 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeeMamba: Efficient Acceleration Framework for Mamba Models in Edge Computing
Aug 14, 2025State Space Model (SSM)-based machine learning architectures have recently gained significant attention for processing sequential data. Mamba, a recent sequence-to-sequence SSM, offers competitive accuracy with superior computational efficiency compared to state-of-the-art transformer models. While this advantage makes Mamba particularly promising for resource-constrained edge devices, no hardware acceleration frameworks are currently optimized for deploying it in such environments. This paper presents eMamba, a comprehensive end-to-end hardware acceleration framework explicitly designed for deploying Mamba models on edge platforms. eMamba maximizes computational efficiency by replacing complex normalization layers with lightweight hardware-aware alternatives and approximating expensive operations, such as SiLU activation and exponentiation, considering the target applications. Then, it performs an approximation-aware neural architecture search (NAS) to tune the learnable parameters used during approximation. Evaluations with Fashion-MNIST, CIFAR-10, and MARS, an open-source human pose estimation dataset, show eMamba achieves comparable accuracy to state-of-the-art techniques using 1.63-19.9$\times$ fewer parameters. In addition, it generalizes well to large-scale natural language tasks, demonstrating stable perplexity across varying sequence lengths on the WikiText2 dataset. We also quantize and implement the entire eMamba pipeline on an AMD ZCU102 FPGA and ASIC using GlobalFoundries (GF) 22 nm technology. Experimental results show 4.95-5.62$\times$ lower latency and 2.22-9.95$\times$ higher throughput, with 4.77$\times$ smaller area, 9.84$\times$ lower power, and 48.6$\times$ lower energy consumption than baseline solutions while maintaining competitive accuracy.
Enhancing Multi-Exposure High Dynamic Range Imaging with Overlapped Codebook for Improved Representation Learning
Jul 02, 2025High dynamic range (HDR) imaging technique aims to create realistic HDR images from low dynamic range (LDR) inputs. Specifically, Multi-exposure HDR imaging uses multiple LDR frames taken from the same scene to improve reconstruction performance. However, there are often discrepancies in motion among the frames, and different exposure settings for each capture can lead to saturated regions. In this work, we first propose an Overlapped codebook (OLC) scheme, which can improve the capability of the VQGAN framework for learning implicit HDR representations by modeling the common exposure bracket process in the shared codebook structure. Further, we develop a new HDR network that utilizes HDR representations obtained from a pre-trained VQ network and OLC. This allows us to compensate for saturated regions and enhance overall visual quality. We have tested our approach extensively on various datasets and have demonstrated that it outperforms previous methods both qualitatively and quantitatively
Active Learning for Continual Learning: Keeping the Past Alive in the Present
Jan 24, 2025Continual learning (CL) enables deep neural networks to adapt to ever-changing data distributions. In practice, there may be scenarios where annotation is costly, leading to active continual learning (ACL), which performs active learning (AL) for the CL scenarios when reducing the labeling cost by selecting the most informative subset is preferable. However, conventional AL strategies are not suitable for ACL, as they focus solely on learning the new knowledge, leading to catastrophic forgetting of previously learned tasks. Therefore, ACL requires a new AL strategy that can balance the prevention of catastrophic forgetting and the ability to quickly learn new tasks. In this paper, we propose AccuACL, Accumulated informativeness-based Active Continual Learning, by the novel use of the Fisher information matrix as a criterion for sample selection, derived from a theoretical analysis of the Fisher-optimality preservation properties within the framework of ACL, while also addressing the scalability issue of Fisher information-based AL. Extensive experiments demonstrate that AccuACL significantly outperforms AL baselines across various CL algorithms, increasing the average accuracy and forgetting by 23.8% and 17.0%, respectively, in average.
DIAR: Diffusion-model-guided Implicit Q-learning with Adaptive Revaluation
Oct 15, 2024



