 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgedLLM-ASR: A Faster Diffusion LLM-based Framework for Speech Recognition
Jan 25, 2026Automatic speech recognition (ASR) systems based on large language models (LLMs) achieve superior performance by leveraging pretrained LLMs as decoders, but their token-by-token generation mechanism leads to inference latency that grows linearly with sequence length. Meanwhile, discrete diffusion large language models (dLLMs) offer a promising alternative, enabling high-quality parallel sequence generation with pretrained decoders. However, directly applying native text-oriented dLLMs to ASR leads to a fundamental mismatch between open-ended text generation and the acoustically conditioned transcription paradigm required by ASR. As a result, it introduces unnecessary difficulty and computational redundancy, such as denoising from pure noise, inflexible generation lengths, and fixed denoising steps. We propose dLLM-ASR, an efficient dLLM-based ASR framework that formulates dLLM's decoding as a prior-guided and adaptive denoising process. It leverages an ASR prior to initialize the denoising process and provide an anchor for sequence length. Building upon this prior, length-adaptive pruning dynamically removes redundant tokens, while confidence-based denoising allows converged tokens to exit the denoising loop early, enabling token-level adaptive computation. Experiments demonstrate that dLLM-ASR achieves recognition accuracy comparable to autoregressive LLM-based ASR systems and delivers a 4.44$\times$ inference speedup, establishing a practical and efficient paradigm for ASR.
Selective Invocation for Multilingual ASR: A Cost-effective Approach Adapting to Speech Recognition Difficulty
May 22, 2025Although multilingual automatic speech recognition (ASR) systems have significantly advanced, enabling a single model to handle multiple languages, inherent linguistic differences and data imbalances challenge SOTA performance across all languages. While language identification (LID) models can route speech to the appropriate ASR model, they incur high costs from invoking SOTA commercial models and suffer from inaccuracies due to misclassification. To overcome these, we propose SIMA, a selective invocation for multilingual ASR that adapts to the difficulty level of the input speech. Built on a spoken large language model (SLLM), SIMA evaluates whether the input is simple enough for direct transcription or requires the invocation of a SOTA ASR model. Our approach reduces word error rates by 18.7% compared to the SLLM and halves invocation costs compared to LID-based methods. Tests on three datasets show that SIMA is a scalable, cost-effective solution for multilingual ASR applications.
Enhancing Non-Core Language Instruction-Following in Speech LLMs via Semi-Implicit Cross-Lingual CoT Reasoning
Apr 29, 2025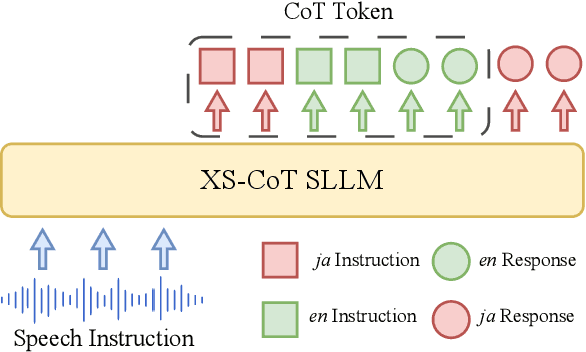
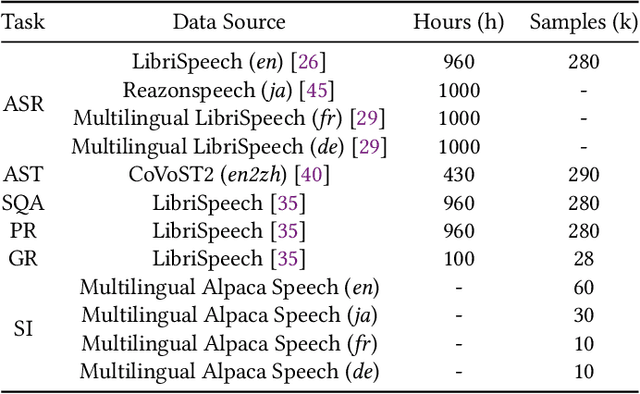
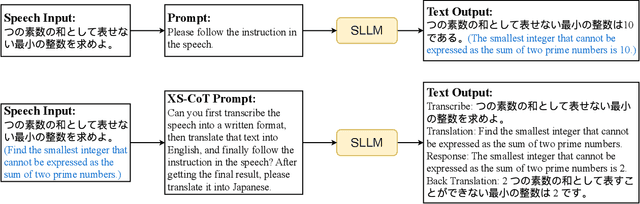

