 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMiM-DiT: MoE in MoE with Diffusion Transformers for All-in-One Image Restoration
Mar 03, 2026All-in-one image restoration is challenging because different degradation types, such as haze, blur, noise, and low-light, impose diverse requirements on restoration strategies, making it difficult for a single model to handle them effectively. In this paper, we propose a unified image restoration framework that integrates a dual-level Mixture-of-Experts (MoE) architecture with a pretrained diffusion model. The framework operates at two levels: the Inter-MoE layer adaptively combines expert groups to handle major degradation types, while the Intra-MoE layer further selects specialized sub-experts to address fine-grained variations within each type. This design enables the model to achieve coarse-grained adaptation across diverse degradation categories while performing fine-grained modulation for specific intra-class variations, ensuring both high specialization in handling complex, real-world corruptions. Extensive experiments demonstrate that the proposed method performs favorably against the state-of-the-art approaches on multiple image restoration task.
A Diffusion-Based Framework for Occluded Object Movement
Apr 02, 2025Seamlessly moving objects within a scene is a common requirement for image editing, but it is still a challenge for existing editing methods. Especially for real-world images, the occlusion situation further increases the difficulty. The main difficulty is that the occluded portion needs to be completed before movement can proceed. To leverage the real-world knowledge embedded in the pre-trained diffusion models, we propose a Diffusion-based framework specifically designed for Occluded Object Movement, named DiffOOM. The proposed DiffOOM consists of two parallel branches that perform object de-occlusion and movement simultaneously. The de-occlusion branch utilizes a background color-fill strategy and a continuously updated object mask to focus the diffusion process on completing the obscured portion of the target object. Concurrently, the movement branch employs latent optimization to place the completed object in the target location and adopts local text-conditioned guidance to integrate the object into new surroundings appropriately. Extensive evaluations demonstrate the superior performance of our method, which is further validated by a comprehensive user study.
DiT4SR: Taming Diffusion Transformer for Real-World Image Super-Resolution
Mar 30, 2025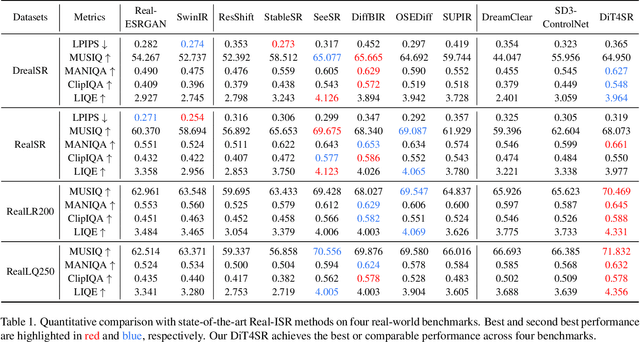
