 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNear-Optimal Primal-Dual Algorithm for Learning Linear Mixture CMDPs with Adversarial Rewards
Mar 29, 2026We study safe reinforcement learning in finite-horizon linear mixture constrained Markov decision processes (CMDPs) with adversarial rewards under full-information feedback and an unknown transition kernel. We propose a primal-dual policy optimization algorithm that achieves regret and constraint violation bounds of $\widetilde{O}(\sqrt{d^2 H^3 K})$ under mild conditions, where $d$ is the feature dimension, $H$ is the horizon, and $K$ is the number of episodes. To the best of our knowledge, this is the first provably efficient algorithm for linear mixture CMDPs with adversarial rewards. In particular, our regret bound is near-optimal, matching the known minimax lower bound up to logarithmic factors. The key idea is to introduce a regularized dual update that enables a drift-based analysis. This step is essential, as strong duality-based analysis cannot be directly applied when reward functions change across episodes. In addition, we extend weighted ridge regression-based parameter estimation to the constrained setting, allowing us to construct tighter confidence intervals that are crucial for deriving the near-optimal regret bound.
Learning to Route and Schedule LLMs from User Retrials via Contextual Queueing Bandits
Feb 02, 2026Explosive demands for LLMs often cause user queries to accumulate in server queues, requiring efficient routing (query-LLM matching) and scheduling (query prioritization) mechanisms. Several online algorithms are being deployed, but they overlook the following two key challenges inherent to conversational LLM services: (1) unsatisfied users may retry queries, increasing the server backlog, and (2) requests for ``explicit" feedback, such as ratings, degrade user experiences. In this paper, we develop a joint routing and scheduling algorithm that leverages ``implicit" feedback inferred from user retrial behaviors. The key idea is to propose and study the framework of contextual queueing bandits with multinomial logit feedback (CQB-MNL). CQB-MNL models query retrials, as well as context-based learning for user preferences over LLMs. Our algorithm, anytime CQB (ACQB), achieves efficient learning while maintaining queue stability by combining Thompson sampling with forced exploration at a decaying rate. We show that ACQB simultaneously achieves a cumulative regret of $\widetilde{\mathcal{O}}(\sqrt{t})$ for routing and a queue length regret of $\widetilde{\mathcal{O}}(t^{-1/4})$ for any large $t$. For experiments, we refine query embeddings via contrastive learning while adopting a disjoint parameter model to learn LLM-specific parameters. Experiments on SPROUT, EmbedLLM, and RouterBench datasets confirm that both algorithms consistently outperform baselines.
Queue Length Regret Bounds for Contextual Queueing Bandits
Jan 27, 2026We introduce contextual queueing bandits, a new context-aware framework for scheduling while simultaneously learning unknown service rates. Individual jobs carry heterogeneous contextual features, based on which the agent chooses a job and matches it with a server to maximize the departure rate. The service/departure rate is governed by a logistic model of the contextual feature with an unknown server-specific parameter. To evaluate the performance of a policy, we consider queue length regret, defined as the difference in queue length between the policy and the optimal policy. The main challenge in the analysis is that the lists of remaining job features in the queue may differ under our policy versus the optimal policy for a given time step, since they may process jobs in different orders. To address this, we propose the idea of policy-switching queues equipped with a sophisticated coupling argument. This leads to a novel queue length regret decomposition framework, allowing us to understand the short-term effect of choosing a suboptimal job-server pair and its long-term effect on queue state differences. We show that our algorithm, CQB-$\varepsilon$, achieves a regret upper bound of $\widetilde{\mathcal{O}}(T^{-1/4})$. We also consider the setting of adversarially chosen contexts, for which our second algorithm, CQB-Opt, achieves a regret upper bound of $\mathcal{O}(\log^2 T)$. Lastly, we provide experimental results that validate our theoretical findings.
