 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeREAL-Prover: Retrieval Augmented Lean Prover for Mathematical Reasoning
May 27, 2025Nowadays, formal theorem provers have made monumental progress on high-school and competition-level mathematics, but few of them generalize to more advanced mathematics. In this paper, we present REAL-Prover, a new open-source stepwise theorem prover for Lean 4 to push this boundary. This prover, based on our fine-tuned large language model (REAL-Prover-v1) and integrated with a retrieval system (Leansearch-PS), notably boosts performance on solving college-level mathematics problems. To train REAL-Prover-v1, we developed HERALD-AF, a data extraction pipeline that converts natural language math problems into formal statements, and a new open-source Lean 4 interactive environment (Jixia-interactive) to facilitate synthesis data collection. In our experiments, our prover using only supervised fine-tune achieves competitive results with a 23.7% success rate (Pass@64) on the ProofNet dataset-comparable to state-of-the-art (SOTA) models. To further evaluate our approach, we introduce FATE-M, a new benchmark focused on algebraic problems, where our prover achieves a SOTA success rate of 56.7% (Pass@64).
MAIN: Mutual Alignment Is Necessary for instruction tuning
Apr 17, 2025Instruction tuning has enabled large language models (LLMs) to achieve remarkable performance, but its success heavily depends on the availability of large-scale, high-quality instruction-response pairs. However, current methods for scaling up data generation often overlook a crucial aspect: the alignment between instructions and responses. We hypothesize that high-quality instruction-response pairs are not defined by the individual quality of each component, but by the extent of their alignment with each other. To address this, we propose a Mutual Alignment Framework (MAIN) that ensures coherence between the instruction and response through mutual constraints. Experiments demonstrate that models such as LLaMA and Mistral, fine-tuned within this framework, outperform traditional methods across multiple benchmarks. This approach underscores the critical role of instruction-response alignment in enabling scalable and high-quality instruction tuning for LLMs.
PKU-AIGIQA-4K: A Perceptual Quality Assessment Database for Both Text-to-Image and Image-to-Image AI-Generated Images
Apr 29, 2024

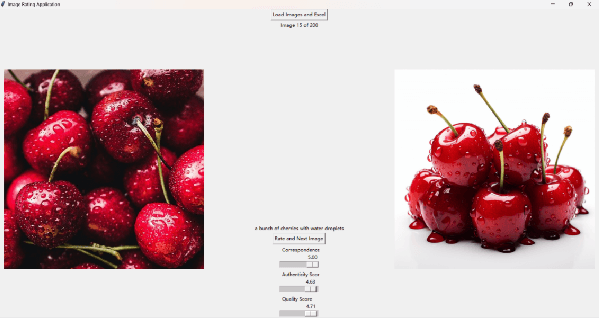

In recent years, image generation technology has rapidly advanced, resulting in the creation of a vast array of AI-generated images (AIGIs). However, the quality of these AIGIs is highly inconsistent, with low-quality AIGIs severely impairing the visual experience of users. Due to the widespread application of AIGIs, the AI-generated image quality assessment (AIGIQA), aimed at evaluating the quality of AIGIs from the perspective of human perception, has garnered increasing interest among scholars. Nonetheless, current research has not yet fully explored this field. We have observed that existing databases are limited to images generated from single scenario settings. Databases such as AGIQA-1K, AGIQA-3K, and AIGCIQA2023, for example, only include images generated by text-to-image generative models. This oversight highlights a critical gap in the current research landscape, underscoring the need for dedicated databases catering to image-to-image scenarios, as well as more comprehensive databases that encompass a broader range of AI-generated image scenarios. Addressing these issues, we have established a large scale perceptual quality assessment database for both text-to-image and image-to-image AIGIs, named PKU-AIGIQA-4K. We then conduct a well-organized subjective experiment to collect quality labels for AIGIs and perform a comprehensive analysis of the PKU-AIGIQA-4K database. Regarding the use of image prompts during the training process, we propose three image quality assessment (IQA) methods based on pre-trained models that include a no-reference method NR-AIGCIQA, a full-reference method FR-AIGCIQA, and a partial-reference method PR-AIGCIQA. Finally, leveraging the PKU-AIGIQA-4K database, we conduct extensive benchmark experiments and compare the performance of the proposed methods and the current IQA methods.
PKU-I2IQA: An Image-to-Image Quality Assessment Database for AI Generated Images
Nov 29, 2023


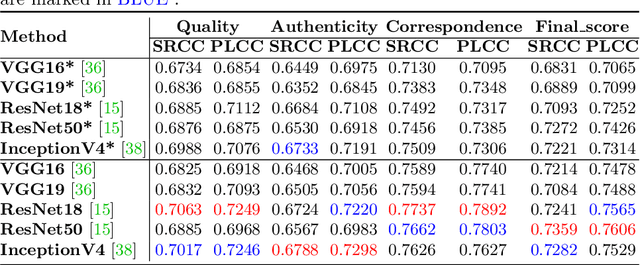
As image generation technology advances, AI-based image generation has been applied in various fields and Artificial Intelligence Generated Content (AIGC) has garnered widespread attention. However, the development of AI-based image generative models also brings new problems and challenges. A significant challenge is that AI-generated images (AIGI) may exhibit unique distortions compared to natural images, and not all generated images meet the requirements of the real world. Therefore, it is of great significance to evaluate AIGIs more comprehensively. Although previous work has established several human perception-based AIGC image quality assessment (AIGCIQA) databases for text-generated images, the AI image generation technology includes scenarios like text-to-image and image-to-image, and assessing only the images generated by text-to-image models is insufficient. To address this issue, we establish a human perception-based image-to-image AIGCIQA database, named PKU-I2IQA. We conduct a well-organized subjective experiment to collect quality labels for AIGIs and then conduct a comprehensive analysis of the PKU-I2IQA database. Furthermore, we have proposed two benchmark models: NR-AIGCIQA based on the no-reference image quality assessment method and FR-AIGCIQA based on the full-reference image quality assessment method. Finally, leveraging this database, we conduct benchmark experiments and compare the performance of the proposed benchmark models. The PKU-I2IQA database and benchmarks will be released to facilitate future research on \url{https://github.com/jiquan123/I2IQA}.