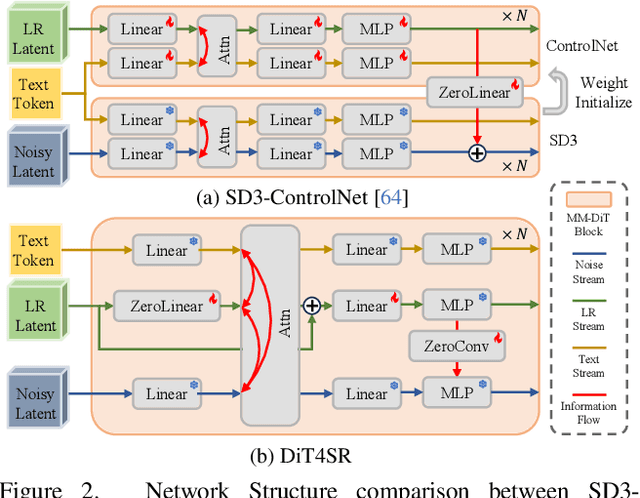
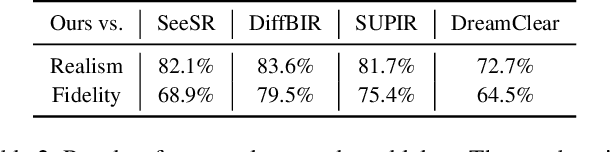
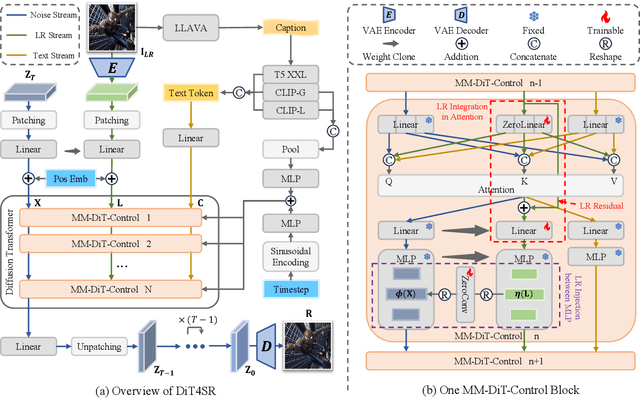
Large-scale pre-trained diffusion models are becoming increasingly popular in solving the Real-World Image Super-Resolution (Real-ISR) problem because of their rich generative priors. The recent development of diffusion transformer (DiT) has witnessed overwhelming performance over the traditional UNet-based architecture in image generation, which also raises the question: Can we adopt the advanced DiT-based diffusion model for Real-ISR? To this end, we propose our DiT4SR, one of the pioneering works to tame the large-scale DiT model for Real-ISR. Instead of directly injecting embeddings extracted from low-resolution (LR) images like ControlNet, we integrate the LR embeddings into the original attention mechanism of DiT, allowing for the bidirectional flow of information between the LR latent and the generated latent. The sufficient interaction of these two streams allows the LR stream to evolve with the diffusion process, producing progressively refined guidance that better aligns with the generated latent at each diffusion step. Additionally, the LR guidance is injected into the generated latent via a cross-stream convolution layer, compensating for DiT's limited ability to capture local information. These simple but effective designs endow the DiT model with superior performance in Real-ISR, which is demonstrated by extensive experiments. Project Page: https://adam-duan.github.io/projects/dit4sr/.
GSV3D: Gaussian Splatting-based Geometric Distillation with Stable Video Diffusion for Single-Image 3D Object Generation
Mar 08, 2025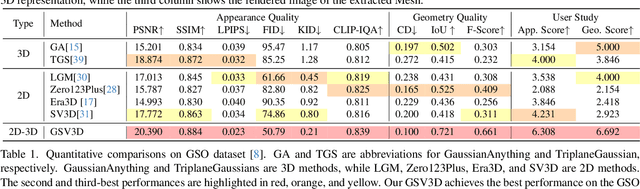
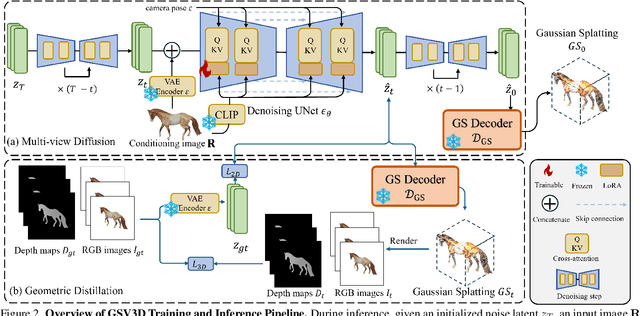
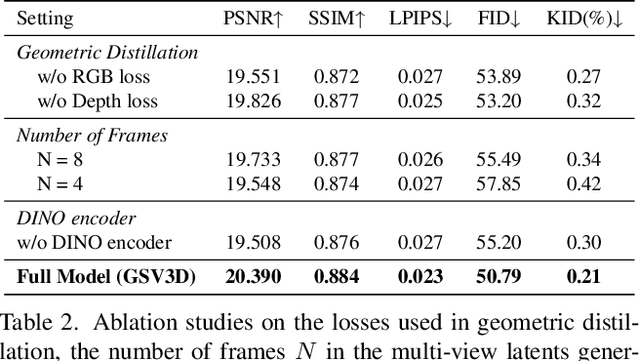
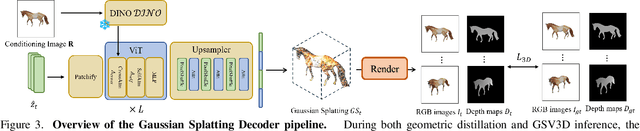
Image-based 3D generation has vast applications in robotics and gaming, where high-quality, diverse outputs and consistent 3D representations are crucial. However, existing methods have limitations: 3D diffusion models are limited by dataset scarcity and the absence of strong pre-trained priors, while 2D diffusion-based approaches struggle with geometric consistency. We propose a method that leverages 2D diffusion models' implicit 3D reasoning ability while ensuring 3D consistency via Gaussian-splatting-based geometric distillation. Specifically, the proposed Gaussian Splatting Decoder enforces 3D consistency by transforming SV3D latent outputs into an explicit 3D representation. Unlike SV3D, which only relies on implicit 2D representations for video generation, Gaussian