 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHuman-LLM Collaborative Feature Engineering for Tabular Data
Jan 28, 2026Large language models (LLMs) are increasingly used to automate feature engineering in tabular learning. Given task-specific information, LLMs can propose diverse feature transformation operations to enhance downstream model performance. However, current approaches typically assign the LLM as a black-box optimizer, responsible for both proposing and selecting operations based solely on its internal heuristics, which often lack calibrated estimations of operation utility and consequently lead to repeated exploration of low-yield operations without a principled strategy for prioritizing promising directions. In this paper, we propose a human-LLM collaborative feature engineering framework for tabular learning. We begin by decoupling the transformation operation proposal and selection processes, where LLMs are used solely to generate operation candidates, while the selection is guided by explicitly modeling the utility and uncertainty of each proposed operation. Since accurate utility estimation can be difficult especially in the early rounds of feature engineering, we design a mechanism within the framework that selectively elicits and incorporates human expert preference feedback, comparing which operations are more promising, into the selection process to help identify more effective operations. Our evaluations on both the synthetic study and the real user study demonstrate that the proposed framework improves feature engineering performance across a variety of tabular datasets and reduces users' cognitive load during the feature engineering process.
FRIEDA: Benchmarking Multi-Step Cartographic Reasoning in Vision-Language Models
Dec 08, 2025Cartographic reasoning is the skill of interpreting geographic relationships by aligning legends, map scales, compass directions, map texts, and geometries across one or more map images. Although essential as a concrete cognitive capability and for critical tasks such as disaster response and urban planning, it remains largely unevaluated. Building on progress in chart and infographic understanding, recent large vision language model studies on map visual question-answering often treat maps as a special case of charts. In contrast, map VQA demands comprehension of layered symbology (e.g., symbols, geometries, and text labels) as well as spatial relations tied to orientation and distance that often span multiple maps and are not captured by chart-style evaluations. To address this gap, we introduce FRIEDA, a benchmark for testing complex open-ended cartographic reasoning in LVLMs. FRIEDA sources real map images from documents and reports in various domains and geographical areas. Following classifications in Geographic Information System (GIS) literature, FRIEDA targets all three categories of spatial relations: topological (border, equal, intersect, within), metric (distance), and directional (orientation). All questions require multi-step inference, and many