 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSci-VLA: Agentic VLA Inference Plugin for Long-Horizon Tasks in Scientific Experiments
Feb 10, 2026Robotic laboratories play a critical role in autonomous scientific discovery by enabling scalable, continuous experimental execution. Recent vision-language-action (VLA) models offer a promising foundation for robotic laboratories. However, scientific experiments typically involve long-horizon tasks composed of multiple atomic tasks, posing a fundamental challenge to existing VLA models. While VLA models fine-tuned for scientific tasks can reliably execute atomic experimental actions seen during training, they often fail to perform composite tasks formed by reordering and composing these known atomic actions. This limitation arises from a distributional mismatch between training-time atomic tasks and inference-time composite tasks, which prevents VLA models from executing necessary transitional operations between atomic tasks. To address this challenge, we propose an Agentic VLA Inference Plugin for Long-Horizon Tasks in Scientific Experiments. It introduces an LLM-based agentic inference mechanism that intervenes when executing sequential manipulation tasks. By performing explicit transition inference and generating transitional robotic action code, the proposed plugin guides VLA models through missing transitional steps, enabling reliable execution of composite scientific workflows without any additional training. This inference-only intervention makes our method computationally efficient, data-efficient, and well-suited for open-ended and long-horizon robotic laboratory tasks. We build 3D assets of scientific instruments and common scientific operating scenes within an existing simulation environment. In these scenes, we have verified that our method increases the average success rate per atomic task by 42\% during inference. Furthermore, we show that our method can be easily transferred from the simulation to real scientific laboratories.
LaoBench: A Large-Scale Multidimensional Lao Benchmark for Large Language Models
Nov 14, 2025The rapid advancement of large language models (LLMs) has not been matched by their evaluation in low-resource languages, especially Southeast Asian languages like Lao. To fill this gap, we introduce LaoBench, the first large-scale, high-quality, and multidimensional benchmark dataset dedicated to assessing LLMs' comprehensive language understanding and reasoning abilities in Lao. LaoBench comprises over 17,000 carefully curated samples spanning three core dimensions: knowledge application, K12 foundational education, and bilingual translation among Lao, Chinese, and English. The dataset is divided into open-source and closed-source subsets, with the closed-source portion enabling black-box evaluation on an official platform to ensure fairness and data security. Our data construction pipeline integrates expert human curation with automated agent-assisted verification, ensuring linguistic accuracy, cultural relevance, and educational value. Benchmarking multiple state-of-the-art LLMs on LaoBench reveals that current models still face significant challenges in mastering Lao across diverse tasks. We hope LaoBench will catalyze further research and development of AI technologies for underrepresented Southeast Asian languages.
PKU-I2IQA: An Image-to-Image Quality Assessment Database for AI Generated Images
Nov 29, 2023


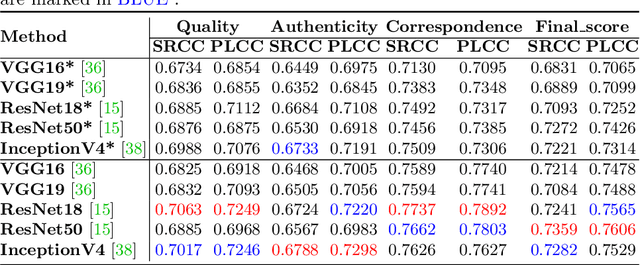
As image generation technology advances, AI-based image generation has been applied in various fields and Artificial Intelligence Generated Content (AIGC) has garnered widespread attention. However, the development of AI-based image generative models also brings new problems and challenges. A significant challenge is that AI-generated images (AIGI) may exhibit unique distortions compared to natural images, and not all generated images meet the requirements of the real world. Therefore, it is of great significance to evaluate AIGIs more comprehensively. Although previous work has established several human perception-based AIGC image quality assessment (AIGCIQA) databases for text-generated images, the AI image generation technology includes scenarios like text-to-image and image-to-image, and assessing only the images generated by text-to-image models is insufficient. To address this issue, we establish a human perception-based image-to-image AIGCIQA database, named PKU-I2IQA. We conduct a well-organized subjective experiment to collect quality labels for AIGIs and then conduct a comprehensive analysis of the PKU-I2IQA database. Furthermore, we have proposed two benchmark models: NR-AIGCIQA based on the no-reference image quality assessment method and FR-AIGCIQA based on the full-reference image quality assessment method. Finally, leveraging this database, we conduct benchmark experiments and compare the performance of the proposed benchmark models. The PKU-I2IQA database and benchmarks will be released to facilitate future research on \url{https://github.com/jiquan123/I2IQA}.
Efficient refinements on YOLOv3 for real-time detection and assessment of diabetic foot Wagner grades
Jun 04, 2020



Currently, the screening of Wagner grades of diabetic feet (DF) still relies on professional podiatrists. However, in less-developed countries, podiatrists are scarce, which led to the majority of undiagnosed patients. In this study, we proposed the real-time detection and location method for Wagner grades of DF based on refinements on YOLOv3. We collected 2,688 data samples and implemented several methods, such as a visual coherent image mixup, label smoothing, and training scheduler revamping, based on the ablation study. The experimental results suggested that the refinements on YOLOv3 achieved an accuracy of 91.95% and the inference speed of a single picture reaches 31ms with the NVIDIA Tesla V100. To test the performance of the model on a smartphone, we deployed the refinements on YOLOv3 models on an Android 9 system smartphone. This work has the potential to lead to a paradigm shift for clinical treatment of the DF in the future, to provide an effective healthcare solution for DF tissue analysis and healing status.