 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProJo4D: Progressive Joint Optimization for Sparse-View Inverse Physics Estimation
Jun 05, 2025Neural rendering has made significant strides in 3D reconstruction and novel view synthesis. With the integration with physics, it opens up new applications. The inverse problem of estimating physics from visual data, however, still remains challenging, limiting its effectiveness for applications like physically accurate digital twin creation in robotics and XR. Existing methods that incorporate physics into neural rendering frameworks typically require dense multi-view videos as input, making them impractical for scalable, real-world use. When presented with sparse multi-view videos, the sequential optimization strategy used by existing approaches introduces significant error accumulation, e.g., poor initial 3D reconstruction leads to bad material parameter estimation in subsequent stages. Instead of sequential optimization, directly optimizing all parameters at the same time also fails due to the highly non-convex and often non-differentiable nature of the problem. We propose ProJo4D, a progressive joint optimization framework that gradually increases the set of jointly optimized parameters guided by their sensitivity, leading to fully joint optimization over geometry, appearance, physical state, and material property. Evaluations on PAC-NeRF and Spring-Gaus datasets show that ProJo4D outperforms prior work in 4D future state prediction, novel view rendering of future state, and material parameter estimation, demonstrating its effectiveness in physically grounded 4D scene understanding. For demos, please visit the project webpage: https://daniel03c1.github.io/ProJo4D/
NFL-BA: Improving Endoscopic SLAM with Near-Field Light Bundle Adjustment
Dec 17, 2024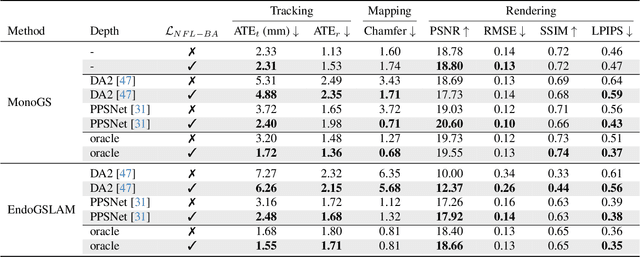
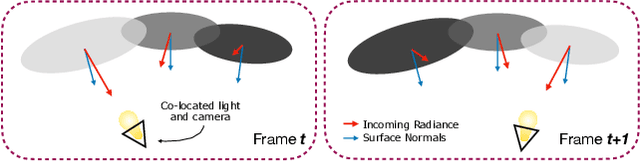
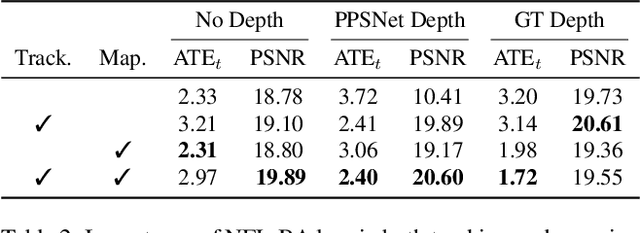
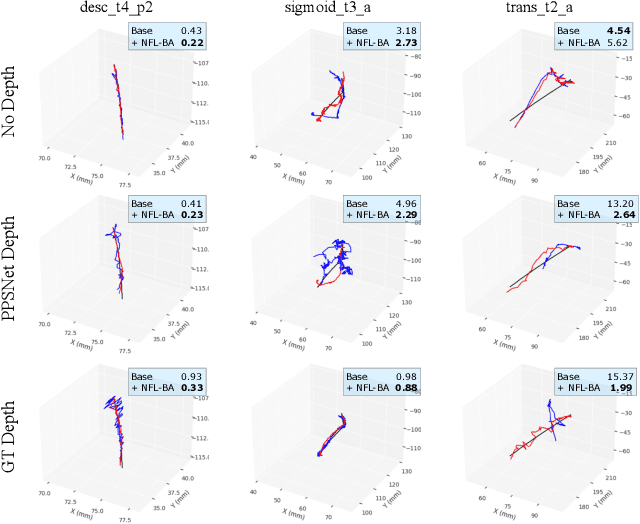
Simultaneous Localization And Mapping (SLAM) from a monocular endoscopy video can enable autonomous navigation, guidance to unsurveyed regions, and 3D visualizations, which can significantly improve endoscopy experience for surgeons and patient outcomes. Existing dense SLAM algorithms often assume distant and static lighting and textured surfaces, and alternate between optimizing scene geometry and camera parameters by minimizing a photometric rendering loss, often called Photometric Bundle Adjustment. However, endoscopic environments exhibit dynamic near-field lighting due to the co-located light and camera moving extremely close to the surface, textureless surfaces, and strong specular reflections due to mucus layers. When not considered, these near-field lighting effects can cause significant performance reductions for existing SLAM algorithms from indoor/outdoor scenes when applied to endoscopy videos. To mitigate this problem, we introduce a new Near-Field Lighting Bundle Adjustment Loss $(L_{NFL-BA})$ that can also be alternatingly optimized, along with the Photometric Bundle Adjustment loss, such that the captured images' intensity variations match the relative distance and orientation between the surface and the co-located light and camera. We derive a general NFL-BA loss function for 3D Gaussian surface representations and demonstrate that adding $L_{NFL-BA}$ can significantly improve the tracking and mapping performance of two state-of-the-art 3DGS-SLAM systems, MonoGS (35% improvement in tracking, 48% improvement in mapping with predicted depth maps) and EndoGSLAM (22% improvement in tracking, marginal improvement in mapping with predicted depths), on the C3VD endoscopy dataset for colons. The project page is available at https://asdunnbe.github.io/NFL-BA/