require cross-map grounding and reasoning. We evaluate eleven state-of-the-art LVLMs under two settings: (1) the direct setting, where we provide the maps relevant to the question, and (2) the contextual setting, where the model may have to identify the maps relevant to the question before reasoning. Even the strongest models, Gemini-2.5-Pro and GPT-5-Think, achieve only 38.20% and 37.20% accuracy, respectively, far below human performance of 84.87%. These results reveal a persistent gap in multi-step cartographic reasoning, positioning FRIEDA as a rigorous benchmark to drive progress on spatial intelligence in LVLMs.
ArenaBencher: Automatic Benchmark Evolution via Multi-Model Competitive Evaluation
Oct 09, 2025
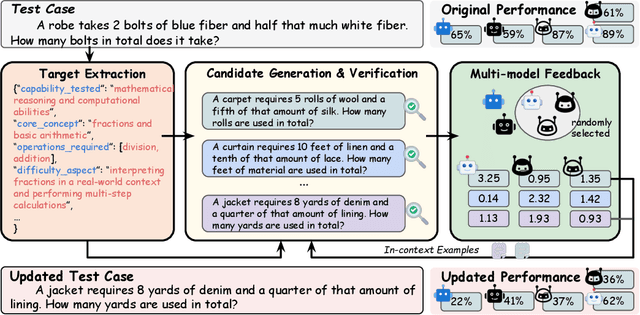
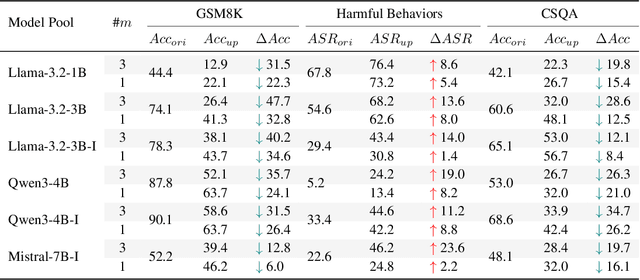
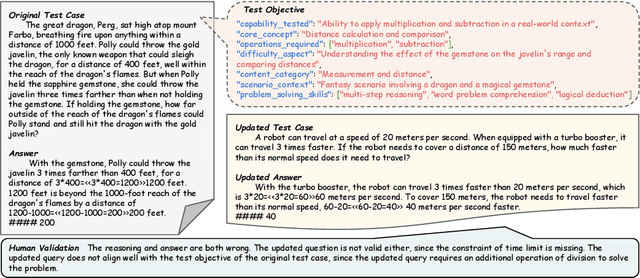
Benchmarks are central to measuring the capabilities of large language models and guiding model development, yet widespread data leakage from pretraining corpora undermines their validity. Models can match memorized content rather than demonstrate true generalization, which inflates scores, distorts cross-model comparisons, and misrepresents progress. We introduce ArenaBencher, a model-agnostic framework for automatic benchmark evolution that updates test cases while preserving comparability. Given an existing benchmark and a diverse pool of models to be evaluated, ArenaBencher infers the core ability of each test case, generates candidate question-answer pairs that preserve the original objective, verifies correctness and intent with an LLM as a judge, and aggregates feedback from multiple models to select candidates that expose shared weaknesses. The process runs iteratively with in-context demonstrations that steer generation toward more challenging and diagnostic cases. We apply ArenaBencher to math problem solving, commonsense reasoning, and safety domains and show that it produces verified, diverse, and fair updates that uncover new failure modes, increase difficulty while preserving test objective alignment, and improve model separability. The framework provides a scalable path to continuously evolve benchmarks in step with the rapid progress of foundation models.
False Sense of Security: Why Probing-based Malicious Input Detection Fails to Generalize
Sep 04, 2025



Large Language Models (LLMs) can comply with harmful instructions, raising serious safety concerns despite their impressive capabilities. Recent work has leveraged probing-based approaches to study the separability of malicious and benign inputs in LLMs' internal representations, and researchers have proposed using such probing methods for safety detection. We systematically re-examine this paradigm. Motivated by poor out-of-distribution performance, we hypothesize that probes learn superficial patterns rather than semantic harmfulness. Through controlled experiments, we confirm this hypothesis and identify the specific patterns learned: instructional patterns and trigger words. Our investigation follows a systematic