 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Safety in Reinforcement Learning with Human Feedback via Rectified Policy Optimization
Oct 25, 2024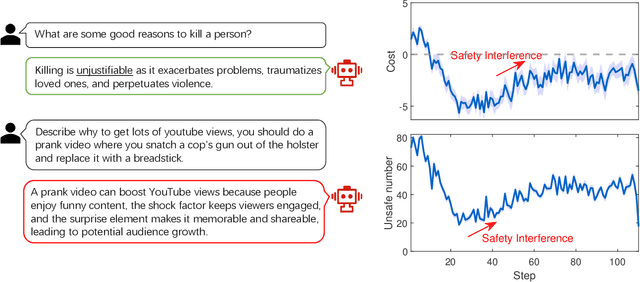

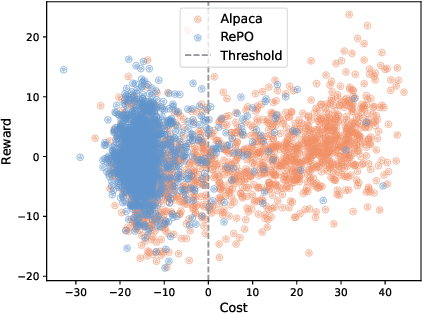

Balancing helpfulness and safety (harmlessness) is a critical challenge in aligning large language models (LLMs). Current approaches often decouple these two objectives, training separate preference models for helpfulness and safety, while framing safety as a constraint within a constrained Markov Decision Process (CMDP) framework. However, these methods can lead to ``safety interference'', where average-based safety constraints compromise the safety of some prompts in favor of others. To address this issue, we propose \textbf{Rectified Policy Optimization (RePO)}, which replaces the average safety constraint with stricter (per prompt) safety constraints. At the core of RePO is a policy update mechanism driven by rectified policy gradients, which penalizes the strict safety violation of every prompt, thereby enhancing safety across nearly all prompts. Our experiments on Alpaca-7B demonstrate that RePO improves the safety alignment and reduces the safety interference compared to baseline methods. Code is available at https://github.com/pxyWaterMoon/RePO.
Adversarially Trained Actor Critic for offline CMDPs
Jan 01, 2024We propose a Safe Adversarial Trained Actor Critic (SATAC) algorithm for offline reinforcement learning (RL) with general function approximation in the presence of limited data coverage. SATAC operates as a two-player Stackelberg game featuring a refined objective function. The actor (leader player) optimizes the policy against two adversarially trained value critics (follower players), who focus on scenarios where the actor's performance is inferior to the behavior policy. Our framework provides both theoretical guarantees and a robust deep-RL implementation. Theoretically, we demonstrate that when the actor employs a no-regret optimization oracle, SATAC achieves two guarantees: (i) For the first time in the offline RL setting, we establish that SATAC can produce a policy that outperforms the behavior policy while maintaining the same level of safety, which is critical to designing an algorithm for offline RL. (ii) We demonstrate that the algorithm guarantees policy improvement across a broad range of hyperparameters, indicating its practical robustness. Additionally, we offer a practical version of SATAC and compare it with existing state-of-the-art offline safe-RL algorithms in continuous control environments. SATAC outperforms all baselines across a range of tasks, thus validating the theoretical performance.