 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePKU-AIGIQA-4K: A Perceptual Quality Assessment Database for Both Text-to-Image and Image-to-Image AI-Generated Images
Apr 29, 2024


In recent years, image generation technology has rapidly advanced, resulting in the creation of a vast array of AI-generated images (AIGIs). However, the quality of these AIGIs is highly inconsistent, with low-quality AIGIs severely impairing the visual experience of users. Due to the widespread application of AIGIs, the AI-generated image quality assessment (AIGIQA), aimed at evaluating the quality of AIGIs from the perspective of human perception, has garnered increasing interest among scholars. Nonetheless, current research has not yet fully explored this field. We have observed that existing databases are limited to images generated from single scenario settings. Databases such as AGIQA-1K, AGIQA-3K, and AIGCIQA2023, for example, only include images generated by text-to-image generative models. This oversight highlights a critical gap in the current research landscape, underscoring the need for dedicated databases catering to image-to-image scenarios, as well as more comprehensive databases that encompass a broader range of AI-generated image scenarios. Addressing these issues, we have established a large scale perceptual quality assessment database for both text-to-image and image-to-image AIGIs, named PKU-AIGIQA-4K. We then conduct a well-organized subjective experiment to collect quality labels for AIGIs and perform a comprehensive analysis of the PKU-AIGIQA-4K database. Regarding the use of image prompts during the training process, we propose three image quality assessment (IQA) methods based on pre-trained models that include a no-reference method NR-AIGCIQA, a full-reference method FR-AIGCIQA, and a partial-reference method PR-AIGCIQA. Finally, leveraging the PKU-AIGIQA-4K database, we conduct extensive benchmark experiments and compare the performance of the proposed methods and the current IQA methods.
TIER: Text-Image Encoder-based Regression for AIGC Image Quality Assessment
Jan 11, 2024Recently, AIGC image quality assessment (AIGCIQA), which aims to assess the quality of AI-generated images (AIGIs) from a human perception perspective, has emerged as a new topic in computer vision. Unlike common image quality assessment tasks where images are derived from original ones distorted by noise, blur, and compression, \textit{etc.}, in AIGCIQA tasks, images are typically generated by generative models using text prompts. Considerable efforts have been made in the past years to advance AIGCIQA. However, most existing AIGCIQA methods regress predicted scores directly from individual generated images, overlooking the information contained in the text prompts of these images. This oversight partially limits the performance of these AIGCIQA methods. To address this issue, we propose a text-image encoder-based regression (TIER) framework. Specifically, we process the generated images and their corresponding text prompts as inputs, utilizing a text encoder and an image encoder to extract features from these text prompts and generated images, respectively. To demonstrate the effectiveness of our proposed TIER method, we conduct extensive experiments on several mainstream AIGCIQA databases, including AGIQA-1K, AGIQA-3K, and AIGCIQA2023. The experimental results indicate that our proposed TIER method generally demonstrates superior performance compared to baseline in most cases.
PSCR: Patches Sampling-based Contrastive Regression for AIGC Image Quality Assessment
Dec 10, 2023



In recent years, Artificial Intelligence Generated Content (AIGC) has gained widespread attention beyond the computer science community. Due to various issues arising from continuous creation of AI-generated images (AIGI), AIGC image quality assessment (AIGCIQA), which aims to evaluate the quality of AIGIs from human perception perspectives, has emerged as a novel topic in the field of computer vision. However, most existing AIGCIQA methods directly regress predicted scores from a single generated image, overlooking the inherent differences among AIGIs and scores. Additionally, operations like resizing and cropping may cause global geometric distortions and information loss, thus limiting the performance of models. To address these issues, we propose a patches sampling-based contrastive regression (PSCR) framework. We suggest introducing a contrastive regression framework to leverage differences among various generated images for learning a better representation space. In this space, differences and score rankings among images can be measured by their relative scores. By selecting exemplar AIGIs as references, we also overcome the limitations of previous models that could not utilize reference images on the no-reference image databases. To avoid geometric distortions and information loss in image inputs, we further propose a patches sampling strategy. To demonstrate the effectiveness of our proposed PSCR framework, we conduct extensive experiments on three mainstream AIGCIQA databases including AGIQA-1K, AGIQA-3K and AIGCIQA2023. The results show significant improvements in model performance with the introduction of our proposed PSCR framework. Code will be available at \url{https://github.com/jiquan123/PSCR}.
