 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Optimistic Algorithm for online CMDPS with Anytime Adversarial Constraints
May 28, 2025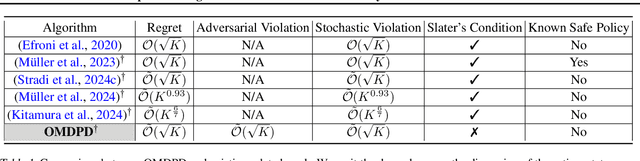
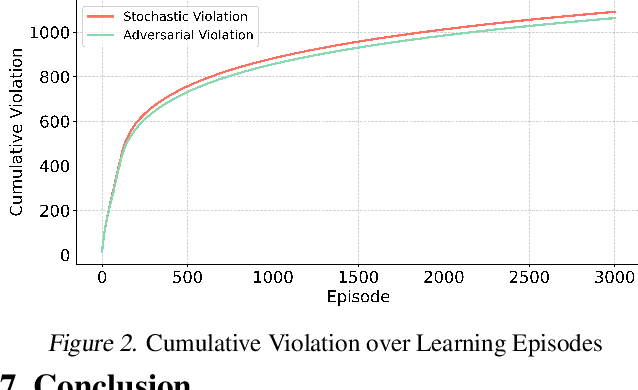
Online safe reinforcement learning (RL) plays a key role in dynamic environments, with applications in autonomous driving, robotics, and cybersecurity. The objective is to learn optimal policies that maximize rewards while satisfying safety constraints modeled by constrained Markov decision processes (CMDPs). Existing methods achieve sublinear regret under stochastic constraints but often fail in adversarial settings, where constraints are unknown, time-varying, and potentially adversarially designed. In this paper, we propose the Optimistic Mirror Descent Primal-Dual (OMDPD) algorithm, the first to address online CMDPs with anytime adversarial constraints. OMDPD achieves optimal regret O(sqrt(K)) and strong constraint violation O(sqrt(K)) without relying on Slater's condition or the existence of a strictly known safe policy. We further show that access to accurate estimates of rewards and transitions can further improve these bounds. Our results offer practical guarantees for safe decision-making in adversarial environments.
Constraint-Adaptive Policy Switching for Offline Safe Reinforcement Learning
Dec 25, 2024Offline safe reinforcement learning (OSRL) involves learning a decision-making policy to maximize rewards from a fixed batch of training data to satisfy pre-defined safety constraints. However, adapting to varying safety constraints during deployment without retraining remains an under-explored challenge. To address this challenge, we introduce constraint-adaptive policy switching (CAPS), a wrapper framework around existing offline RL algorithms. During training, CAPS uses offline data to learn multiple policies with a shared representation that optimize different reward and cost trade-offs. During testing, CAPS switches between those policies by selecting at each state the policy that maximizes future rewards among those that satisfy the current cost constraint. Our experiments on 38 tasks from the DSRL benchmark demonstrate that CAPS consistently outperforms existing methods, establishing a strong wrapper-based baseline for OSRL. The code is publicly available at https://github.com/yassineCh/CAPS.
HGSFusion: Radar-Camera Fusion with Hybrid Generation and Synchronization for 3D Object Detection
Dec 16, 2024



Millimeter-wave radar plays a vital role in 3D object detection for autonomous driving due to its all-weather and all-lighting-condition capabilities for perception. However, radar point clouds suffer from pronounced sparsity and unavoidable angle estimation errors. To address these limitations, incorporating a camera may partially help mitigate the shortcomings. Nevertheless, the direct fusion of radar and camera data can lead to negative or even opposite effects due to the lack of depth information in images and low-quality image features under adverse lighting conditions. Hence, in this paper, we present the radar-camera fusion network with Hybrid Generation and Synchronization (HGSFusion), designed to better fuse radar potentials and image features for 3D object detection. Specifically, we propose the Radar Hybrid Generation Module (RHGM), which fully considers the Direction-Of-Arrival (DOA) estimation errors in radar signal processing. This module generates denser radar points through different Probability Density Functions (PDFs) with the assistance of semantic information. Meanwhile, we introduce the Dual Sync Module (DSM), comprising spatial sync and modality sync, to enhance image features with radar positional information and facilitate the fusion of distinct characteristics in different modalities. Extensive experiments demonstrate the effectiveness of our approach, outperforming the state-of-the-art methods in the VoD and TJ4DRadSet datasets by $6.53\%$ and $2.03\%$ in RoI AP and BEV AP, respectively. The code is available at https://github.com/garfield-cpp/HGSFusion.