Compact 3D Gaussian Splatting for Static and Dynamic Radiance Fields
Aug 07, 2024



3D Gaussian splatting (3DGS) has recently emerged as an alternative representation that leverages a 3D Gaussian-based representation and introduces an approximated volumetric rendering, achieving very fast rendering speed and promising image quality. Furthermore, subsequent studies have successfully extended 3DGS to dynamic 3D scenes, demonstrating its wide range of applications. However, a significant drawback arises as 3DGS and its following methods entail a substantial number of Gaussians to maintain the high fidelity of the rendered images, which requires a large amount of memory and storage. To address this critical issue, we place a specific emphasis on two key objectives: reducing the number of Gaussian points without sacrificing performance and compressing the Gaussian attributes, such as view-dependent color and covariance. To this end, we propose a learnable mask strategy that significantly reduces the number of Gaussians while preserving high performance. In addition, we propose a compact but effective representation of view-dependent color by employing a grid-based neural field rather than relying on spherical harmonics. Finally, we learn codebooks to compactly represent the geometric and temporal attributes by residual vector quantization. With model compression techniques such as quantization and entropy coding, we consistently show over 25x reduced storage and enhanced rendering speed compared to 3DGS for static scenes, while maintaining the quality of the scene representation. For dynamic scenes, our approach achieves more than 12x storage efficiency and retains a high-quality reconstruction compared to the existing state-of-the-art methods. Our work provides a comprehensive framework for 3D scene representation, achieving high performance, fast training, compactness, and real-time rendering. Our project page is available at https://maincold2.github.io/c3dgs/.
F-3DGS: Factorized Coordinates and Representations for 3D Gaussian Splatting
May 28, 2024



The neural radiance field (NeRF) has made significant strides in representing 3D scenes and synthesizing novel views. Despite its advancements, the high computational costs of NeRF have posed challenges for its deployment in resource-constrained environments and real-time applications. As an alternative to NeRF-like neural rendering methods, 3D Gaussian Splatting (3DGS) offers rapid rendering speeds while maintaining excellent image quality. However, as it represents objects and scenes using a myriad of Gaussians, it requires substantial storage to achieve high-quality representation. To mitigate the storage overhead, we propose Factorized 3D Gaussian Splatting (F-3DGS), a novel approach that drastically reduces storage requirements while preserving image quality. Inspired by classical matrix and tensor factorization techniques, our method represents and approximates dense clusters of Gaussians with significantly fewer Gaussians through efficient factorization. We aim to efficiently represent dense 3D Gaussians by approximating them with a limited amount of information for each axis and their combinations. This method allows us to encode a substantially large number of Gaussians along with their essential attributes -- such as color, scale, and rotation -- necessary for rendering using a relatively small number of elements. Extensive experimental results demonstrate that F-3DGS achieves a significant reduction in storage costs while maintaining comparable quality in rendered images.