We propose a novel offline reinforcement learning (offline RL) approach, introducing the Diffusion-model-guided Implicit Q-learning with Adaptive Revaluation (DIAR) framework. We address two key challenges in offline RL: out-of-distribution samples and long-horizon problems. We leverage diffusion models to learn state-action sequence distributions and incorporate value functions for more balanced and adaptive decision-making. DIAR introduces an Adaptive Revaluation mechanism that dynamically adjusts decision lengths by comparing current and future state values, enabling flexible long-term decision-making. Furthermore, we address Q-value overestimation by combining Q-network learning with a value function guided by a diffusion model. The diffusion model generates diverse latent trajectories, enhancing policy robustness and generalization. As demonstrated in tasks like Maze2D, AntMaze, and Kitchen, DIAR consistently outperforms state-of-the-art algorithms in long-horizon, sparse-reward environments.
Diffusion-Based Offline RL for Improved Decision-Making in Augmented ARC Task
Oct 15, 2024



Effective long-term strategies enable AI systems to navigate complex environments by making sequential decisions over extended horizons. Similarly, reinforcement learning (RL) agents optimize decisions across sequences to maximize rewards, even without immediate feedback. To verify that Latent Diffusion-Constrained Q-learning (LDCQ), a prominent diffusion-based offline RL method, demonstrates strong reasoning abilities in multi-step decision-making, we aimed to evaluate its performance on the Abstraction and Reasoning Corpus (ARC). However, applying offline RL methodologies to enhance strategic reasoning in AI for solving tasks in ARC is challenging due to the lack of sufficient experience data in the ARC training set. To address this limitation, we introduce an augmented offline RL dataset for ARC, called Synthesized Offline Learning Data for Abstraction and Reasoning (SOLAR), along with the SOLAR-Generator, which generates diverse trajectory data based on predefined rules. SOLAR enables the application of offline RL methods by offering sufficient experience data. We synthesized SOLAR for a simple task and used it to train an agent with the LDCQ method. Our experiments demonstrate the effectiveness of the offline RL approach on a simple ARC task, showing the agent's ability to make multi-step sequential decisions and correctly identify answer states. These results highlight the potential of the offline RL approach to enhance AI's strategic reasoning capabilities.
Differentiable Modal Synthesis for Physical Modeling of Planar String Sound and Motion Simulation
Jul 07, 2024

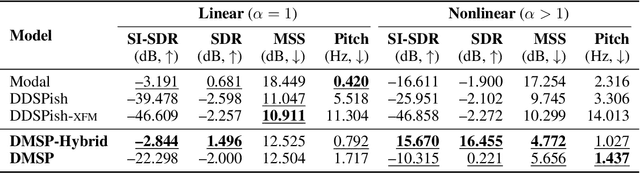
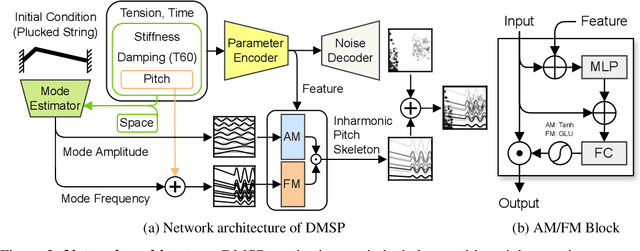
While significant advancements have been made in music generation and differentiable sound synthesis within machine learning and computer audition, the simulation of instrument vibration guided by physical laws has been underexplored. To address this gap, we introduce a novel model for simulating the spatio-temporal motion of nonlinear strings, integrating modal synthesis and spectral modeling within a neural network framework. Our model leverages physical properties and fundamental frequencies as inputs, outputting string states across time and space that solve the partial differential equation characterizing the nonlinear string. Empirical evaluations demonstrate that the proposed architecture achieves superior accuracy in string motion simulation compared to existing baseline architectures. The code and demo are available online.
Reinforcement Learning for Infinite-Horizon Average-Reward MDPs with Multinomial Logistic Function Approximation
Jun 19, 2024
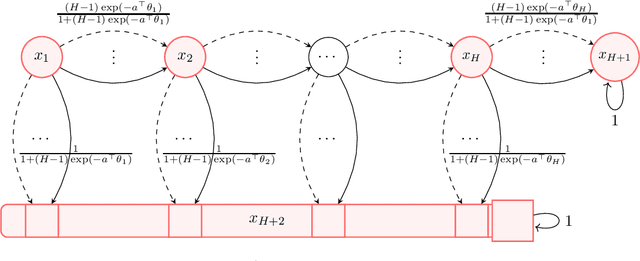