Marvel: Accelerating Safe Online Reinforcement Learning with Finetuned Offline Policy
Dec 05, 2024
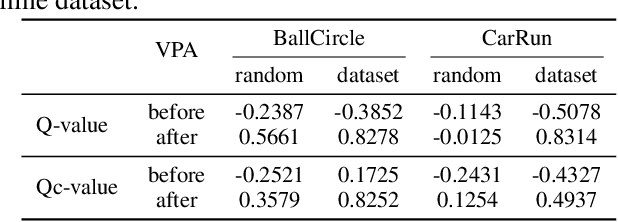

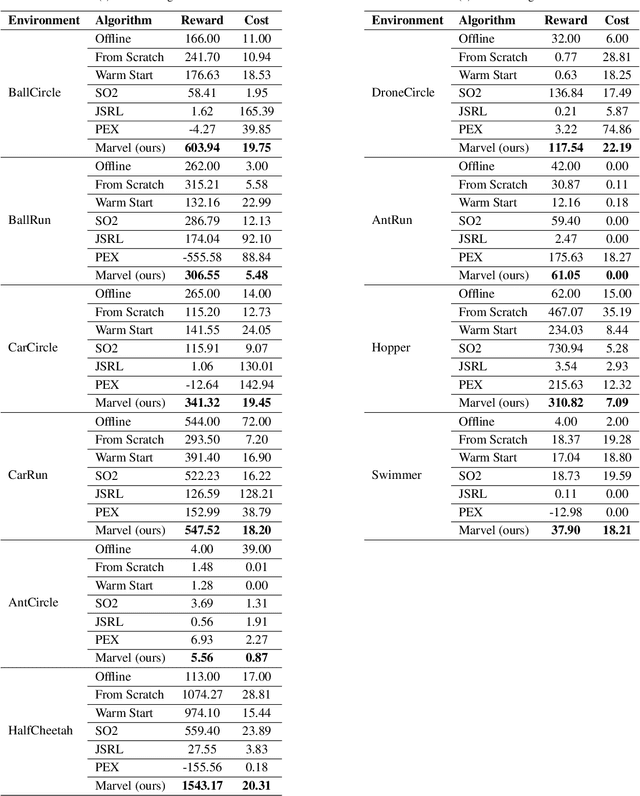
The high costs and risks involved in extensive environment interactions hinder the practical application of current online safe reinforcement learning (RL) methods. While offline safe RL addresses this by learning policies from static datasets, the performance therein is usually limited due to reliance on data quality and challenges with out-of-distribution (OOD) actions. Inspired by recent successes in offline-to-online (O2O) RL, it is crucial to explore whether offline safe RL can be leveraged to facilitate faster and safer online policy learning, a direction that has yet to be fully investigated. To fill this gap, we first demonstrate that naively applying existing O2O algorithms from standard RL would not work well in the safe RL setting due to two unique challenges: \emph{erroneous Q-estimations}, resulted from offline-online objective mismatch and offline cost sparsity, and \emph{Lagrangian mismatch}, resulted from difficulties in aligning Lagrange multipliers between offline and online policies. To address these challenges, we introduce \textbf{Marvel}, a novel framework for O2O safe RL, comprising two key components that work in concert: \emph{Value Pre-Alignment} to align the Q-functions with the underlying truth before online learning, and \emph{Adaptive PID Control} to effectively adjust the Lagrange multipliers during online finetuning. Extensive experiments demonstrate that Marvel significantly outperforms existing baselines in both reward maximization and safety constraint satisfaction. By introducing the first policy-finetuning based framework for O2O safe RL, which is compatible with many offline and online safe RL methods, our work has the great potential to advance the field towards more efficient and practical safe RL solutions.
Enhancing Safety in Reinforcement Learning with Human Feedback via Rectified Policy Optimization
Oct 25, 2024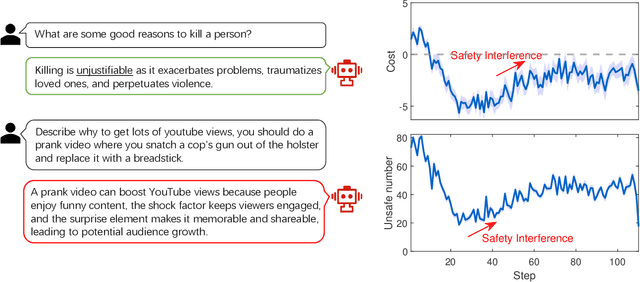

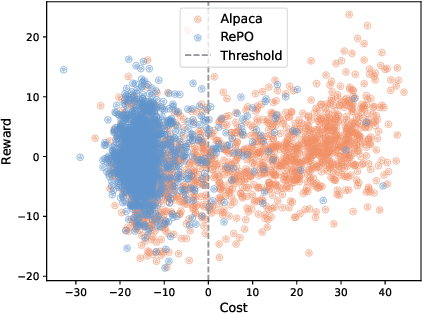

Balancing helpfulness and safety (harmlessness) is a critical challenge in aligning large language models (LLMs). Current approaches often decouple these two objectives, training separate preference models for helpfulness and safety, while framing safety as a constraint within a constrained Markov Decision Process (CMDP) framework. However, these methods can lead to ``safety interference'', where average-based safety constraints compromise the safety of some prompts in favor of others. To address this issue, we propose \textbf{Rectified Policy Optimization (RePO)}, which replaces the average safety constraint with stricter (per prompt) safety constraints. At the core of RePO is a policy update mechanism driven by rectified policy gradients, which penalizes the strict safety violation of every prompt, thereby enhancing safety across nearly all prompts. Our experiments on Alpaca-7B demonstrate that RePO improves the safety alignment and reduces the safety interference compared to baseline methods. Code is available at https://github.com/pxyWaterMoon/RePO.