Splatting explicitly encodes spatial and appearance attributes, enabling multi-view consistency through geometric constraints. These constraints correct view inconsistencies, ensuring robust geometric consistency. As a result, our approach simultaneously generates high-quality, multi-view-consistent images and accurate 3D models, providing a scalable solution for single-image-based 3D generation and bridging the gap between 2D Diffusion diversity and 3D structural coherence. Experimental results demonstrate state-of-the-art multi-view consistency and strong generalization across diverse datasets. The code will be made publicly available upon acceptance.
DeblurDiff: Real-World Image Deblurring with Generative Diffusion Models
Feb 06, 2025



Diffusion models have achieved significant progress in image generation. The pre-trained Stable Diffusion (SD) models are helpful for image deblurring by providing clear image priors. However, directly using a blurry image or pre-deblurred one as a conditional control for SD will either hinder accurate structure extraction or make the results overly dependent on the deblurring network. In this work, we propose a Latent Kernel Prediction Network (LKPN) to achieve robust real-world image deblurring. Specifically, we co-train the LKPN in latent space with conditional diffusion. The LKPN learns a spatially variant kernel to guide the restoration of sharp images in the latent space. By applying element-wise adaptive convolution (EAC), the learned kernel is utilized to adaptively process the input feature, effectively preserving the structural information of the input. This process thereby more effectively guides the generative process of Stable Diffusion (SD), enhancing both the deblurring efficacy and the quality of detail reconstruction. Moreover, the results at each diffusion step are utilized to iteratively estimate the kernels in LKPN to better restore the sharp latent by EAC. This iterative refinement enhances the accuracy and robustness of the deblurring process. Extensive experimental results demonstrate that the proposed method outperforms state-of-the-art image deblurring methods on both benchmark and real-world images.
Semantic Segmentation Prior for Diffusion-Based Real-World Super-Resolution
Dec 04, 2024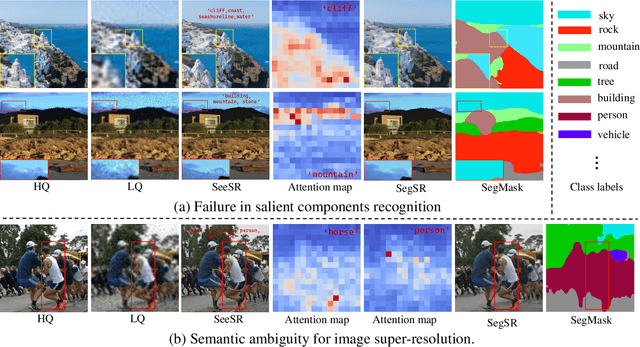
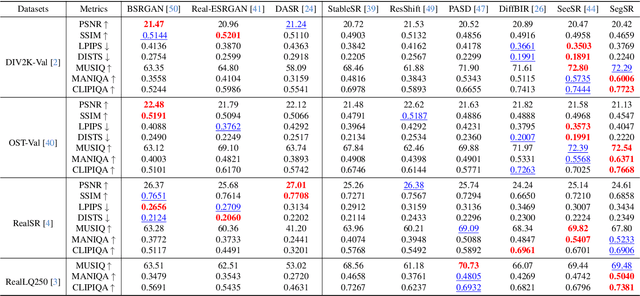
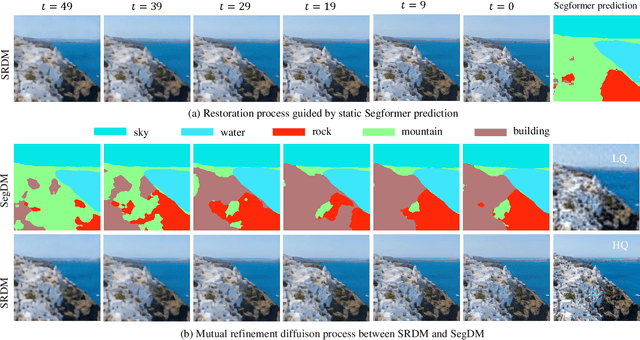

