 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeedance 1.5 pro: A Native Audio-Visual Joint Generation Foundation Model
Dec 23, 2025Recent strides in video generation have paved the way for unified audio-visual generation. In this work, we present Seedance 1.5 pro, a foundational model engineered specifically for native, joint audio-video generation. Leveraging a dual-branch Diffusion Transformer architecture, the model integrates a cross-modal joint module with a specialized multi-stage data pipeline, achieving exceptional audio-visual synchronization and superior generation quality. To ensure practical utility, we implement meticulous post-training optimizations, including Supervised Fine-Tuning (SFT) on high-quality datasets and Reinforcement Learning from Human Feedback (RLHF) with multi-dimensional reward models. Furthermore, we introduce an acceleration framework that boosts inference speed by over 10X. Seedance 1.5 pro distinguishes itself through precise multilingual and dialect lip-syncing, dynamic cinematic camera control, and enhanced narrative coherence, positioning it as a robust engine for professional-grade content creation. Seedance 1.5 pro is now accessible on Volcano Engine at https://console.volcengine.com/ark/region:ark+cn-beijing/experience/vision?type=GenVideo.
An Optimistic Algorithm for online CMDPS with Anytime Adversarial Constraints
May 28, 2025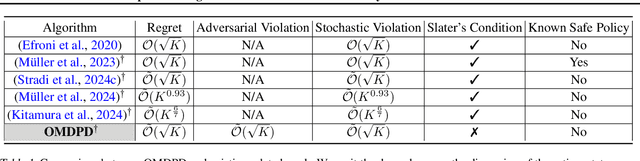
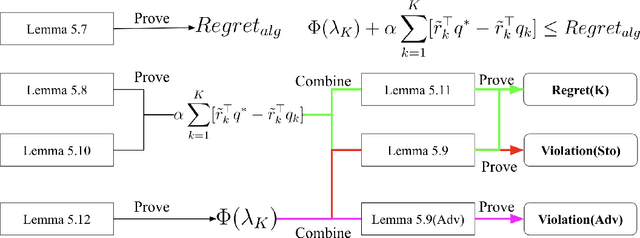
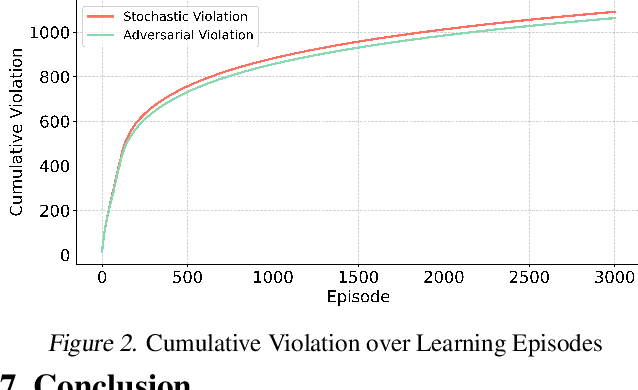
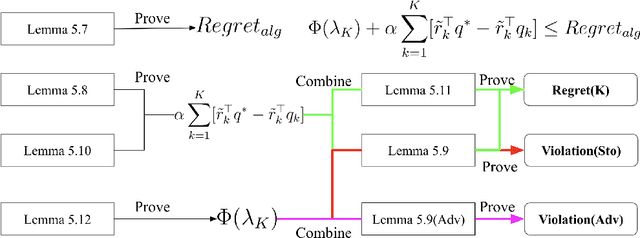
Online safe reinforcement learning (RL) plays a key role in dynamic environments, with applications in autonomous driving, robotics, and cybersecurity. The objective is to learn optimal policies that maximize rewards while satisfying safety constraints modeled by constrained Markov decision processes (CMDPs). Existing methods achieve sublinear regret under stochastic constraints but often fail in adversarial settings, where constraints are unknown, time-varying, and potentially adversarially designed. In this paper, we propose the Optimistic Mirror Descent Primal-Dual (OMDPD) algorithm, the first to address online CMDPs with anytime adversarial constraints. OMDPD achieves optimal regret O(sqrt(K)) and strong constraint violation O(sqrt(K)) without relying on Slater's condition or the existence of a strictly known safe policy. We further show that access to accurate estimates of rewards and transitions can further improve these bounds. Our results offer practical guarantees for safe decision-making in adversarial environments.