Large language models have been extended to the speech domain, leading to the development of speech large language models (SLLMs). While existing SLLMs demonstrate strong performance in speech instruction-following for core languages (e.g., English), they often struggle with non-core languages due to the scarcity of paired speech-text data and limited multilingual semantic reasoning capabilities. To address this, we propose the semi-implicit Cross-lingual Speech Chain-of-Thought (XS-CoT) framework, which integrates speech-to-text translation into the reasoning process of SLLMs. The XS-CoT generates four types of tokens: instruction and response tokens in both core and non-core languages, enabling cross-lingual transfer of reasoning capabilities. To mitigate inference latency in generating target non-core response tokens, we incorporate a semi-implicit CoT scheme into XS-CoT, which progressively compresses the first three types of intermediate reasoning tokens while retaining global reasoning logic during training. By leveraging the robust reasoning capabilities of the core language, XS-CoT improves responses for non-core languages by up to 45\% in GPT-4 score when compared to direct supervised fine-tuning on two representative SLLMs, Qwen2-Audio and SALMONN. Moreover, the semi-implicit XS-CoT reduces token delay by more than 50\% with a slight drop in GPT-4 scores. Importantly, XS-CoT requires only a small amount of high-quality training data for non-core languages by leveraging the reasoning capabilities of core languages. To support training, we also develop a data pipeline and open-source speech instruction-following datasets in Japanese, German, and French.
Steering Language Model to Stable Speech Emotion Recognition via Contextual Perception and Chain of Thought
Feb 25, 2025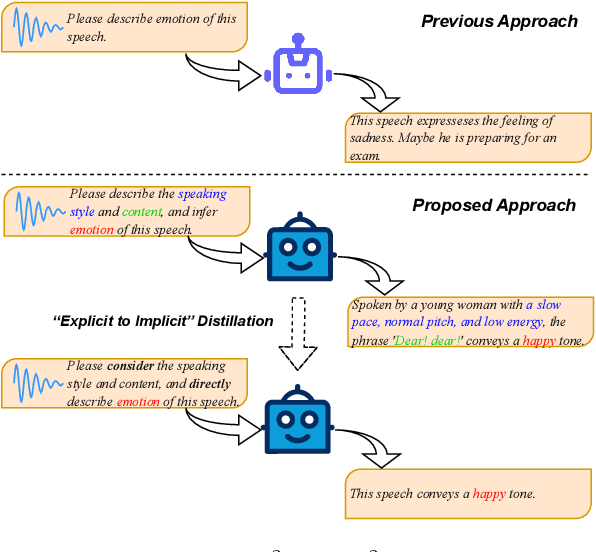


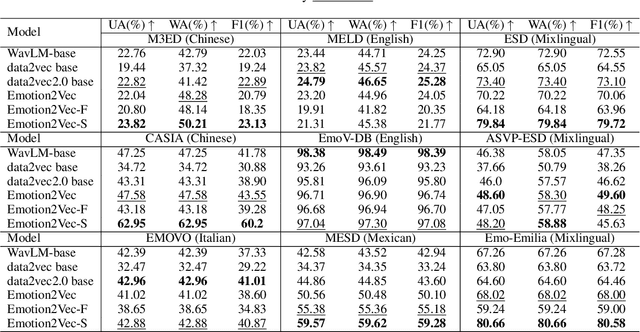
Large-scale audio language models (ALMs), such as Qwen2-Audio, are capable of comprehending diverse audio signal, performing audio analysis and generating textual responses. However, in speech emotion recognition (SER), ALMs often suffer from hallucinations, resulting in misclassifications or irrelevant outputs. To address these challenges, we propose C$^2$SER, a novel ALM designed to enhance the stability and accuracy of SER through Contextual perception and Chain of Thought (CoT). C$^2$SER integrates the Whisper encoder for semantic perception and Emotion2Vec-S for acoustic perception, where Emotion2Vec-S extends Emotion2Vec with semi-supervised learning to enhance emotional discrimination. Additionally, C$^2$SER employs a CoT approach, processing SER in a step-by-step manner while leveraging speech content and speaking styles to improve recognition. To further enhance stability, C$^2$SER introduces self-distillation from explicit CoT to implicit CoT, mitigating error accumulation and boosting recognition accuracy. Extensive experiments show that C$^2$SER outperforms existing popular ALMs, such as Qwen2-Audio and SECap, delivering more stable and precise emotion recognition. We release the training code, checkpoints, and test sets to facilitate further research.