Mip-Grid: Anti-aliased Grid Representations for Neural Radiance Fields
Feb 22, 2024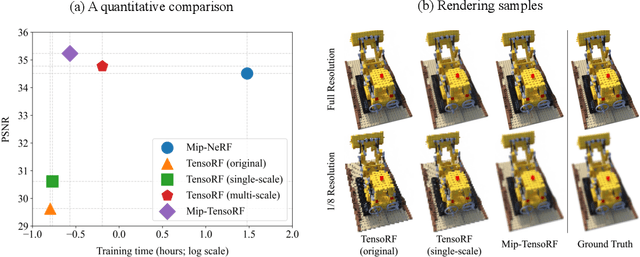
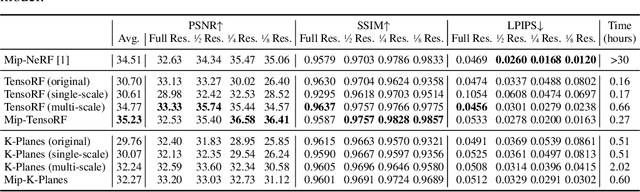

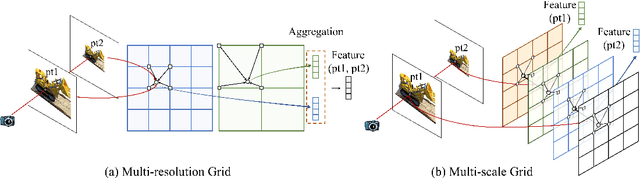
Despite the remarkable achievements of neural radiance fields (NeRF) in representing 3D scenes and generating novel view images, the aliasing issue, rendering "jaggies" or "blurry" images at varying camera distances, remains unresolved in most existing approaches. The recently proposed mip-NeRF has addressed this challenge by rendering conical frustums instead of rays. However, it relies on MLP architecture to represent the radiance fields, missing out on the fast training speed offered by the latest grid-based methods. In this work, we present mip-Grid, a novel approach that integrates anti-aliasing techniques into grid-based representations for radiance fields, mitigating the aliasing artifacts while enjoying fast training time. The proposed method generates multi-scale grids by applying simple convolution operations over a shared grid representation and uses the scale-aware coordinate to retrieve features at different scales from the generated multi-scale grids. To test the effectiveness, we integrated the proposed method into the two recent representative grid-based methods, TensoRF and K-Planes. Experimental results demonstrate that mip-Grid greatly improves the rendering performance of both methods and even outperforms mip-NeRF on multi-scale datasets while achieving significantly faster training time. For code and demo videos, please see https://stnamjef.github.io/mipgrid.github.io/.
Coordinate-Aware Modulation for Neural Fields
Nov 25, 2023


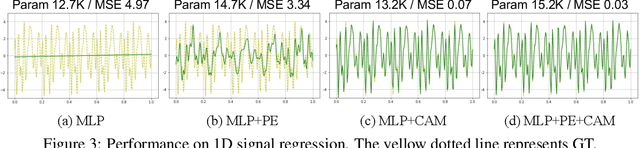
Neural fields, mapping low-dimensional input coordinates to corresponding signals, have shown promising results in representing various signals. Numerous methodologies have been proposed, and techniques employing MLPs and grid representations have achieved substantial success. MLPs allow compact and high expressibility, yet often suffer from spectral bias and slow convergence speed. On the other hand, methods using grids are free from spectral bias and achieve fast training speed, however, at the expense of high spatial complexity. In this work, we propose a novel way for exploiting both MLPs and grid representations in neural fields. Unlike the prevalent methods that combine them sequentially (extract features from the grids first and feed them to the MLP), we inject spectral bias-free grid representations into the intermediate features in the MLP. More specifically, we suggest a Coordinate-Aware Modulation (CAM), which modulates the intermediate features using scale and shift parameters extracted from the grid representations. This can maintain the strengths of MLPs while mitigating any remaining potential biases, facilitating the rapid learning of high-frequency components. In addition, we empirically found that the feature normalizations, which have not been successful in neural filed literature, proved to be effective when applied in conjunction with the proposed CAM. Experimental results demonstrate that CAM enhances the performance of neural representation and improves learning stability across a range of signals. Especially in the novel view synthesis task, we achieved state-of-the-art performance with the least number of parameters and fast training speed for dynamic scenes and the best performance under 1MB memory for static scenes. CAM also outperforms the best-performing video compression methods using neural fields by a large margin.