PKU-I2IQA: An Image-to-Image Quality Assessment Database for AI Generated Images
Nov 29, 2023


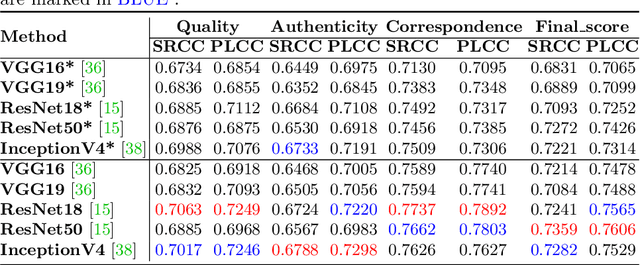
As image generation technology advances, AI-based image generation has been applied in various fields and Artificial Intelligence Generated Content (AIGC) has garnered widespread attention. However, the development of AI-based image generative models also brings new problems and challenges. A significant challenge is that AI-generated images (AIGI) may exhibit unique distortions compared to natural images, and not all generated images meet the requirements of the real world. Therefore, it is of great significance to evaluate AIGIs more comprehensively. Although previous work has established several human perception-based AIGC image quality assessment (AIGCIQA) databases for text-generated images, the AI image generation technology includes scenarios like text-to-image and image-to-image, and assessing only the images generated by text-to-image models is insufficient. To address this issue, we establish a human perception-based image-to-image AIGCIQA database, named PKU-I2IQA. We conduct a well-organized subjective experiment to collect quality labels for AIGIs and then conduct a comprehensive analysis of the PKU-I2IQA database. Furthermore, we have proposed two benchmark models: NR-AIGCIQA based on the no-reference image quality assessment method and FR-AIGCIQA based on the full-reference image quality assessment method. Finally, leveraging this database, we conduct benchmark experiments and compare the performance of the proposed benchmark models. The PKU-I2IQA database and benchmarks will be released to facilitate future research on \url{https://github.com/jiquan123/I2IQA}.
Co-Planar Parametrization for Stereo-SLAM and Visual-Inertial Odometry
Sep 26, 2020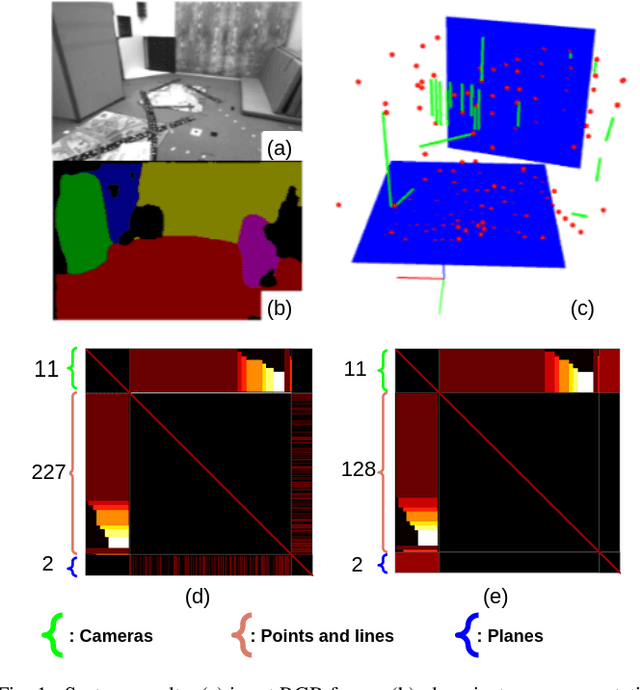
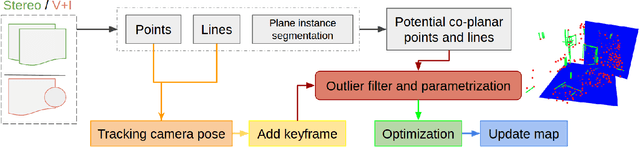
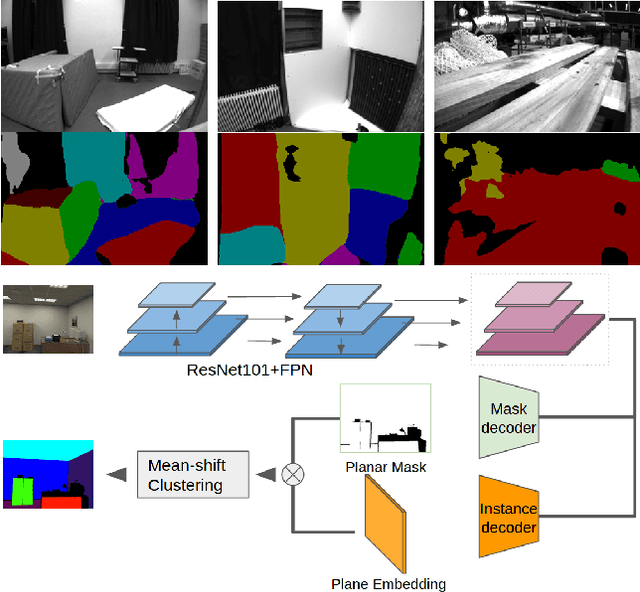
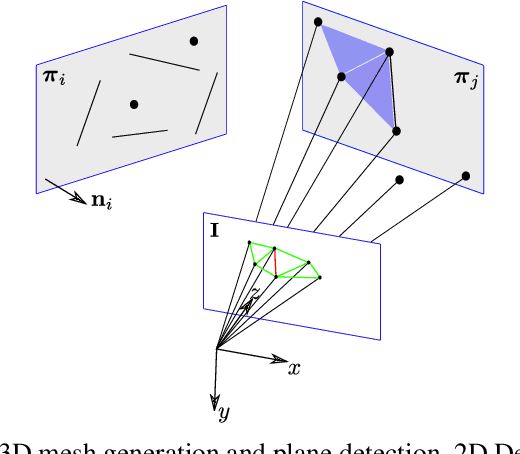
