 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLiVOS: Light Video Object Segmentation with Gated Linear Matching
Paper and Code
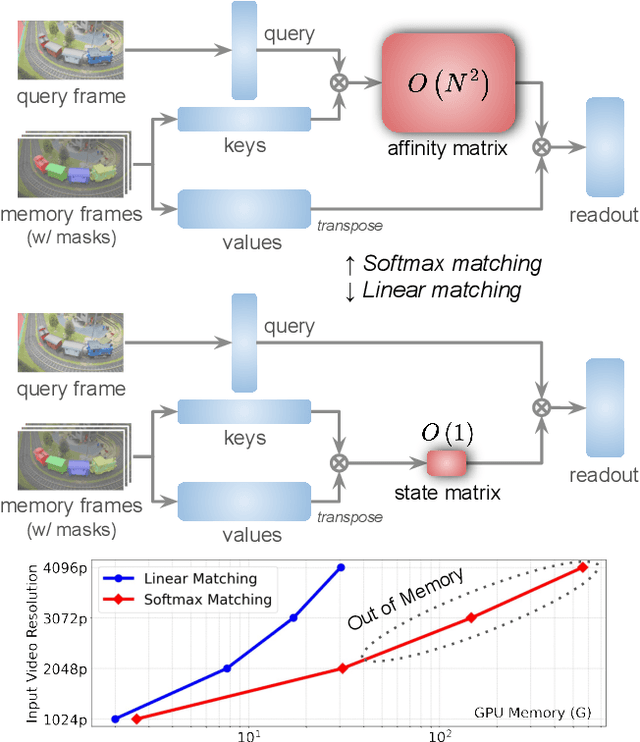
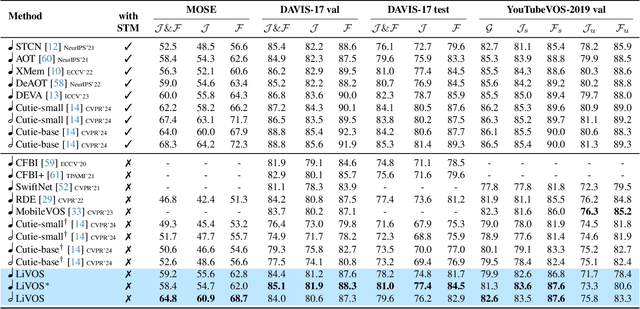
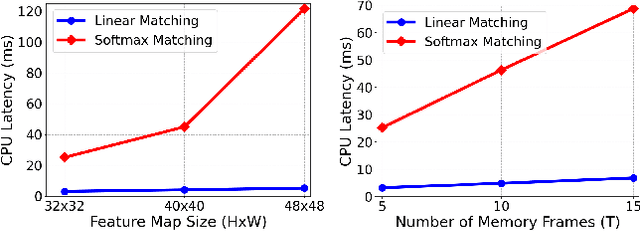
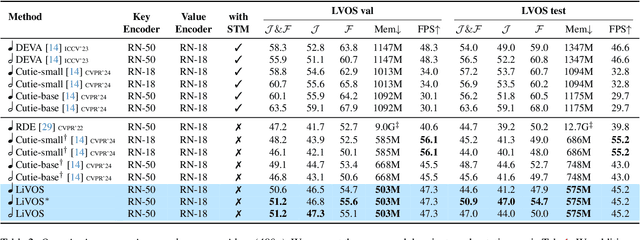
Semi-supervised video object segmentation (VOS) has been largely driven by space-time memory (STM) networks, which store past frame features in a spatiotemporal memory to segment the current frame via softmax attention. However, STM networks face memory limitations due to the quadratic complexity of softmax matching, restricting their applicability as video length and resolution increase. To address this, we propose LiVOS, a lightweight memory network that employs linear matching via linear attention, reformulating memory matching into a recurrent process that reduces the quadratic attention matrix to a constant-size, spatiotemporal-agnostic 2D state. To enhance selectivity, we introduce gated linear matching, where a data-dependent gate matrix is multiplied with the state matrix to control what information to retain or discard. Experiments on diverse benchmarks demonstrated the effectiveness of our method. It achieved 64.8 J&F on MOSE and 85.1 J&F on DAVIS, surpassing all non-STM methods and narrowing the gap with STM-based approaches. For longer and higher-resolution videos, it matched STM-based methods with 53% less GPU memory and supports 4096p inference on a 32G consumer-grade GPU--a previously cost-prohibitive capability--opening the door for long and high-resolution video foundation models.