ONER: Online Experience Replay for Incremental Anomaly Detection
Dec 05, 2024Incremental anomaly detection sequentially recognizes abnormal regions in novel categories for dynamic industrial scenarios. This remains highly challenging due to knowledge overwriting and feature conflicts, leading to catastrophic forgetting. In this work, we propose ONER, an end-to-end ONline Experience Replay method, which efficiently mitigates catastrophic forgetting while adapting to new tasks with minimal cost. Specifically, our framework utilizes two types of experiences from past tasks: decomposed prompts and semantic prototypes, addressing both model parameter updates and feature optimization. The decomposed prompts consist of learnable components that assemble to produce attention-conditioned prompts. These prompts reuse previously learned knowledge, enabling model to learn novel tasks effectively. The semantic prototypes operate at both pixel and image levels, performing regularization in the latent feature space to prevent forgetting across various tasks. Extensive experiments demonstrate that our method achieves state-of-the-art performance in incremental anomaly detection with significantly reduced forgetting, as well as efficiently adapting to new categories with minimal costs. These results confirm the efficiency and stability of ONER, making it a powerful solution for real-world applications.
A Survey on Data Synthesis and Augmentation for Large Language Models
Oct 16, 2024The success of Large Language Models (LLMs) is inherently linked to the availability of vast, diverse, and high-quality data for training and evaluation. However, the growth rate of high-quality data is significantly outpaced by the expansion of training datasets, leading to a looming data exhaustion crisis. This underscores the urgent need to enhance data efficiency and explore new data sources. In this context, synthetic data has emerged as a promising solution. Currently, data generation primarily consists of two major approaches: data augmentation and synthesis. This paper comprehensively reviews and summarizes data generation techniques throughout the lifecycle of LLMs, including data preparation, pre-training, fine-tuning, instruction-tuning, preference alignment, and applications. Furthermore, We discuss the current constraints faced by these methods and investigate potential pathways for future development and research. Our aspiration is to equip researchers with a clear understanding of these methodologies, enabling them to swiftly identify appropriate data generation strategies in the construction of LLMs, while providing valuable insights for future exploration.
Deja vu: Contrastive Historical Modeling with Prefix-tuning for Temporal Knowledge Graph Reasoning
Mar 25, 2024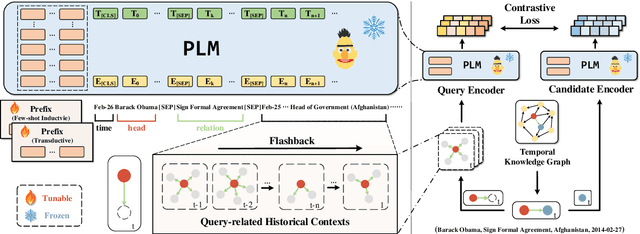
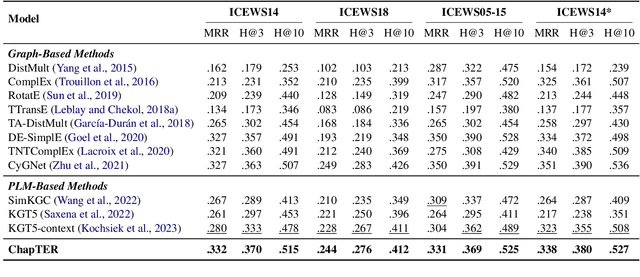
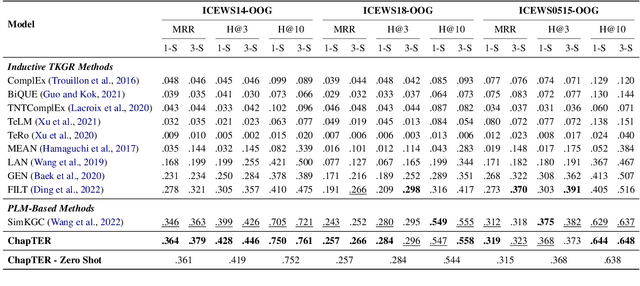
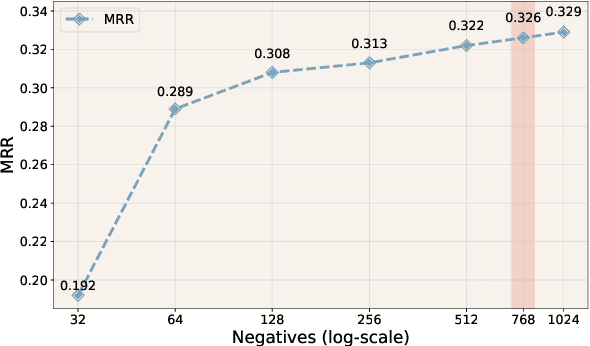
Temporal Knowledge Graph Reasoning (TKGR) is the task of inferring missing facts for incomplete TKGs in complex scenarios (e.g., transductive and inductive settings), which has been gaining increasing attention. Recently, to mitigate dependence on structured connections in TKGs, text-based methods have been developed to utilize rich linguistic information from entity descriptions. However, suffering from the enormous parameters and inflexibility of pre-trained language models, existing text-based methods struggle to balance the textual knowledge and temporal information with computationally expensive purpose-built training strategies. To tap the potential of text-based models for TKGR in various complex scenarios, we propose ChapTER, a Contrastive historical modeling framework with prefix-tuning for TEmporal Reasoning. ChapTER feeds history-contextualized text into the pseudo-Siamese encoders to strike a textual-temporal balance via contrastive estimation between queries and candidates. By introducing virtual time prefix tokens, it applies a prefix-based tuning method to facilitate the frozen PLM capable for TKGR tasks under different settings. We evaluate ChapTER on four transductive and three few-shot inductive TKGR benchmarks, and experimental results demonstrate that ChapTER achieves superior performance compared to competitive baselines with only 0.17% tuned parameters. We conduct thorough analysis to verify the effectiveness, flexibility and efficiency of ChapTER.
