 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReactive Planning based Control for Mobile Robots in Obstacle-Cluttered Environments
May 14, 2026This paper addresses the motion control problem for mobile robots in obstacle-cluttered environments. The mobile robot has partial environment information only, and aims to move from an initial position to a target position without collisions. For this purpose, a reactive planning based control strategy (RPCS) is proposed. First, the initial and target positions are connected as a reference trajectory. Then, a reactive planning strategy (RPS) is developed to ensure the collision avoidance by modifying the reference trajectory locally based on the partial environment information. Next, an adaptive tracking control strategy (ATCS) is proposed to track the reference trajectory with potentially local modifications via the discretization techniques. Finally, the RPS and ATCS are combined to establish the RPCS, whose efficacy and advantages are illustrated by numerical examples.
Seeing No Evil: Blinding Large Vision-Language Models to Safety Instructions via Adversarial Attention Hijacking
Apr 11, 2026Large Vision-Language Models (LVLMs) rely on attention-based retrieval of safety instructions to maintain alignment during generation. Existing attacks typically optimize image perturbations to maximize harmful output likelihood, but suffer from slow convergence due to gradient conflict between adversarial objectives and the model's safety-retrieval mechanism. We propose Attention-Guided Visual Jailbreaking, which circumvents rather than overpowers safety alignment by directly manipulating attention patterns. Our method introduces two simple auxiliary objectives: (1) suppressing attention to alignment-relevant prefix tokens and (2) anchoring generation on adversarial image features. This simple yet effective push-pull formulation reduces gradient conflict by 45% and achieves 94.4% attack success rate on Qwen-VL (vs. 68.8% baseline) with 40% fewer iterations. At tighter perturbation budgets ($ε=8/255$), we maintain 59.0% ASR compared to 45.7% for standard methods. Mechanistic analysis reveals a failure mode we term safety blindness: successful attacks suppress system-prompt attention by 80%, causing models to generate harmful content not by overriding safety rules, but by failing to retrieve them.
VBGS-SLAM: Variational Bayesian Gaussian Splatting Simultaneous Localization and Mapping
Apr 03, 20263D Gaussian Splatting (3DGS) has shown promising results for 3D scene modeling using mixtures of Gaussians, yet its existing simultaneous localization and mapping (SLAM) variants typically rely on direct, deterministic pose optimization against the splat map, making them sensitive to initialization and susceptible to catastrophic forgetting as map evolves. We propose Variational Bayesian Gaussian Splatting SLAM (VBGS-SLAM), a novel framework that couples the splat map refinement and camera pose tracking in a generative probabilistic form. By leveraging conjugate properties of multivariate Gaussians and variational inference, our method admits efficient closed-form updates and explicitly maintains posterior uncertainty over both poses and scene parameters. This uncertainty-aware method mitigates drift and enhances robustness in challenging conditions, while preserving the efficiency and rendering quality of existing 3DGS. Our experiments demonstrate superior tracking performance and robustness in long sequence prediction, alongside efficient, high-quality novel view synthesis across diverse synthetic and real-world scenes.
Graph Unlearning: Efficient Node Removal in Graph Neural Networks
Sep 05, 2025With increasing concerns about privacy attacks and potential sensitive information leakage, researchers have actively explored methods to efficiently remove sensitive training data and reduce privacy risks in graph neural network (GNN) models. Node unlearning has emerged as a promising technique for protecting the privacy of sensitive nodes by efficiently removing specific training node information from GNN models. However, existing node unlearning methods either impose restrictions on the GNN structure or do not effectively utilize the graph topology for node unlearning. Some methods even compromise the graph's topology, making it challenging to achieve a satisfactory performance-complexity trade-off. To address these issues and achieve efficient unlearning for training node removal in GNNs, we propose three novel node unlearning methods: Class-based Label Replacement, Topology-guided Neighbor Mean Posterior Probability, and Class-consistent Neighbor Node Filtering. Among these methods, Topology-guided Neighbor Mean Posterior Probability and Class-consistent Neighbor Node Filtering effectively leverage the topological features of the graph, resulting in more effective node unlearning. To validate the superiority of our proposed methods in node unlearning, we conducted experiments on three benchmark datasets. The evaluation criteria included model utility, unlearning utility, and unlearning efficiency. The experimental results demonstrate the utility and efficiency of the proposed methods and illustrate their superiority compared to state-of-the-art node unlearning methods. Overall, the proposed methods efficiently remove sensitive training nodes and protect the privacy information of sensitive nodes in GNNs. The findings contribute to enhancing the privacy and security of GNN models and provide valuable insights into the field of node unlearning.