Compact 3D Gaussian Representation for Radiance Field
Nov 22, 2023Neural Radiance Fields (NeRFs) have demonstrated remarkable potential in capturing complex 3D scenes with high fidelity. However, one persistent challenge that hinders the widespread adoption of NeRFs is the computational bottleneck due to the volumetric rendering. On the other hand, 3D Gaussian splatting (3DGS) has recently emerged as an alternative representation that leverages a 3D Gaussisan-based representation and adopts the rasterization pipeline to render the images rather than volumetric rendering, achieving very fast rendering speed and promising image quality. However, a significant drawback arises as 3DGS entails a substantial number of 3D Gaussians to maintain the high fidelity of the rendered images, which requires a large amount of memory and storage. To address this critical issue, we place a specific emphasis on two key objectives: reducing the number of Gaussian points without sacrificing performance and compressing the Gaussian attributes, such as view-dependent color and covariance. To this end, we propose a learnable mask strategy that significantly reduces the number of Gaussians while preserving high performance. In addition, we propose a compact but effective representation of view-dependent color by employing a grid-based neural field rather than relying on spherical harmonics. Finally, we learn codebooks to compactly represent the geometric attributes of Gaussian by vector quantization. In our extensive experiments, we consistently show over 10$\times$ reduced storage and enhanced rendering speed, while maintaining the quality of the scene representation, compared to 3DGS. Our work provides a comprehensive framework for 3D scene representation, achieving high performance, fast training, compactness, and real-time rendering. Our project page is available at https://maincold2.github.io/c3dgs/.
Understanding Contrastive Learning Through the Lens of Margins
Jun 20, 2023
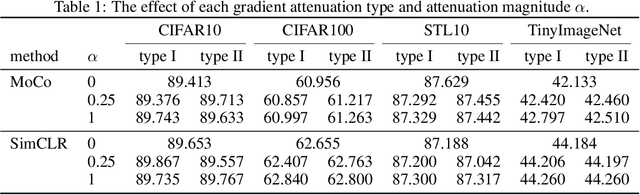
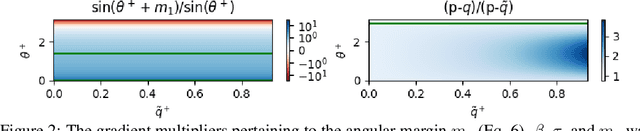
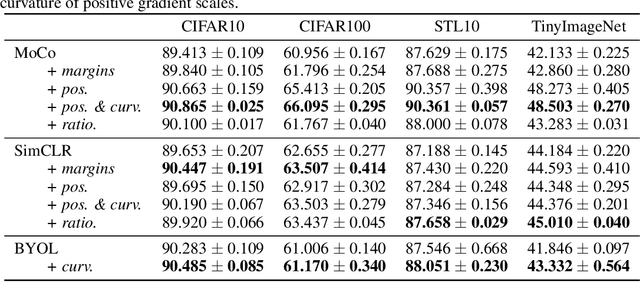
Self-supervised learning, or SSL, holds the key to expanding the usage of machine learning in real-world tasks by alleviating heavy human supervision. Contrastive learning and its varieties have been SSL strategies in various fields. We use margins as a stepping stone for understanding how contrastive learning works at a deeper level and providing potential directions to improve representation learning. Through gradient analysis, we found that margins scale gradients in three different ways: emphasizing positive samples, de-emphasizing positive samples when angles of positive samples are wide, and attenuating the diminishing gradients as the estimated probability approaches the target probability. We separately analyze each and provide possible directions for improving SSL frameworks. Our experimental results demonstrate that these properties can contribute to acquiring better representations, which can enhance performance in both seen and unseen datasets.