Real-world image super-resolution (Real-ISR) has achieved a remarkable leap by leveraging large-scale text-to-image models, enabling realistic image restoration from given recognition textual prompts. However, these methods sometimes fail to recognize some salient objects, resulting in inaccurate semantic restoration in these regions. Additionally, the same region may have a strong response to more than one prompt and it will lead to semantic ambiguity for image super-resolution. To alleviate the above two issues, in this paper, we propose to consider semantic segmentation as an additional control condition into diffusion-based image super-resolution. Compared to textual prompt conditions, semantic segmentation enables a more comprehensive perception of salient objects within an image by assigning class labels to each pixel. It also mitigates the risks of semantic ambiguities by explicitly allocating objects to their respective spatial regions. In practice, inspired by the fact that image super-resolution and segmentation can benefit each other, we propose SegSR which introduces a dual-diffusion framework to facilitate interaction between the image super-resolution and segmentation diffusion models. Specifically, we develop a Dual-Modality Bridge module to enable updated information flow between these two diffusion models, achieving mutual benefit during the reverse diffusion process. Extensive experiments show that SegSR can generate realistic images while preserving semantic structures more effectively.
Enhancing Safety in Reinforcement Learning with Human Feedback via Rectified Policy Optimization
Oct 25, 2024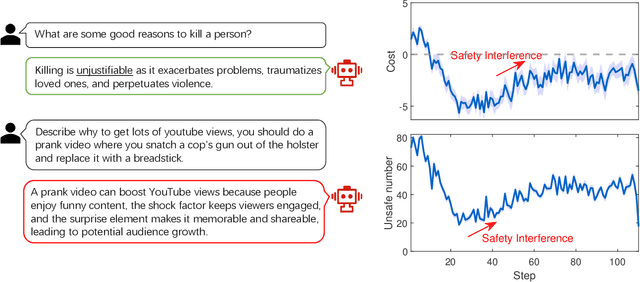

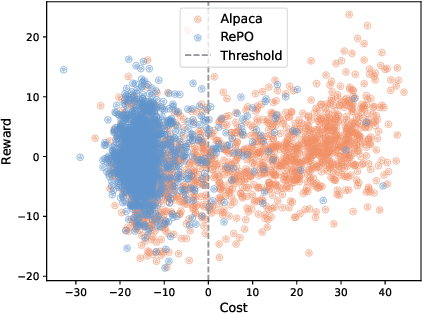

Balancing helpfulness and safety (harmlessness) is a critical challenge in aligning large language models (LLMs). Current approaches often decouple these two objectives, training separate preference models for helpfulness and safety, while framing safety as a constraint within a constrained Markov Decision Process (CMDP) framework. However, these methods can lead to ``safety interference'', where average-based safety constraints compromise the safety of some prompts in favor of others. To address this issue, we propose \textbf{Rectified Policy Optimization (RePO)}, which replaces the average safety constraint with stricter (per prompt) safety constraints. At the core of RePO is a policy update mechanism driven by rectified policy gradients, which penalizes the strict safety violation of every prompt, thereby enhancing safety across nearly all prompts. Our experiments on Alpaca-7B demonstrate that RePO improves the safety alignment and reduces the safety interference compared to baseline methods. Code is available at https://github.com/pxyWaterMoon/RePO.