PLK-Calib: Single-shot and Target-less LiDAR-Camera Extrinsic Calibration using Plücker Lines
Mar 11, 2025Accurate LiDAR-Camera (LC) calibration is challenging but crucial for autonomous systems and robotics. In this paper, we propose two single-shot and target-less algorithms to estimate the calibration parameters between LiDAR and camera using line features. The first algorithm constructs line-to-line constraints by defining points-to-line projection errors and minimizes the projection error. The second algorithm (PLK-Calib) utilizes the co-perpendicular and co-parallel geometric properties of lines in Pl\"ucker (PLK) coordinate, and decouples the rotation and translation into two constraints, enabling more accurate estimates. Our degenerate analysis and Monte Carlo simulation indicate that three nonparallel line pairs are the minimal requirements to estimate the extrinsic parameters. Furthermore, we collect an LC calibration dataset with varying extrinsic under three different scenarios and use it to evaluate the performance of our proposed algorithms.
NeRF-VIO: Map-Based Visual-Inertial Odometry with Initialization Leveraging Neural Radiance Fields
Mar 11, 2025A prior map serves as a foundational reference for localization in context-aware applications such as augmented reality (AR). Providing valuable contextual information about the environment, the prior map is a vital tool for mitigating drift. In this paper, we propose a map-based visual-inertial localization algorithm (NeRF-VIO) with initialization using neural radiance fields (NeRF). Our algorithm utilizes a multilayer perceptron model and redefines the loss function as the geodesic distance on \(SE(3)\), ensuring the invariance of the initialization model under a frame change within \(\mathfrak{se}(3)\). The evaluation demonstrates that our model outperforms existing NeRF-based initialization solution in both accuracy and efficiency. By integrating a two-stage update mechanism within a multi-state constraint Kalman filter (MSCKF) framework, the state of NeRF-VIO is constrained by both captured images from an onboard camera and rendered images from a pre-trained NeRF model. The proposed algorithm is validated using a real-world AR dataset, the results indicate that our two-stage update pipeline outperforms MSCKF across all data sequences.
Large Language Models Merging for Enhancing the Link Stealing Attack on Graph Neural Networks
Dec 08, 2024



Graph Neural Networks (GNNs), specifically designed to process the graph data, have achieved remarkable success in various applications. Link stealing attacks on graph data pose a significant privacy threat, as attackers aim to extract sensitive relationships between nodes (entities), potentially leading to academic misconduct, fraudulent transactions, or other malicious activities. Previous studies have primarily focused on single datasets and did not explore cross-dataset attacks, let alone attacks that leverage the combined knowledge of multiple attackers. However, we find that an attacker can combine the data knowledge of multiple attackers to create a more effective attack model, which can be referred to cross-dataset attacks. Moreover, if knowledge can be extracted with the help of Large Language Models (LLMs), the attack capability will be more significant. In this paper, we propose a novel link stealing attack method that takes advantage of cross-dataset and Large Language Models (LLMs). The LLM is applied to process datasets with different data structures in cross-dataset attacks. Each attacker fine-tunes the LLM on their specific dataset to generate a tailored attack model. We then introduce a novel model merging method to integrate the parameters of these attacker-specific models effectively. The result is a merged attack model with superior generalization capabilities, enabling effective attacks not only on the attackers' datasets but also on previously unseen (out-of-domain) datasets. We conducted extensive experiments in four datasets to demonstrate the effectiveness of our method. Additional experiments with three different GNN and LLM architectures further illustrate the generality of our approach.
