 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAudio-Cogito: Towards Deep Audio Reasoning in Large Audio Language Models
Apr 14, 2026Recent advances in reasoning models have driven significant progress in text and multimodal domains, yet audio reasoning remains relatively limited. Only a few Large Audio Language Models (LALMs) incorporate explicit Chain-of-Thought (CoT) reasoning, and their capabilities are often inconsistent and insufficient for complex tasks. To bridge this gap, we introduce Audio-Cogito, a fully open-source solution for deep audio reasoning. We develop Cogito-pipe for high-quality audio reasoning data curation, producing 545k reasoning samples that will be released after review. Based on this dataset, we adopt a self-distillation strategy for model fine-tuning. Experiments on the MMAR benchmark, the only audio benchmark evaluating the CoT process, show that our model achieves the best performance among open-source models and matches or surpasses certain closed-source models in specific metrics. Our approach also ranks among the top-tier systems in the Interspeech 2026 Audio Reasoning Challenge.
Delayed-KD: Delayed Knowledge Distillation based CTC for Low-Latency Streaming ASR
May 28, 2025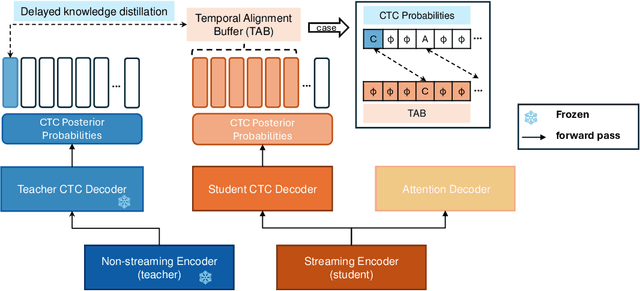

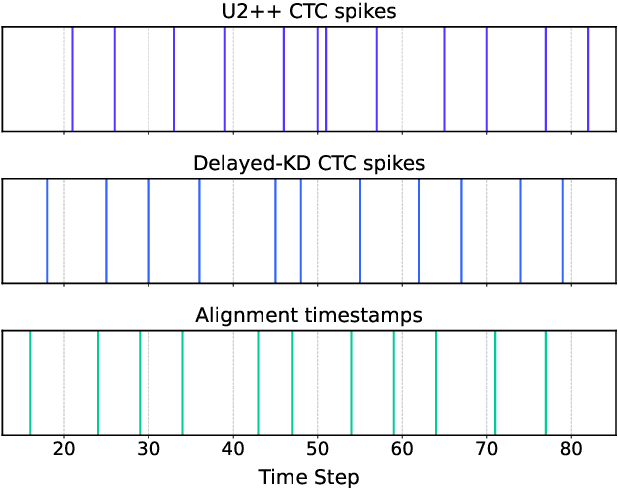
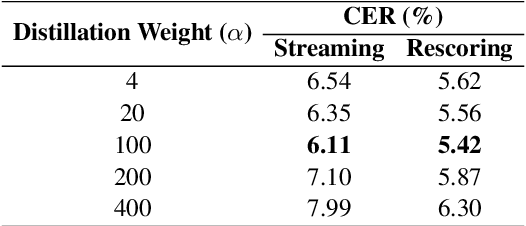
CTC-based streaming ASR has gained significant attention in real-world applications but faces two main challenges: accuracy degradation in small chunks and token emission latency. To mitigate these challenges, we propose Delayed-KD, which applies delayed knowledge distillation on CTC posterior probabilities from a non-streaming to a streaming model. Specifically, with a tiny chunk size, we introduce a Temporal Alignment Buffer (TAB) that defines a relative delay range compared to the non-streaming teacher model to align CTC outputs and mitigate non-blank token mismatches. Additionally, TAB enables fine-grained control over token emission delay. Experiments on 178-hour AISHELL-1 and 10,000-hour WenetSpeech Mandarin datasets show consistent superiority of Delayed-KD. Impressively, Delayed-KD at 40 ms latency achieves a lower character error rate (CER) of 5.42% on AISHELL-1, comparable to the competitive U2++ model running at 320 ms latency.
Ideal-LLM: Integrating Dual Encoders and Language-Adapted LLM for Multilingual Speech-to-Text
Sep 17, 2024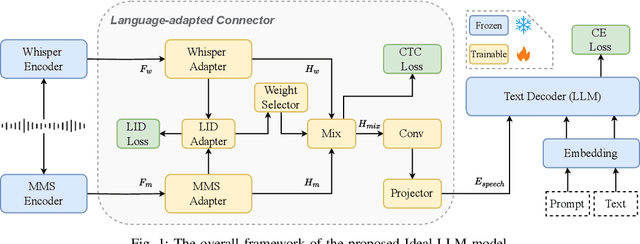
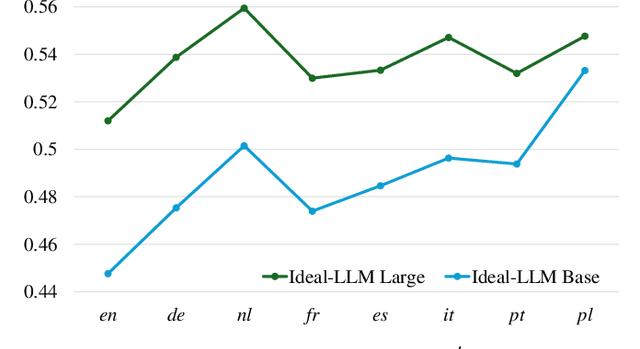
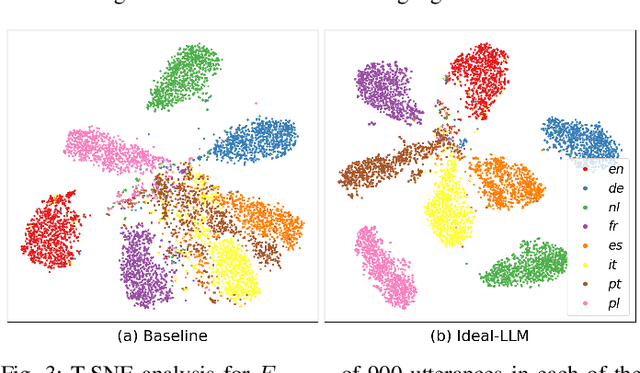