Ideal-LLM: Integrating Dual Encoders and Language-Adapted LLM for Multilingual Speech-to-Text
Sep 17, 2024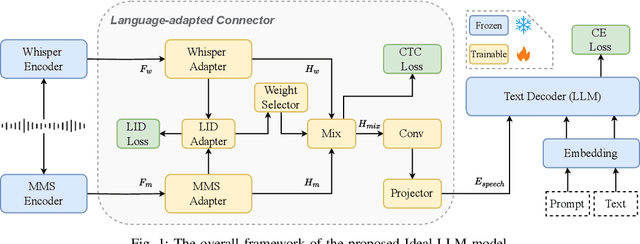
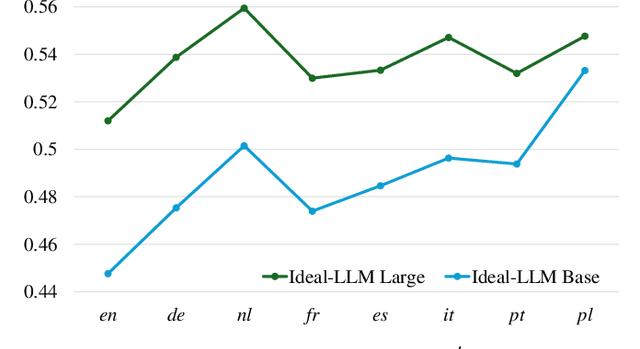
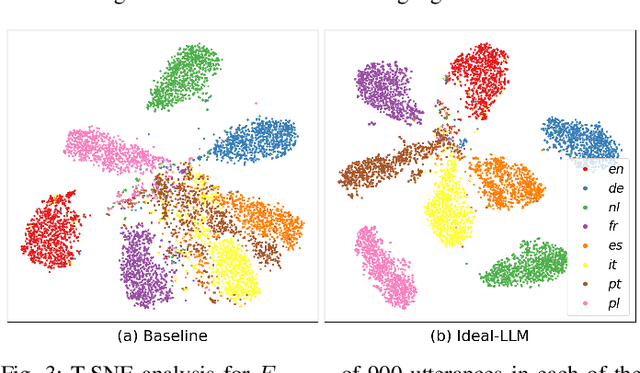

Integrating audio encoders with LLMs through connectors has enabled these models to process and comprehend audio modalities, significantly enhancing speech-to-text tasks, including automatic speech recognition (ASR) and automatic speech translation (AST). However, these methods often overlook the critical aspect of language adaptation in multilingual settings, relying instead on multilingual data without adequately addressing language differences. To address this gap, we propose the Ideal-LLM model, which employs dual multilingual encoders to enrich language feature information and utilizes a language-adapted connector to target the adaptation of each language specifically. By leveraging the complementary strengths of Whisper and MMS encoders, our approach ensures richer multilingual representations. Additionally, the language-adapted connector enhances modal transformation via a language weight selector tailored for each language. Experimental results demonstrate that Ideal-LLM significantly improves ASR performance, achieving a 32.6% relative reduction in average word error rates compared to the standard speech encoder integrated with LLMs and yields an average BLEU score of 36.78 for AST task.
Unveiling the Potential of LLM-Based ASR on Chinese Open-Source Datasets
May 06, 2024



Large Language Models (LLMs) have demonstrated unparalleled effectiveness in various NLP tasks, and integrating LLMs with automatic speech recognition (ASR) is becoming a mainstream paradigm. Building upon this momentum, our research delves into an in-depth examination of this paradigm on a large open-source Chinese dataset. Specifically, our research aims to evaluate the impact of various configurations of speech encoders, LLMs, and projector modules in the context of the speech foundation encoder-LLM ASR paradigm. Furthermore, we introduce a three-stage training approach, expressly developed to enhance the model's ability to align auditory and textual information. The implementation of this approach, alongside the strategic integration of ASR components, enabled us to achieve the SOTA performance on the AISHELL-1, Test_Net, and Test_Meeting test sets. Our analysis presents an empirical foundation for future research in LLM-based ASR systems and offers insights into optimizing performance using Chinese datasets. We will publicly release all scripts used for data preparation, training, inference, and scoring, as well as pre-trained models and training logs to promote reproducible research.