FFNeRV: Flow-Guided Frame-Wise Neural Representations for Videos
Dec 23, 2022Neural fields, also known as coordinate-based or implicit neural representations, have shown a remarkable capability of representing, generating, and manipulating various forms of signals. For video representations, however, mapping pixel-wise coordinates to RGB colors has shown relatively low compression performance and slow convergence and inference speed. Frame-wise video representation, which maps a temporal coordinate to its entire frame, has recently emerged as an alternative method to represent videos, improving compression rates and encoding speed. While promising, it has still failed to reach the performance of state-of-the-art video compression algorithms. In this work, we propose FFNeRV, a novel method for incorporating flow information into frame-wise representations to exploit the temporal redundancy across the frames in videos inspired by the standard video codecs. Furthermore, we introduce a fully convolutional architecture, enabled by one-dimensional temporal grids, improving the continuity of spatial features. Experimental results show that FFNeRV yields the best performance for video compression and frame interpolation among the methods using frame-wise representations or neural fields. To reduce the model size even further, we devise a more compact convolutional architecture using the group and pointwise convolutions. With model compression techniques, including quantization-aware training and entropy coding, FFNeRV outperforms widely-used standard video codecs (H.264 and HEVC) and performs on par with state-of-the-art video compression algorithms.
Masked Wavelet Representation for Compact Neural Radiance Fields
Dec 18, 2022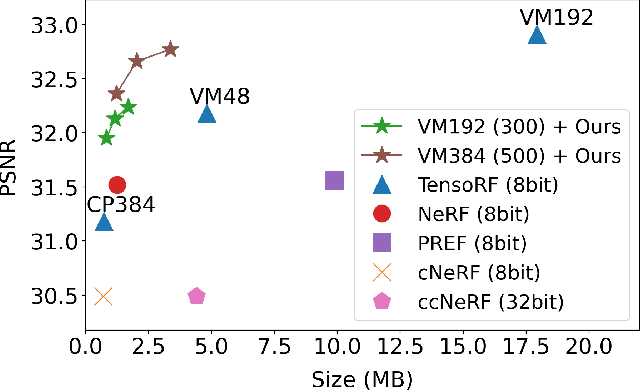


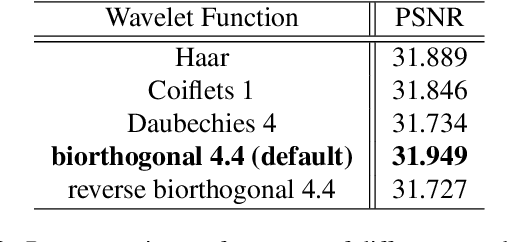
Neural radiance fields (NeRF) have demonstrated the potential of coordinate-based neural representation (neural fields or implicit neural representation) in neural rendering. However, using a multi-layer perceptron (MLP) to represent a 3D scene or object requires enormous computational resources and time. There have been recent studies on how to reduce these computational inefficiencies by using additional data structures, such as grids or trees. Despite the promising performance, the explicit data structure necessitates a substantial amount of memory. In this work, we present a method to reduce the size without compromising the advantages of having additional data structures. In detail, we propose using the wavelet transform on grid-based neural fields. Grid-based neural fields are for fast convergence, and the wavelet transform, whose efficiency has been demonstrated in high-performance standard codecs, is to improve the parameter efficiency of grids. Furthermore, in order to achieve a higher sparsity of grid coefficients while maintaining reconstruction quality, we present a novel trainable masking approach. Experimental results demonstrate that non-spatial grid coefficients, such as wavelet coefficients, are capable of attaining a higher level of sparsity than spatial grid coefficients, resulting in a more compact representation. With our proposed mask and compression pipeline, we achieved state-of-the-art performance within a memory budget of 2 MB. Our code is available at https://github.com/daniel03c1/masked_wavelet_nerf.