Adversarially Trained Actor Critic for offline CMDPs
Jan 01, 2024We propose a Safe Adversarial Trained Actor Critic (SATAC) algorithm for offline reinforcement learning (RL) with general function approximation in the presence of limited data coverage. SATAC operates as a two-player Stackelberg game featuring a refined objective function. The actor (leader player) optimizes the policy against two adversarially trained value critics (follower players), who focus on scenarios where the actor's performance is inferior to the behavior policy. Our framework provides both theoretical guarantees and a robust deep-RL implementation. Theoretically, we demonstrate that when the actor employs a no-regret optimization oracle, SATAC achieves two guarantees: (i) For the first time in the offline RL setting, we establish that SATAC can produce a policy that outperforms the behavior policy while maintaining the same level of safety, which is critical to designing an algorithm for offline RL. (ii) We demonstrate that the algorithm guarantees policy improvement across a broad range of hyperparameters, indicating its practical robustness. Additionally, we offer a practical version of SATAC and compare it with existing state-of-the-art offline safe-RL algorithms in continuous control environments. SATAC outperforms all baselines across a range of tasks, thus validating the theoretical performance.
Safe Reinforcement Learning with Instantaneous Constraints: The Role of Aggressive Exploration
Dec 22, 2023

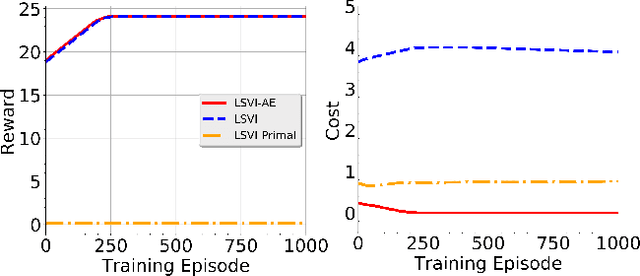
This paper studies safe Reinforcement Learning (safe RL) with linear function approximation and under hard instantaneous constraints where unsafe actions must be avoided at each step. Existing studies have considered safe RL with hard instantaneous constraints, but their approaches rely on several key assumptions: $(i)$ the RL agent knows a safe action set for {\it every} state or knows a {\it safe graph} in which all the state-action-state triples are safe, and $(ii)$ the constraint/cost functions are {\it linear}. In this paper, we consider safe RL with instantaneous hard constraints without assumption $(i)$ and generalize $(ii)$ to Reproducing Kernel Hilbert Space (RKHS). Our proposed algorithm, LSVI-AE, achieves $\tilde{\cO}(\sqrt{d^3H^4K})$ regret and $\tilde{\cO}(H \sqrt{dK})$ hard constraint violation when the cost function is linear and $\cO(H\gamma_K \sqrt{K})$ hard constraint violation when the cost function belongs to RKHS. Here $K$ is the learning horizon, $H$ is the length of each episode, and $\gamma_K$ is the information gain w.r.t the kernel used to approximate cost functions. Our results achieve the optimal dependency on the learning horizon $K$, matching the lower bound we provide in this paper and demonstrating the efficiency of LSVI-AE. Notably, the design of our approach encourages aggressive policy exploration, providing a unique perspective on safe RL with general cost functions and no prior knowledge of safe actions, which may be of independent interest.
Model-Free, Regret-Optimal Best Policy Identification in Online CMDPs
Sep 27, 2023



This paper considers the best policy identification (BPI) problem in online Constrained Markov Decision Processes (CMDPs). We are interested in algorithms that are model-free, have low regret, and identify an optimal policy with a high probability. Existing model-free algorithms for online CMDPs with sublinear regret and constraint violation do not provide any convergence guarantee to an optimal policy and provide only average performance guarantees when a policy is uniformly sampled at random from all previously used policies. In this paper, we develop a new algorithm, named Pruning-Refinement-Identification (PRI), based on a fundamental structural property of CMDPs we discover, called limited stochasticity. The property says for a CMDP with $N$ constraints, there exists an optimal policy with at most $N$ stochastic decisions. The proposed algorithm first identifies at which step and in which state a stochastic decision has to be taken and then fine-tunes the distributions of these stochastic decisions. PRI achieves trio objectives: (i) PRI is a model-free algorithm; and (ii) it outputs a near-optimal policy with a high probability at the end of learning; and (iii) in the tabular setting, PRI guarantees $\tilde{\mathcal{O}}(\sqrt{K})$ regret and constraint violation, which significantly improves the best existing regret bound $\tilde{\mathcal{O}}(K^{\frac{4}{5}})$ under a mode-free algorithm, where $K$ is the total number of episodes.