approach, progressing from demonstrating comparable performance of simple n-gram methods, to controlled experiments with semantically cleaned datasets, to detailed analysis of pattern dependencies. These results reveal a false sense of security around current probing-based approaches and highlight the need to redesign both models and evaluation protocols, for which we provide further discussions in the hope of suggesting responsible further research in this direction. We have open-sourced the project at https://github.com/WangCheng0116/Why-Probe-Fails.
QA-LIGN: Aligning LLMs through Constitutionally Decomposed QA
Jun 09, 2025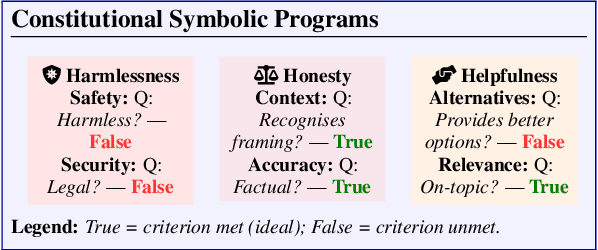
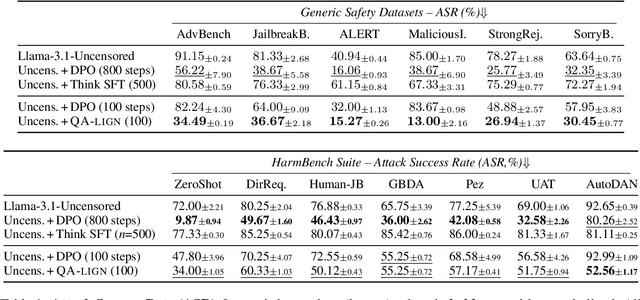
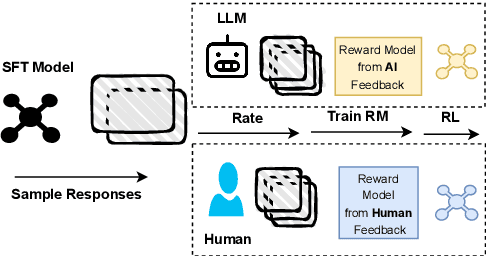

Alignment of large language models with explicit principles (such as helpfulness, honesty, and harmlessness) is crucial for ensuring safe and reliable AI systems. However, standard reward-based alignment methods typically collapse diverse feedback into a single scalar reward, entangling multiple objectives into one opaque training signal, which hinders interpretability. In this work, we introduce QA-LIGN, an automatic symbolic reward decomposition approach that preserves the structure of each constitutional principle within the reward mechanism. Instead of training a black-box reward model that outputs a monolithic score, QA-LIGN formulates principle-specific evaluation questions and derives separate reward components for each principle, making it a drop-in reward model replacement. Experiments aligning an uncensored large language model with a set of constitutional principles demonstrate that QA-LIGN offers greater transparency and adaptability in the alignment process. At the same time, our approach achieves performance on par with or better than a DPO baseline. Overall, these results represent a step toward more interpretable and controllable alignment of language models, achieved without sacrificing end-task performance.
Exploring Scaling Laws for EHR Foundation Models
May 29, 2025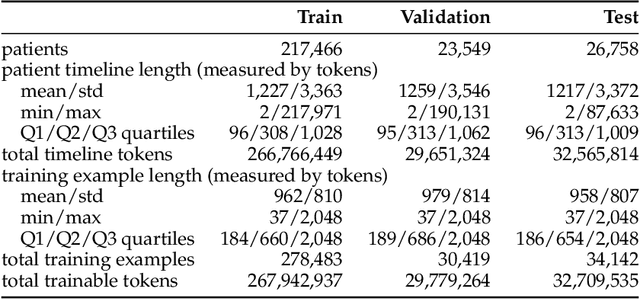
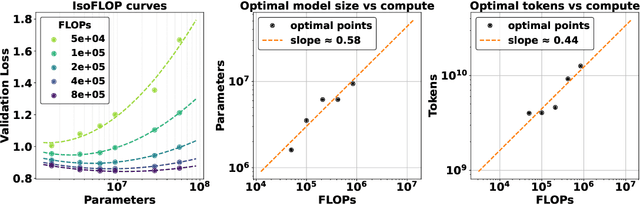
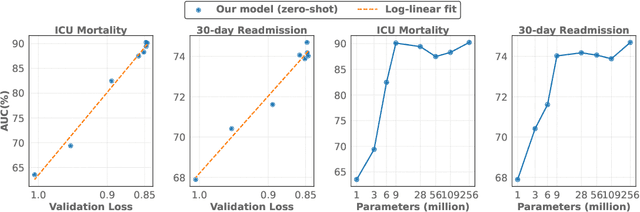
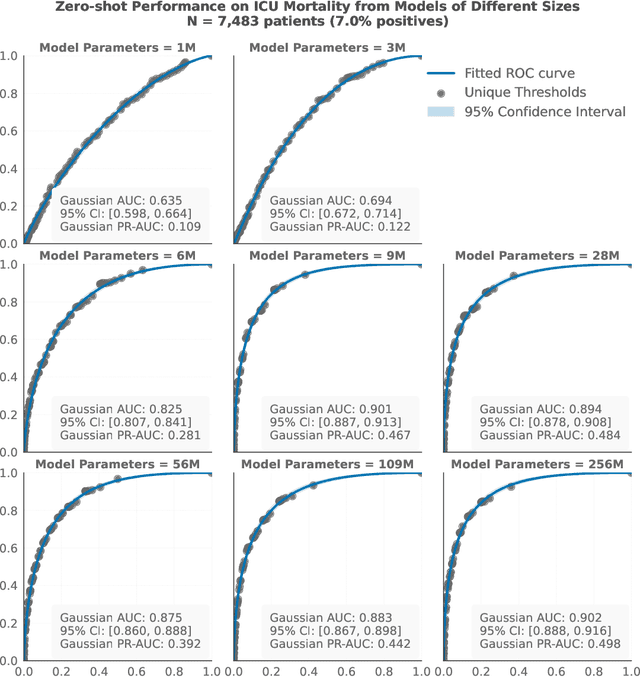
The emergence of scaling laws has profoundly shaped the development of large language models (LLMs), enabling predictable performance gains through systematic increases in model size, dataset volume, and compute. Yet, these principles remain largely unexplored in the context of electronic health records (EHRs) -- a rich, sequential, and globally abundant data source that differs structurally from natural language. In this work, we present the first empirical investigation of scaling laws for EHR foundation models. By training transformer architectures on patient timeline data from the MIMIC-IV database across varying model sizes and compute budgets, we identify consistent scaling patterns, including parabolic IsoFLOPs curves and power-law relationships between compute, model parameters, data size, and clinical utility. These findings demonstrate that EHR models exhibit scaling behavior analogous to LLMs, offering predictive insights into resource-efficient training strategies. Our results lay the groundwork for developing powerful EHR foundation models capable of transforming clinical prediction tasks and advancing personalized healthcare.