We study model-based reinforcement learning with non-linear function approximation where the transition function of the underlying Markov decision process (MDP) is given by a multinomial logistic (MNL) model. In this paper, we develop two algorithms for the infinite-horizon average reward setting. Our first algorithm \texttt{UCRL2-MNL} applies to the class of communicating MDPs and achieves an $\tilde{\mathcal{O}}(dD\sqrt{T})$ regret, where $d$ is the dimension of feature mapping, $D$ is the diameter of the underlying MDP, and $T$ is the horizon. The second algorithm \texttt{OVIFH-MNL} is computationally more efficient and applies to the more general class of weakly communicating MDPs, for which we show a regret guarantee of $\tilde{\mathcal{O}}(d^{2/5} \mathrm{sp}(v^*)T^{4/5})$ where $\mathrm{sp}(v^*)$ is the span of the associated optimal bias function. We also prove a lower bound of $\Omega(d\sqrt{DT})$ for learning communicating MDPs with MNL transitions of diameter at most $D$. Furthermore, we show a regret lower bound of $\Omega(dH^{3/2}\sqrt{K})$ for learning $H$-horizon episodic MDPs with MNL function approximation where $K$ is the number of episodes, which improves upon the best-known lower bound for the finite-horizon setting.
Understanding Contrastive Learning Through the Lens of Margins
Jun 20, 2023Self-supervised learning, or SSL, holds the key to expanding the usage of machine learning in real-world tasks by alleviating heavy human supervision. Contrastive learning and its varieties have been SSL strategies in various fields. We use margins as a stepping stone for understanding how contrastive learning works at a deeper level and providing potential directions to improve representation learning. Through gradient analysis, we found that margins scale gradients in three different ways: emphasizing positive samples, de-emphasizing positive samples when angles of positive samples are wide, and attenuating the diminishing gradients as the estimated probability approaches the target probability. We separately analyze each and provide possible directions for improving SSL frameworks. Our experimental results demonstrate that these properties can contribute to acquiring better representations, which can enhance performance in both seen and unseen datasets.
Unraveling the ARC Puzzle: Mimicking Human Solutions with Object-Centric Decision Transformer
Jun 14, 2023



In the pursuit of artificial general intelligence (AGI), we tackle Abstraction and Reasoning Corpus (ARC) tasks using a novel two-pronged approach. We employ the Decision Transformer in an imitation learning paradigm to model human problem-solving, and introduce an object detection algorithm, the Push and Pull clustering method. This dual strategy enhances AI's ARC problem-solving skills and provides insights for AGI progression. Yet, our work reveals the need for advanced data collection tools, robust training datasets, and refined model structures. This study highlights potential improvements for Decision Transformers and propels future AGI research.
Blind Estimation of Audio Processing Graph
Mar 15, 2023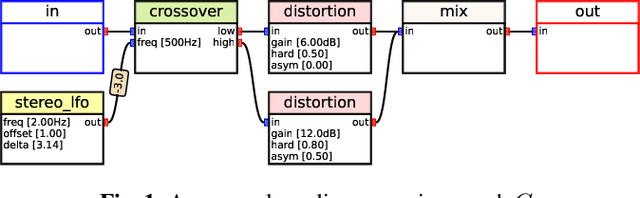



Musicians and audio engineers sculpt and transform their sounds by connecting multiple processors, forming an audio processing graph. However, most deep-learning methods overlook this real-world practice and assume fixed graph settings. To bridge this gap, we develop a system that reconstructs the entire graph from a given reference audio. We first generate a realistic graph-reference pair dataset and train a simple blind estimation system composed of a convolutional reference encoder and a transformer-based graph decoder. We apply our model to singing voice effects and drum mixing estimation tasks. Evaluation results show that our method can reconstruct complex signal routings, including multi-band processing and sidechaining.