guided sound generation that supports high-quality audio generation in few-shot settings. Specifically, YingSound consists of two major modules. The first module uses a conditional flow matching transformer to achieve effective semantic alignment in sound generation across audio and visual modalities. This module aims to build a learnable audio-visual aggregator (AVA) that integrates high-resolution visual features with corresponding audio features at multiple stages. The second module is developed with a proposed multi-modal visual-audio chain-of-thought (CoT) approach to generate finer sound effects in few-shot settings. Finally, an industry-standard video-to-audio (V2A) dataset that encompasses various real-world scenarios is presented. We show that YingSound effectively generates high-quality synchronized sounds across diverse conditional inputs through automated evaluations and human studies. Project Page: \url{https://giantailab.github.io/yingsound/}
Text-aware and Context-aware Expressive Audiobook Speech Synthesis
Jun 12, 2024Recent advances in text-to-speech have significantly improved the expressiveness of synthetic speech. However, a major challenge remains in generating speech that captures the diverse styles exhibited by professional narrators in audiobooks without relying on manually labeled data or reference speech. To address this problem, we propose a text-aware and context-aware(TACA) style modeling approach for expressive audiobook speech synthesis. We first establish a text-aware style space to cover diverse styles via contrastive learning with the supervision of the speech style. Meanwhile, we adopt a context encoder to incorporate cross-sentence information and the style embedding obtained from text. Finally, we introduce the context encoder to two typical TTS models, VITS-based TTS and language model-based TTS. Experimental results demonstrate that our proposed approach can effectively capture diverse styles and coherent prosody, and consequently improves naturalness and expressiveness in audiobook speech synthesis.