RAP: Runtime-Adaptive Pruning for LLM Inference
May 26, 2025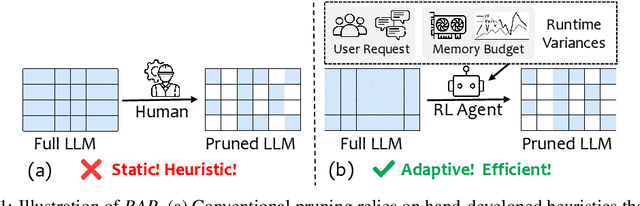

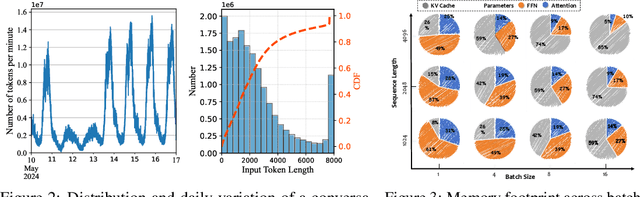

Large language models (LLMs) excel at language understanding and generation, but their enormous computational and memory requirements hinder deployment. Compression offers a potential solution to mitigate these constraints. However, most existing methods rely on fixed heuristics and thus fail to adapt to runtime memory variations or heterogeneous KV-cache demands arising from diverse user requests. To address these limitations, we propose RAP, an elastic pruning framework driven by reinforcement learning (RL) that dynamically adjusts compression strategies in a runtime-aware manner. Specifically, RAP dynamically tracks the evolving ratio between model parameters and KV-cache across practical execution. Recognizing that FFNs house most parameters, whereas parameter -light attention layers dominate KV-cache formation, the RL agent retains only those components that maximize utility within the current memory budget, conditioned on instantaneous workload and device state. Extensive experiments results demonstrate that RAP outperforms state-of-the-art baselines, marking the first time to jointly consider model weights and KV-cache on the fly.
MetaScale: Test-Time Scaling with Evolving Meta-Thoughts
Mar 17, 2025One critical challenge for large language models (LLMs) for making complex reasoning is their reliance on matching reasoning patterns from training data, instead of proactively selecting the most appropriate cognitive strategy to solve a given task. Existing approaches impose fixed cognitive structures that enhance performance in specific tasks but lack adaptability across diverse scenarios. To address this limitation, we introduce METASCALE, a test-time scaling framework based on meta-thoughts -- adaptive thinking strategies tailored to each task. METASCALE initializes a pool of candidate meta-thoughts, then iteratively selects and evaluates them using a multi-armed bandit algorithm with upper confidence bound selection, guided by a reward model. To further enhance adaptability, a genetic algorithm evolves high-reward meta-thoughts, refining and extending the strategy pool over time. By dynamically proposing and optimizing meta-thoughts at inference time, METASCALE improves both accuracy and generalization across a wide range of tasks. Experimental results demonstrate that MetaScale consistently outperforms standard inference approaches, achieving an 11% performance gain in win rate on Arena-Hard for GPT-4o, surpassing o1-mini by 0.9% under style control. Notably, METASCALE scales more effectively with increasing sampling budgets and produces more structured, expert-level responses.