Noncontact Multi-Point Vital Sign Monitoring with mmWave MIMO Radar
Nov 14, 2024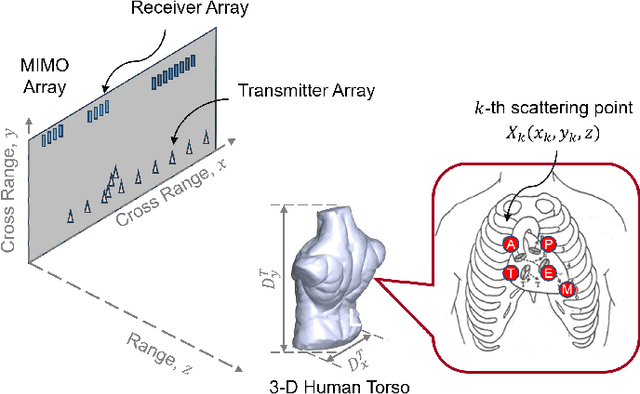
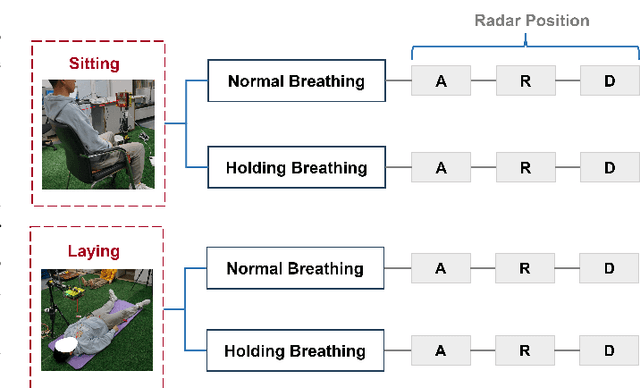
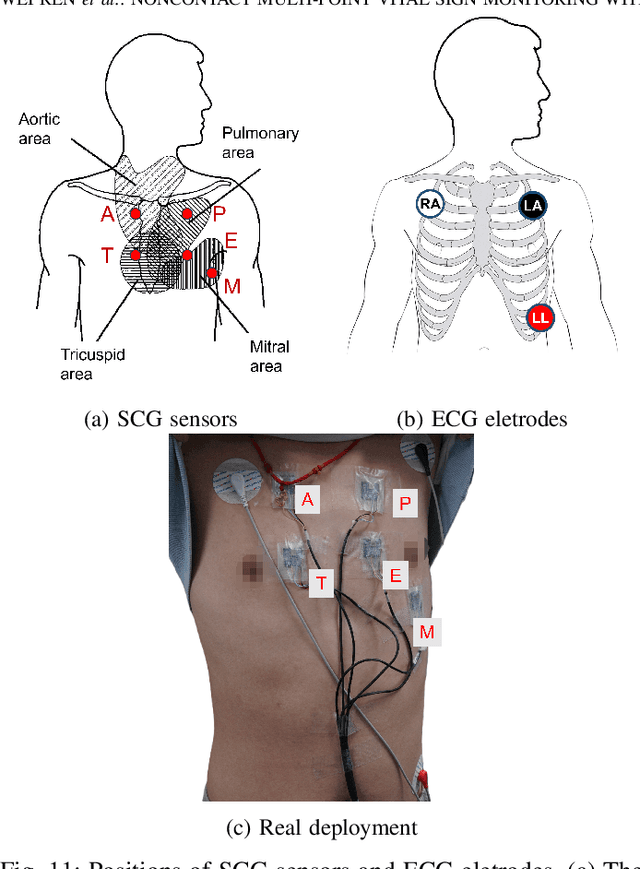
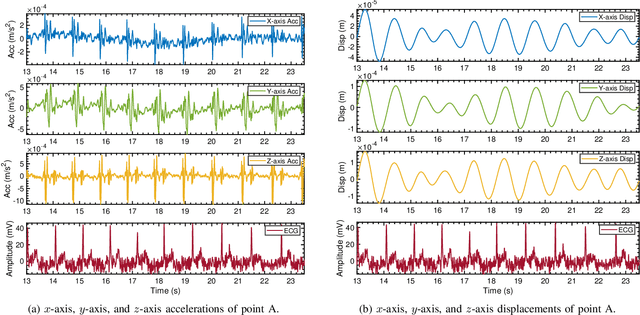
Multi-point vital sign monitoring is essential for providing detailed insights into physiological changes. Traditional single-sensor approaches are inadequate for capturing multi-point vibrations. Existing contact-based solutions, while addressing this need, can cause discomfort and skin allergies, whereas noncontact optical and acoustic methods are highly susceptible to light interference and environmental noise. In this paper, we aim to develop a non-contact, multi-point vital sign monitoring technique using MIMO radar, focused on physically differentiating and precisely measuring chest-wall surface vibrations at multiple points induced by cardiopulmonary mechanical activity. The primary challenges in developing such a technique involve developing algorithms to extract and separate entangled signals, as well as establishing a reliable method for validating detection accuracy. To address these limitations, we introduce MultiVital, a wireless system that leverages mmWave Multiple-input Multiple-output (MIMO) radar for synchronous multi-point vital sign monitoring. It integrates two reference modalities: five-channel seismocardiography (SCG) sensors and a one-channel electrocardiogram (ECG) electrode, enabling comprehensive radar-based research and performance validation across multiple physiological metrics. Additionally, we have developed a multi-modal signal processing framework, consisting of a radar signal processing module, an SCG calibration module, and a spatial alignment scheme. To evaluate the radar signal processing module, we conducted mathematical derivation and simulation. The experimental results indicate that the noncontact MultiVital system achieves multi-point synchronous monitoring with high precision, highly consistent with the results from reference modalities.