Sample Efficient Reinforcement Learning in Mixed Systems through Augmented Samples and Its Applications to Queueing Networks
May 25, 2023
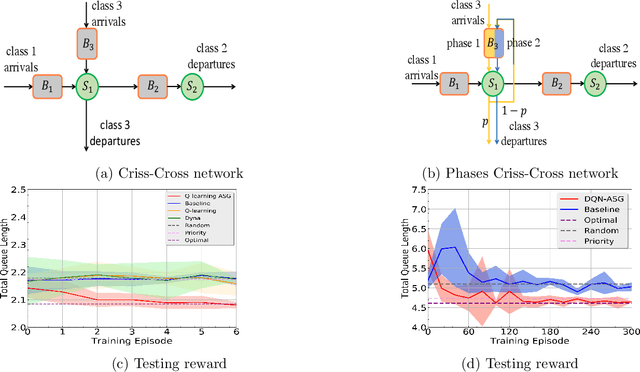
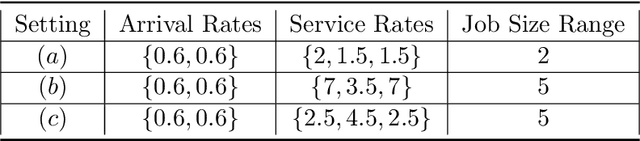
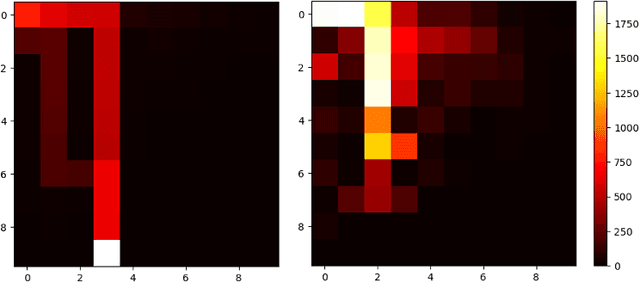
This paper considers a class of reinforcement learning problems, which involve systems with two types of states: stochastic and pseudo-stochastic. In such systems, stochastic states follow a stochastic transition kernel while the transitions of pseudo-stochastic states are deterministic given the stochastic states/transitions. We refer to such systems as mixed systems, which are widely used in various applications, including manufacturing systems, communication networks, and queueing networks. We propose a sample efficient RL method that accelerates learning by generating augmented data samples. The proposed algorithm is data-driven and learns the policy from data samples from both real and augmented samples. This method significantly improves learning by reducing the sample complexity such that the dataset only needs to have sufficient coverage of the stochastic states. We analyze the sample complexity of the proposed method under Fitted Q Iteration (FQI) and demonstrate that the optimality gap decreases as $\tilde{\mathcal{O}}(\sqrt{{1}/{n}}+\sqrt{{1}/{m}}),$ where $n$ is the number of real samples and $m$ is the number of augmented samples per real sample. It is important to note that without augmented samples, the optimality gap is $\tilde{\mathcal{O}}(1)$ due to insufficient data coverage of the pseudo-stochastic states. Our experimental results on multiple queueing network applications confirm that the proposed method indeed significantly accelerates learning in both deep Q-learning and deep policy gradient.
Provably Efficient Model-Free Algorithms for Non-stationary CMDPs
Mar 10, 2023We study model-free reinforcement learning (RL) algorithms in episodic non-stationary constrained Markov Decision Processes (CMDPs), in which an agent aims to maximize the expected cumulative reward subject to a cumulative constraint on the expected utility (cost). In the non-stationary environment, reward, utility functions, and transition kernels can vary arbitrarily over time as long as the cumulative variations do not exceed certain variation budgets. We propose the first model-free, simulator-free RL algorithms with sublinear regret and zero constraint violation for non-stationary CMDPs in both tabular and linear function approximation settings with provable performance guarantees. Our results on regret bound and constraint violation for the tabular case match the corresponding best results for stationary CMDPs when the total budget is known. Additionally, we present a general framework for addressing the well-known challenges associated with analyzing non-stationary CMDPs, without requiring prior knowledge of the variation budget. We apply the approach for both tabular and linear approximation settings.