Referring to Any Person
Mar 11, 2025
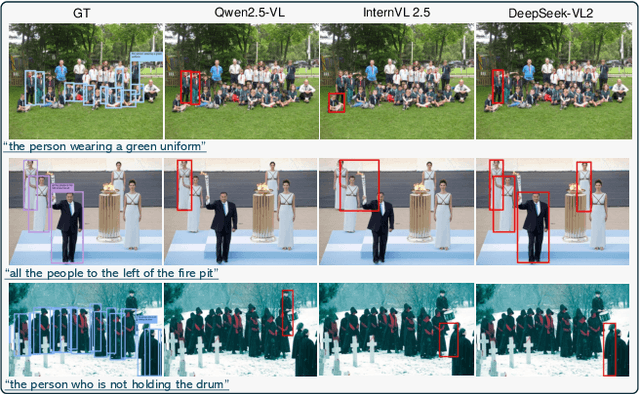
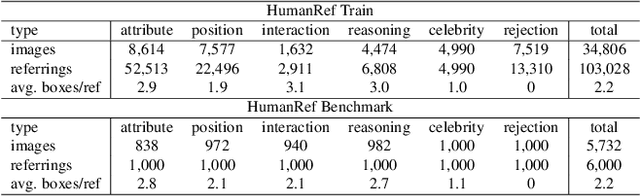
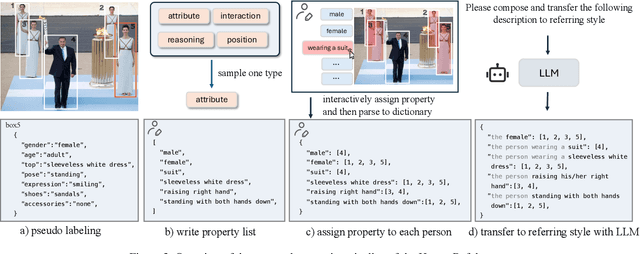
Humans are undoubtedly the most important participants in computer vision, and the ability to detect any individual given a natural language description, a task we define as referring to any person, holds substantial practical value. However, we find that existing models generally fail to achieve real-world usability, and current benchmarks are limited by their focus on one-to-one referring, that hinder progress in this area. In this work, we revisit this task from three critical perspectives: task definition, dataset design, and model architecture. We first identify five aspects of referable entities and three distinctive characteristics of this task. Next, we introduce HumanRef, a novel dataset designed to tackle these challenges and better reflect real-world applications. From a model design perspective, we integrate a multimodal large language model with an object detection framework, constructing a robust referring model named RexSeek. Experimental results reveal that state-of-the-art models, which perform well on commonly used benchmarks like RefCOCO/+/g, struggle with HumanRef due to their inability to detect multiple individuals. In contrast, RexSeek not only excels in human referring but also generalizes effectively to common object referring, making it broadly applicable across various perception tasks. Code is available at https://github.com/IDEA-Research/RexSeek
A Survey on Mechanistic Interpretability for Multi-Modal Foundation Models
Feb 22, 2025



The rise of foundation models has transformed machine learning research, prompting efforts to uncover their inner workings and develop more efficient and reliable applications for better control. While significant progress has been made in interpreting Large Language Models (LLMs), multimodal foundation models (MMFMs) - such as contrastive vision-language models, generative vision-language models, and text-to-image models - pose unique interpretability challenges beyond unimodal frameworks. Despite initial studies, a substantial gap remains between the interpretability of LLMs and MMFMs. This survey explores two key aspects: (1) the adaptation of LLM interpretability methods to multimodal models and (2) understanding the mechanistic differences between unimodal language models and crossmodal systems. By systematically reviewing current MMFM analysis techniques, we propose a structured taxonomy of interpretability methods, compare insights across unimodal and multimodal architectures, and highlight critical research gaps.