Ideal-LLM: Integrating Dual Encoders and Language-Adapted LLM for Multilingual Speech-to-Text
Sep 17, 2024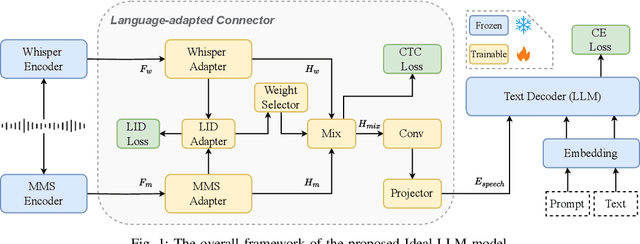
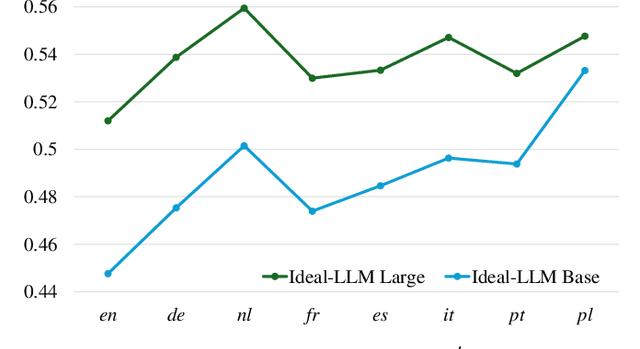
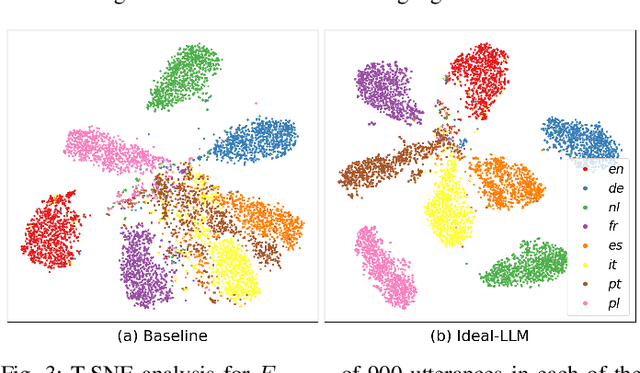

Integrating audio encoders with LLMs through connectors has enabled these models to process and comprehend audio modalities, significantly enhancing speech-to-text tasks, including automatic speech recognition (ASR) and automatic speech translation (AST). However, these methods often overlook the critical aspect of language adaptation in multilingual settings, relying instead on multilingual data without adequately addressing language differences. To address this gap, we propose the Ideal-LLM model, which employs dual multilingual encoders to enrich language feature information and utilizes a language-adapted connector to target the adaptation of each language specifically. By leveraging the complementary strengths of Whisper and MMS encoders, our approach ensures richer multilingual representations. Additionally, the language-adapted connector enhances modal transformation via a language weight selector tailored for each language. Experimental results demonstrate that Ideal-LLM significantly improves ASR performance, achieving a 32.6% relative reduction in average word error rates compared to the standard speech encoder integrated with LLMs and yields an average BLEU score of 36.78 for AST task.
Zonotope-based Symbolic Controller Synthesis for Linear Temporal Logic Specifications
May 02, 2024



This paper studies the controller synthesis problem for nonlinear control systems under linear temporal logic (LTL) specifications using zonotope techniques. A local-to-global control strategy is proposed for the desired specification expressed as an LTL formula. First, a novel approach is developed to divide the state space into finite zonotopes and constrained zonotopes, which are called cells and allowed to intersect with the neighbor cells. Second, from the intersection relation, a graph among all cells is generated to verify the realization of the accepting path for the LTL formula. The realization verification determines if there is a need for the control design, and also results in finite local LTL formulas. Third, once the accepting path is realized, a novel abstraction-based method is derived for the controller design. In particular, we only focus on the cells from the realization verification and approximate each cell thanks to properties of zonotopes. Based on local symbolic models and local LTL formulas, an iterative synthesis algorithm is proposed to design all local abstract controllers, whose existence and combination establish the global controller for the LTL formula. Finally, the proposed framework is illustrated via a path planning problem of mobile robots.