 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeESAM++: Efficient Online 3D Perception on the Edge
May 28, 2026Online 3D scene perception in real time is essential for robotics, AR/VR, and autonomous systems, particularly in edge computing scenarios where computational resources are limited and privacy is crucial. Recent state-of-the-art methods like EmbodiedSAM (ESAM) demonstrate the promise of online 3D perception by leveraging the Segment Anything Model (SAM) for real-time, fine-grained, and generalized 3D instance segmentation. However, ESAM still relies on a computationally expensive 3D sparse UNet for point cloud feature extraction, which accounts for the majority of the 3D inference time, hindering its practicality on resource-constrained devices. In this paper, we propose ESAM++, a lightweight and scalable alternative for online 3D scene perception tailored to edge devices without GPU acceleration. Our method introduces a 3D Sparse Feature Pyramid Network (SFPN) that efficiently captures multi-scale geometric features from streaming 3D point clouds while significantly reducing computational overhead and model size. We evaluate our approach on four challenging segmentation benchmarks, namely ScanNet, ScanNet200, SceneNN, and 3RScan, demonstrating that our model achieves competitive accuracy with up to 3 times faster inference with a 2 times smaller model size compared to ESAM, enabling practical deployment on edge devices.
Understanding Model Behavior in Monocular Polyp Sizing
May 19, 2026Accurate polyp size stratification guides surveillance decisions, with lesions larger than 5 mm typically requiring closer follow-up. However, monocular colonoscopy lacks a reliable metric reference. We present a diagnostic audit of binary polyp size classification (<=5 mm vs. >5 mm) across multiple public multi-center datasets, model families, and patient-stratified cross-validation. Across architectures and input modalities, including RGB appearance, relative depth, and photometry, model performance is moderately consistent, suggesting reliance on cues correlated with examination behavior rather than true metric scales. By providing ground-truth scale at varying granularities, we quantify the potential improvement from perfect scale information and show that current depth estimation and global calibration offer limited gains. We further demonstrate that segmentation errors under distribution shift eliminate most of this potential, with oracle scale under predicted masks recovering only baseline performance. These results highlight metric scale and mask robustness as two independent bottlenecks and provide reusable evaluation tools such as oracle scale ladders, shortcut partitions, and mask substitution for auditing future polyp sizing pipelines. Our code is publicly accessible at https://github.com/anaxqx/polyp-sizing-audit.
TeDiO: Temporal Diagonal Optimization for Training-Free Coherent Video Diffusion
May 13, 2026Recent text-to-video diffusion transformers generate visually compelling frames, yet still struggle with temporal coherence, often producing flickering, drifting, or unstable motion. We show that these failures leave a clear imprint inside the model: incoherent videos consistently exhibit irregular, fragmented temporal diagonals in their intermediate self-attention maps, whereas stable motion corresponds to smooth, band-diagonal patterns. Building on this observation, we introduce TeDiO, a training-free, inference-time method that reinforces temporal consistency by regularizing these internal attention patterns. TeDiO estimates diagonal smoothness, identifies unstable regions, and performs lightweight latent updates that promote coherent frame-to-frame dynamics, without modifying model weights or using external motion supervision. Across multiple video diffusion models (e.g., Wan2.1, CogVideoX), TeDiO delivers markedly smoother motion while preserving per-frame visual quality, offering an efficient plug-and-play approach to improving dynamic realism in modern video generation systems.
PRISM: A 3D Probabilistic Neural Representation for Interpretable Shape Modeling
Feb 12, 2026Understanding how anatomical shapes evolve in response to developmental covariates and quantifying their spatially varying uncertainties is critical in healthcare research. Existing approaches typically rely on global time-warping formulations that ignore spatially heterogeneous dynamics. We introduce PRISM, a novel framework that bridges implicit neural representations with uncertainty-aware statistical shape analysis. PRISM models the conditional distribution of shapes given covariates, providing spatially continuous estimates of both the population mean and covariate-dependent uncertainty at arbitrary locations. A key theoretical contribution is a closed-form Fisher Information metric that enables efficient, analytically tractable local temporal uncertainty quantification via automatic differentiation. Experiments on three synthetic datasets and one clinical dataset demonstrate PRISM's strong performance across diverse tasks within a unified framework, while providing interpretable and clinically meaningful uncertainty estimates.