An Optimistic Algorithm for online CMDPS with Anytime Adversarial Constraints
May 28, 2025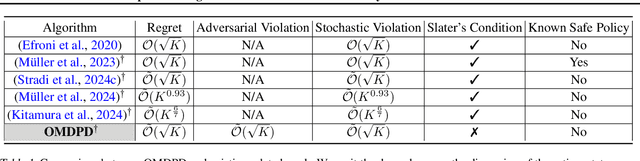
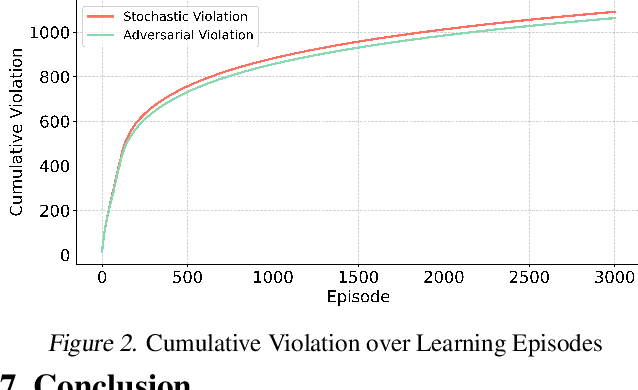
Online safe reinforcement learning (RL) plays a key role in dynamic environments, with applications in autonomous driving, robotics, and cybersecurity. The objective is to learn optimal policies that maximize rewards while satisfying safety constraints modeled by constrained Markov decision processes (CMDPs). Existing methods achieve sublinear regret under stochastic constraints but often fail in adversarial settings, where constraints are unknown, time-varying, and potentially adversarially designed. In this paper, we propose the Optimistic Mirror Descent Primal-Dual (OMDPD) algorithm, the first to address online CMDPs with anytime adversarial constraints. OMDPD achieves optimal regret O(sqrt(K)) and strong constraint violation O(sqrt(K)) without relying on Slater's condition or the existence of a strictly known safe policy. We further show that access to accurate estimates of rewards and transitions can further improve these bounds. Our results offer practical guarantees for safe decision-making in adversarial environments.
Neural Logistic Bandits
May 04, 2025We study the problem of neural logistic bandits, where the main task is to learn an unknown reward function within a logistic link function using a neural network. Existing approaches either exhibit unfavorable dependencies on $\kappa$, where $1/\kappa$ represents the minimum variance of reward distributions, or suffer from direct dependence on the feature dimension $d$, which can be huge in neural network-based settings. In this work, we introduce a novel Bernstein-type inequality for self-normalized vector-valued martingales that is designed to bypass a direct dependence on the ambient dimension. This lets us deduce a regret upper bound that grows with the effective dimension $\widetilde{d}$, not the feature dimension, while keeping a minimal dependence on $\kappa$. Based on the concentration inequality, we propose two algorithms, NeuralLog-UCB-1 and NeuralLog-UCB-2, that guarantee regret upper bounds of order $\widetilde{O}(\widetilde{d}\sqrt{\kappa T})$ and $\widetilde{O}(\widetilde{d}\sqrt{T/\kappa})$, respectively, improving on the existing results. Lastly, we report numerical results on both synthetic and real datasets to validate our theoretical findings.
Improved Regret Bound for Safe Reinforcement Learning via Tighter Cost Pessimism and Reward Optimism
Oct 14, 2024This paper studies the safe reinforcement learning problem formulated as an episodic finite-horizon tabular constrained Markov decision process with an unknown transition kernel and stochastic reward and cost functions. We propose a model-based algorithm based on novel cost and reward function estimators that provide tighter cost pessimism and reward optimism. While guaranteeing no constraint violation in every episode, our algorithm achieves a regret upper bound of $\widetilde{\mathcal{O}}((\bar C - \bar C_b)^{-1}H^{2.5} S\sqrt{AK})$ where $\bar C$ is the cost budget for an episode, $\bar C_b$ is the expected cost under a safe baseline policy over an episode, $H$ is the horizon, and $S$, $A$ and $K$ are the number of states, actions, and episodes, respectively. This improves upon the best-known regret upper bound, and when $\bar C- \bar C_b=\Omega(H)$, it nearly matches the regret lower bound of $\Omega(H^{1.5}\sqrt{SAK})$. We deduce our cost and reward function estimators via a Bellman-type law of total variance to obtain tight bounds on the expected sum of the variances of value function estimates. This leads to a tighter dependence on the horizon in the function estimators. We also present numerical results to demonstrate the computational effectiveness of our proposed framework.
Provably Efficient Infinite-Horizon Average-Reward Reinforcement Learning with Linear Function Approximation
Sep 16, 2024This paper proposes a computationally tractable algorithm for learning infinite-horizon average-reward linear Markov decision processes (MDPs) and linear mixture MDPs under the Bellman optimality condition. While guaranteeing computational efficiency, our algorithm for linear MDPs achieves the best-known regret upper bound of $\widetilde{\mathcal{O}}(d^{3/2}\mathrm{sp}(v^*)\sqrt{T})$ over $T$ time steps where $\mathrm{sp}(v^*)$ is the span of the optimal bias function $v^*$ and $d$ is the dimension of the feature mapping. For linear mixture MDPs, our algorithm attains a regret bound of $\widetilde{\mathcal{O}}(d\cdot\mathrm{sp}(v^*)\sqrt{T})$. The algorithm applies novel techniques to control the covering number of the value function class and the span of optimistic estimators of the value function, which is of independent interest.
