 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReinforcement Learning for Infinite-Horizon Average-Reward MDPs with Multinomial Logistic Function Approximation
Paper and Code
Jun 19, 2024
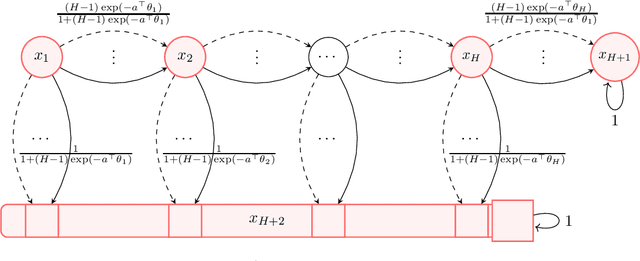

We study model-based reinforcement learning with non-linear function approximation where the transition function of the underlying Markov decision process (MDP) is given by a multinomial logistic (MNL) model. In this paper, we develop two algorithms for the infinite-horizon average reward setting. Our first algorithm \texttt{UCRL2-MNL} applies to the class of communicating MDPs and achieves an $\tilde{\mathcal{O}}(dD\sqrt{T})$ regret, where $d$ is the dimension of feature mapping, $D$ is the diameter of the underlying MDP, and $T$ is the horizon. The second algorithm \texttt{OVIFH-MNL} is computationally more efficient and applies to the more general class of weakly communicating MDPs, for which we show a regret guarantee of $\tilde{\mathcal{O}}(d^{2/5} \mathrm{sp}(v^*)T^{4/5})$ where $\mathrm{sp}(v^*)$ is the span of the associated optimal bias function. We also prove a lower bound of $\Omega(d\sqrt{DT})$ for learning communicating MDPs with MNL transitions of diameter at most $D$. Furthermore, we show a regret lower bound of $\Omega(dH^{3/2}\sqrt{K})$ for learning $H$-horizon episodic MDPs with MNL function approximation where $K$ is the number of episodes, which improves upon the best-known lower bound for the finite-horizon setting.