On The Robustness of Foundational 3D Medical Image Segmentation Models Against Imprecise Visual Prompts
Jan 23, 2026While 3D foundational models have shown promise for promptable segmentation of medical volumes, their robustness to imprecise prompts remains under-explored. In this work, we aim to address this gap by systematically studying the effect of various controlled perturbations of dense visual prompts, that closely mimic real-world imprecision. By conducting experiments with two recent foundational models on a multi-organ abdominal segmentation task, we reveal several facets of promptable medical segmentation, especially pertaining to reliance on visual shape and spatial cues, and the extent of resilience of models towards certain perturbations. Codes are available at: https://github.com/ucsdbiag/Prompt-Robustness-MedSegFMs
NOCTA: Non-Greedy Objective Cost-Tradeoff Acquisition for Longitudinal Data
Jul 16, 2025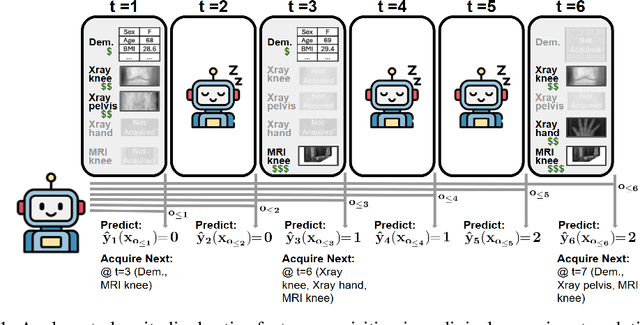

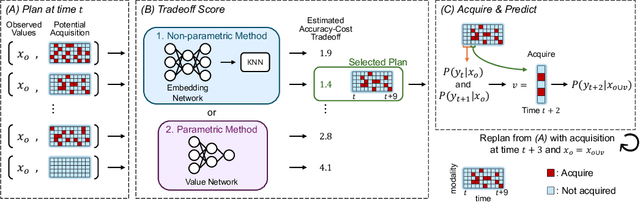
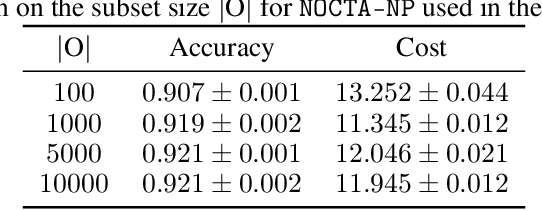
In many critical applications, resource constraints limit the amount of information that can be gathered to make predictions. For example, in healthcare, patient data often spans diverse features ranging from lab tests to imaging studies. Each feature may carry different information and must be acquired at a respective cost of time, money, or risk to the patient. Moreover, temporal prediction tasks, where both instance features and labels evolve over time, introduce additional complexity in deciding when or what information is important. In this work, we propose NOCTA, a Non-Greedy Objective Cost-Tradeoff Acquisition method that sequentially acquires the most informative features at inference time while accounting for both temporal dynamics and acquisition cost. We first introduce a cohesive estimation target for our NOCTA setting, and then develop two complementary estimators: 1) a non-parametric method based on nearest neighbors to guide the acquisition (NOCTA-NP), and 2) a parametric method that directly predicts the utility of potential acquisitions (NOCTA-P). Experiments on synthetic and real-world medical datasets demonstrate that both NOCTA variants outperform existing baselines.
PPS-Ctrl: Controllable Sim-to-Real Translation for Colonoscopy Depth Estimation
Apr 23, 2025Accurate depth estimation enhances endoscopy navigation and diagnostics, but obtaining ground-truth depth in clinical settings is challenging. Synthetic datasets are often used for training, yet the domain gap limits generalization to real data. We propose a novel image-to-image translation framework that preserves structure while generating realistic textures from clinical data. Our key innovation integrates Stable Diffusion with ControlNet, conditioned on a latent representation extracted from a Per-Pixel Shading (PPS) map. PPS captures surface lighting effects, providing a stronger structural constraint than depth maps. Experiments show our approach produces more realistic translations and improves depth estimation over GAN-based MI-CycleGAN. Our code is publicly accessible at https://github.com/anaxqx/PPS-Ctrl.