Reinforcement Learning for Infinite-Horizon Average-Reward MDPs with Multinomial Logistic Function Approximation
Jun 19, 2024
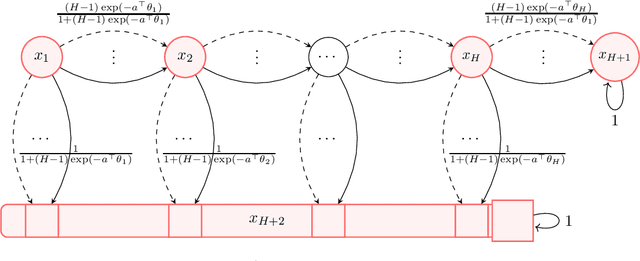

We study model-based reinforcement learning with non-linear function approximation where the transition function of the underlying Markov decision process (MDP) is given by a multinomial logistic (MNL) model. In this paper, we develop two algorithms for the infinite-horizon average reward setting. Our first algorithm \texttt{UCRL2-MNL} applies to the class of communicating MDPs and achieves an $\tilde{\mathcal{O}}(dD\sqrt{T})$ regret, where $d$ is the dimension of feature mapping, $D$ is the diameter of the underlying MDP, and $T$ is the horizon. The second algorithm \texttt{OVIFH-MNL} is computationally more efficient and applies to the more general class of weakly communicating MDPs, for which we show a regret guarantee of $\tilde{\mathcal{O}}(d^{2/5} \mathrm{sp}(v^*)T^{4/5})$ where $\mathrm{sp}(v^*)$ is the span of the associated optimal bias function. We also prove a lower bound of $\Omega(d\sqrt{DT})$ for learning communicating MDPs with MNL transitions of diameter at most $D$. Furthermore, we show a regret lower bound of $\Omega(dH^{3/2}\sqrt{K})$ for learning $H$-horizon episodic MDPs with MNL function approximation where $K$ is the number of episodes, which improves upon the best-known lower bound for the finite-horizon setting.
Parameter-Free Algorithms for Performative Regret Minimization under Decision-Dependent Distributions
Feb 23, 2024


This paper studies performative risk minimization, a formulation of stochastic optimization under decision-dependent distributions. We consider the general case where the performative risk can be non-convex, for which we develop efficient parameter-free optimistic optimization-based methods. Our algorithms significantly improve upon the existing Lipschitz bandit-based method in many aspects. In particular, our framework does not require knowledge about the sensitivity parameter of the distribution map and the Lipshitz constant of the loss function. This makes our framework practically favorable, together with the efficient optimistic optimization-based tree-search mechanism. We provide experimental results that demonstrate the numerical superiority of our algorithms over the existing method and other black-box optimistic optimization methods.
Stochastic-Constrained Stochastic Optimization with Markovian Data
Dec 07, 2023
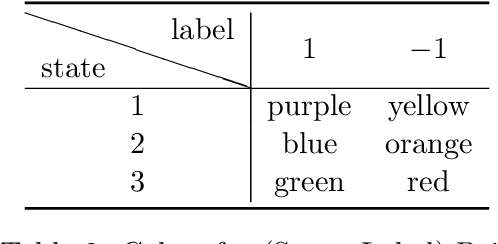
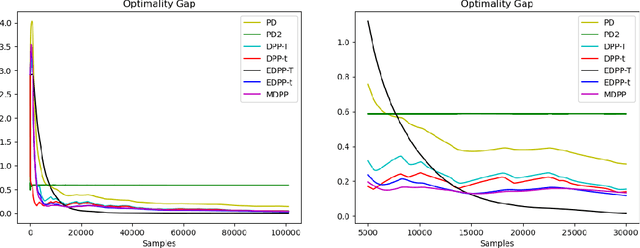
This paper considers stochastic-constrained stochastic optimization where the stochastic constraint is to satisfy that the expectation of a random function is below a certain threshold. In particular, we study the setting where data samples are drawn from a Markov chain and thus are not independent and identically distributed. We generalize the drift-plus-penalty framework, a primal-dual stochastic gradient method developed for the i.i.d. case, to the Markov chain sampling setting. We propose two variants of drift-plus-penalty; one is for the case when the mixing time of the underlying Markov chain is known while the other is for the case of unknown mixing time. In fact, our algorithms apply to a more general setting of constrained online convex optimization where the sequence of constraint functions follows a Markov chain. Both algorithms are adaptive in that the first works without knowledge of the time horizon while the second uses AdaGrad-style algorithm parameters, which is of independent interest. We demonstrate the effectiveness of our proposed methods through numerical experiments on classification with fairness constraints.