Integrating audio encoders with LLMs through connectors has enabled these models to process and comprehend audio modalities, significantly enhancing speech-to-text tasks, including automatic speech recognition (ASR) and automatic speech translation (AST). However, these methods often overlook the critical aspect of language adaptation in multilingual settings, relying instead on multilingual data without adequately addressing language differences. To address this gap, we propose the Ideal-LLM model, which employs dual multilingual encoders to enrich language feature information and utilizes a language-adapted connector to target the adaptation of each language specifically. By leveraging the complementary strengths of Whisper and MMS encoders, our approach ensures richer multilingual representations. Additionally, the language-adapted connector enhances modal transformation via a language weight selector tailored for each language. Experimental results demonstrate that Ideal-LLM significantly improves ASR performance, achieving a 32.6% relative reduction in average word error rates compared to the standard speech encoder integrated with LLMs and yields an average BLEU score of 36.78 for AST task.
Unveiling the Potential of LLM-Based ASR on Chinese Open-Source Datasets
May 06, 2024



Large Language Models (LLMs) have demonstrated unparalleled effectiveness in various NLP tasks, and integrating LLMs with automatic speech recognition (ASR) is becoming a mainstream paradigm. Building upon this momentum, our research delves into an in-depth examination of this paradigm on a large open-source Chinese dataset. Specifically, our research aims to evaluate the impact of various configurations of speech encoders, LLMs, and projector modules in the context of the speech foundation encoder-LLM ASR paradigm. Furthermore, we introduce a three-stage training approach, expressly developed to enhance the model's ability to align auditory and textual information. The implementation of this approach, alongside the strategic integration of ASR components, enabled us to achieve the SOTA performance on the AISHELL-1, Test_Net, and Test_Meeting test sets. Our analysis presents an empirical foundation for future research in LLM-based ASR systems and offers insights into optimizing performance using Chinese datasets. We will publicly release all scripts used for data preparation, training, inference, and scoring, as well as pre-trained models and training logs to promote reproducible research.