Zero-shot Domain Generalization of Foundational Models for 3D Medical Image Segmentation: An Experimental Study
Mar 28, 2025Domain shift, caused by variations in imaging modalities and acquisition protocols, limits model generalization in medical image segmentation. While foundation models (FMs) trained on diverse large-scale data hold promise for zero-shot generalization, their application to volumetric medical data remains underexplored. In this study, we examine their ability towards domain generalization (DG), by conducting a comprehensive experimental study encompassing 6 medical segmentation FMs and 12 public datasets spanning multiple modalities and anatomies. Our findings reveal the potential of promptable FMs in bridging the domain gap via smart prompting techniques. Additionally, by probing into multiple facets of zero-shot DG, we offer valuable insights into the viability of FMs for DG and identify promising avenues for future research.
Downstream Analysis of Foundational Medical Vision Models for Disease Progression
Mar 21, 2025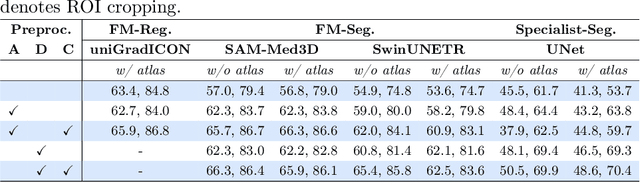

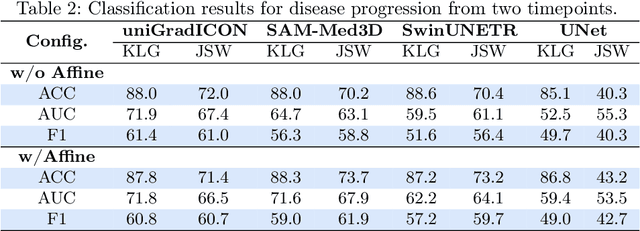
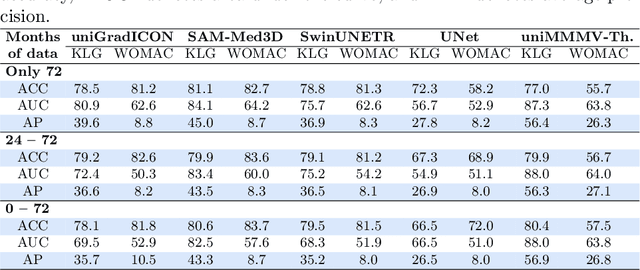
Medical vision foundational models are used for a wide variety of tasks, including medical image segmentation and registration. This work evaluates the ability of these models to predict disease progression using a simple linear probe. We hypothesize that intermediate layer features of segmentation models capture structural information, while those of registration models encode knowledge of change over time. Beyond demonstrating that these features are useful for disease progression prediction, we also show that registration model features do not require spatially aligned input images. However, for segmentation models, spatial alignment is essential for optimal performance. Our findings highlight the importance of spatial alignment and the utility of foundation model features for image registration.
$\texttt{LucidAtlas}$: Learning Uncertainty-Aware, Covariate-Disentangled, Individualized Atlas Representations
Feb 12, 2025The goal of this work is to develop principled techniques to extract information from high dimensional data sets with complex dependencies in areas such as medicine that can provide insight into individual as well as population level variation. We develop $\texttt{LucidAtlas}$, an approach that can represent spatially varying information, and can capture the influence of covariates as well as population uncertainty. As a versatile atlas representation, $\texttt{LucidAtlas}$ offers robust capabilities for covariate interpretation, individualized prediction, population trend analysis, and uncertainty estimation, with the flexibility to incorporate prior knowledge. Additionally, we discuss the trustworthiness and potential risks of neural additive models for analyzing dependent covariates and then introduce a marginalization approach to explain the dependence of an individual predictor on the models' response (the atlas). To validate our method, we demonstrate its generalizability on two medical datasets. Our findings underscore the critical role of by-construction interpretable models in advancing scientific discovery. Our code will be publicly available upon acceptance.