This work proposes a novel SLAM framework for stereo and visual inertial odometry estimation. It builds an efficient and robust parametrization of co-planar points and lines which leverages specific geometric constraints to improve camera pose optimization in terms of both efficiency and accuracy. %reduce the size of the Hessian matrix in the optimization. The pipeline consists of extracting 2D points and lines, predicting planar regions and filtering the outliers via RANSAC. Our parametrization scheme then represents co-planar points and lines as their 2D image coordinates and parameters of planes. We demonstrate the effectiveness of the proposed method by comparing it to traditional parametrizations in a novel Monte-Carlo simulation set. Further, the whole stereo SLAM and VIO system is compared with state-of-the-art methods on the public real-world dataset EuRoC. Our method shows better results in terms of accuracy and efficiency than the state-of-the-art. The code is released at https://github.com/LiXin97/Co-Planar-Parametrization.
Leveraging Planar Regularities for Point Line Visual-Inertial Odometry
Apr 16, 2020


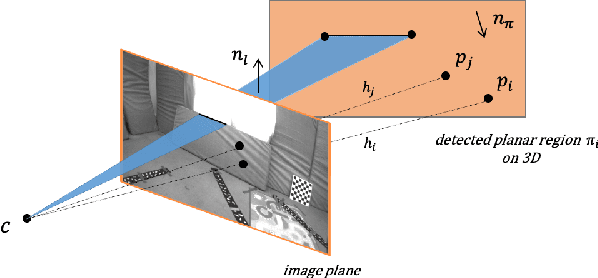
With monocular Visual-Inertial Odometry (VIO) system, 3D point cloud and camera motion can be estimated simultaneously. Because pure sparse 3D points provide a structureless representation of the environment, generating 3D mesh from sparse points can further model the environment topology and produce dense mapping. To improve the accuracy of 3D mesh generation and localization, we propose a tightly-coupled monocular VIO system, PLP-VIO, which exploits point features and line features as well as plane regularities. The co-planarity constraints are used to leverage additional structure information for the more accurate estimation of 3D points and spatial lines in state estimator. To detect plane and 3D mesh robustly, we combine both the line features with point features in the detection method. The effectiveness of the proposed method is verified on both synthetic data and public datasets and is compared with other state-of-the-art algorithms.