A Synchronized Reprojection-based Model for 3D Human Pose Estimation
Jun 16, 2021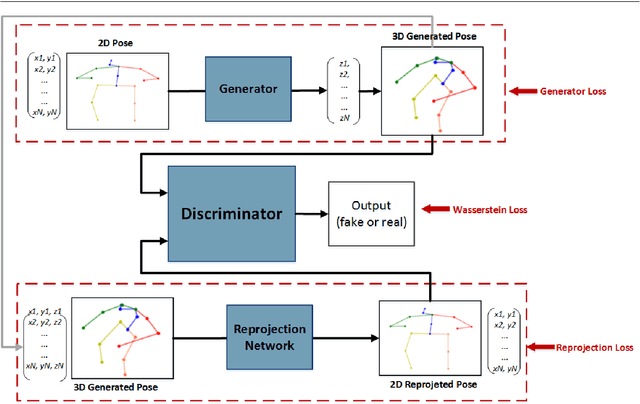
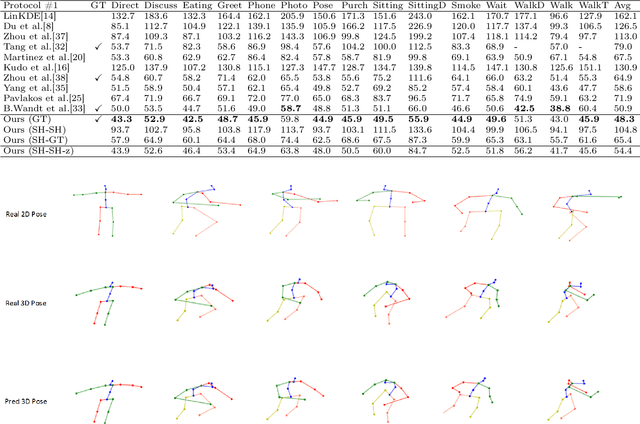
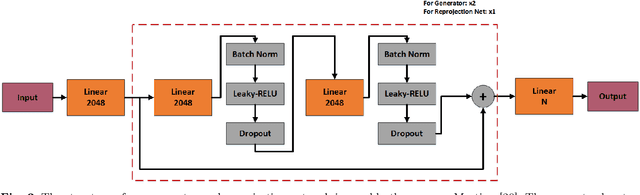
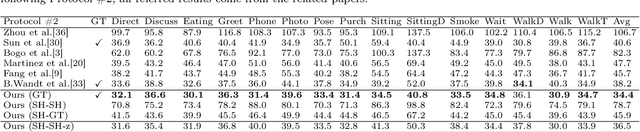
3D human pose estimation is still a challenging problem despite the large amount of work that has been done in this field. Generally, most methods directly use neural networks and ignore certain constraints (e.g., reprojection constraints and joint angle and bone length constraints). This paper proposes a weakly supervised GAN-based model for 3D human pose estimation that considers 3D information along with 2D information simultaneously, in which a reprojection network is employed to learn the mapping of the distribution from 3D poses to 2D poses. In particular, we train the reprojection network and the generative adversarial network synchronously. Furthermore, inspired by the typical kinematic chain space (KCS) matrix, we propose a weighted KCS matrix, which is added into the discriminator's input to impose joint angle and bone length constraints. The experimental results on Human3.6M show that our method outperforms state-of-the-art methods by approximately 5.1\%.