Multimodal Emotion Recognition Model using Physiological Signals
Nov 29, 2019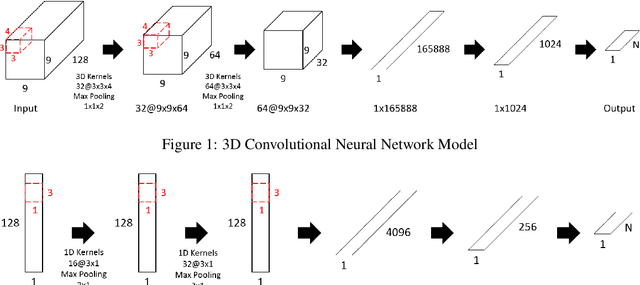
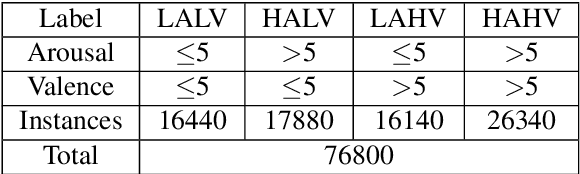
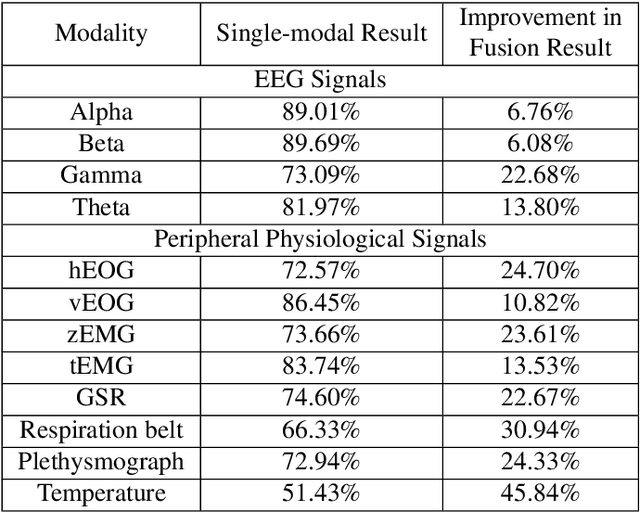

As an important field of research in Human-Machine Interactions, emotion recognition based on physiological signals has become research hotspots. Motivated by the outstanding performance of deep learning approaches in recognition tasks, we proposed a Multimodal Emotion Recognition Model that consists of a 3D convolutional neural network model, a 1D convolutional neural network model and a biologically inspired multimodal fusion model which integrates multimodal information on the decision level for emotion recognition. We use this model to classify four emotional regions from the arousal valence plane, i.e., low arousal and low valence (LALV), high arousal and low valence (HALV), low arousal and high valence (LAHV) and high arousal and high valence (HAHV) in the DEAP and AMIGOS dataset. The 3D CNN model and 1D CNN model are used for emotion recognition based on electroencephalogram (EEG) signals and peripheral physiological signals respectively, and get the accuracy of 93.53% and 95.86% with the original EEG signals in these two datasets. Compared with the single-modal recognition, the multimodal fusion model improves the accuracy of emotion recognition by 5% ~ 25%, and the fusion result of EEG signals (decomposed into four frequency bands) and peripheral physiological signals get the accuracy of 95.77%, 97.27% and 91.07%, 99.74% in these two datasets respectively. Integrated EEG signals and peripheral physiological signals, this model could reach the highest accuracy about 99% in both datasets which shows that our proposed method demonstrates certain advantages in solving the emotion recognition tasks.