SVMA: A GAN-based model for Monocular 3D Human Pose Estimation
Jun 16, 2021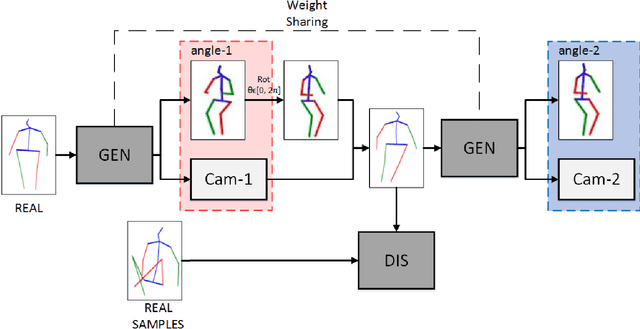
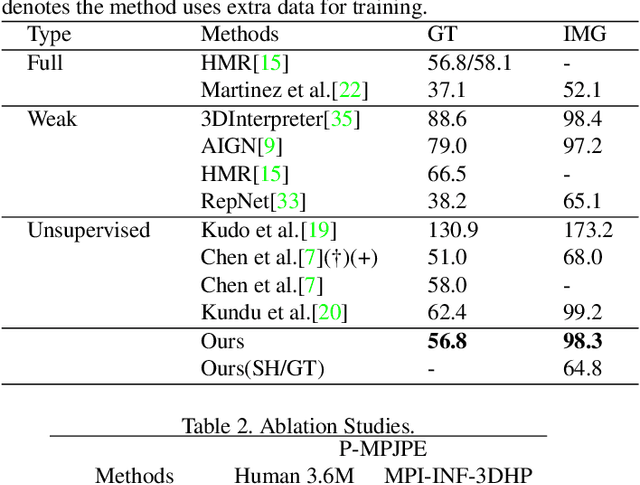
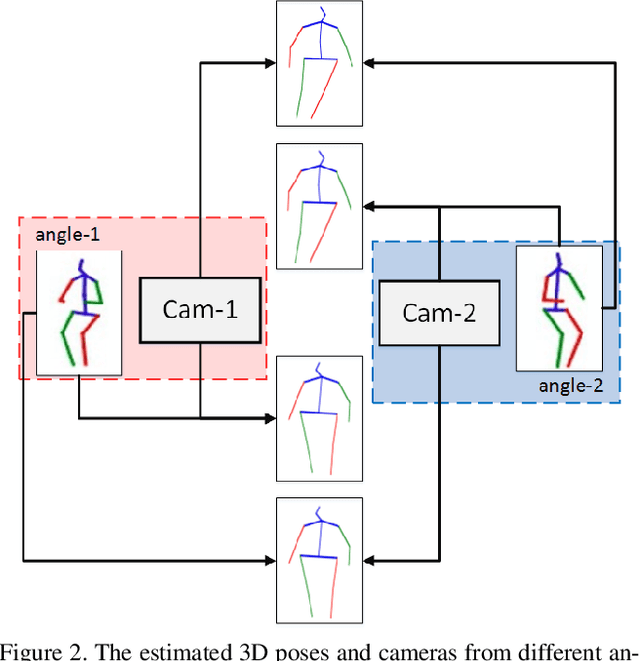
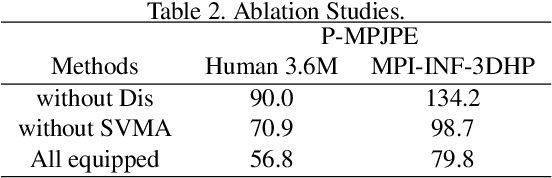
Recovering 3D human pose from 2D joints is a highly unconstrained problem, especially without any video or multi-view information. We present an unsupervised GAN-based model to recover 3D human pose from 2D joint locations extracted from a single image. Our model uses a GAN to learn the mapping of distribution from 2D poses to 3D poses, not the simple 2D-3D correspondence. Considering the reprojection constraint, our model can estimate the camera so that we can reproject the estimated 3D pose to the original 2D pose. Based on this reprojection method, we can rotate and reproject the generated pose to get our "new" 2D pose and then use a weight sharing generator to estimate the "new" 3D pose and a "new" camera. Through the above estimation process, we can define the single-view-multi-angle consistency loss during training to simulate multi-view consistency, which means the 3D poses and cameras estimated from two angles of a single view should be able to be mixed to generate rich 2D reprojections, and the 2D reprojections reprojected from the same 3D pose should be consistent. The experimental results on Human3.6M show that our method outperforms all the state-of-the-art methods, and results on MPI-INF-3DHP show that our method outperforms state-of-the-art by approximately 15.0%.