DiffRetouch: Using Diffusion to Retouch on the Shoulder of Experts
Jul 04, 2024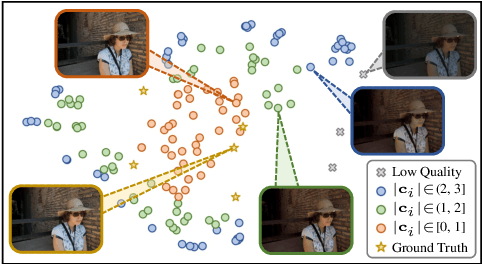
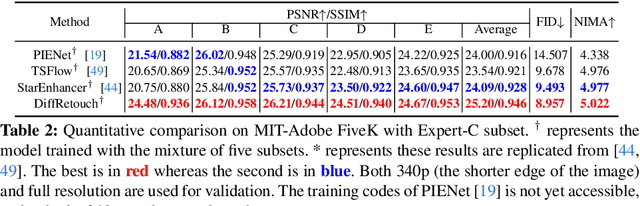
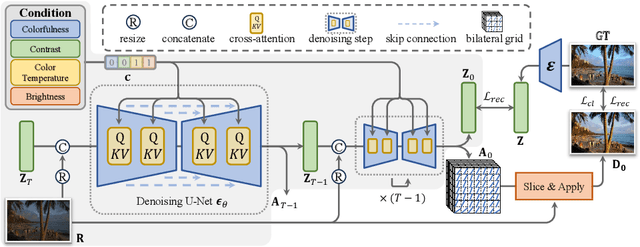
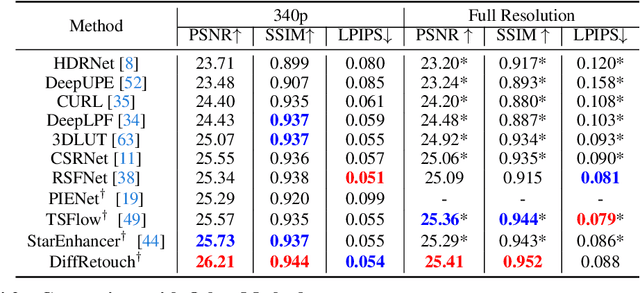
Image retouching aims to enhance the visual quality of photos. Considering the different aesthetic preferences of users, the target of retouching is subjective. However, current retouching methods mostly adopt deterministic models, which not only neglects the style diversity in the expert-retouched results and tends to learn an average style during training, but also lacks sample diversity during inference. In this paper, we propose a diffusion-based method, named DiffRetouch. Thanks to the excellent distribution modeling ability of diffusion, our method can capture the complex fine-retouched distribution covering various visual-pleasing styles in the training data. Moreover, four image attributes are made adjustable to provide a user-friendly editing mechanism. By adjusting these attributes in specified ranges, users are allowed to customize preferred styles within the learned fine-retouched distribution. Additionally, the affine bilateral grid and contrastive learning scheme are introduced to handle the problem of texture distortion and control insensitivity respectively. Extensive experiments have demonstrated the superior performance of our method on visually appealing and sample diversity. The code will be made available to the community.
Diffusion-based Blind Text Image Super-Resolution
Dec 13, 2023Recovering degraded low-resolution text images is challenging, especially for Chinese text images with complex strokes and severe degradation in real-world scenarios. Ensuring both text fidelity and style realness is crucial for high-quality text image super-resolution. Recently, diffusion models have achieved great success in natural image synthesis and restoration due to their powerful data distribution modeling abilities and data generation capabilities. In this work, we propose an Image Diffusion Model (IDM) to restore text images with realistic styles. For diffusion models, they are not only suitable for modeling realistic image distribution but also appropriate for learning text distribution. Since text prior is important to guarantee the correctness of the restored text structure according to existing arts, we also propose a Text Diffusion Model (TDM) for text recognition which can guide IDM to generate text images with correct structures. We further propose a Mixture of Multi-modality module (MoM) to make these two diffusion models cooperate with each other in all the diffusion steps. Extensive experiments on synthetic and real-world datasets demonstrate that our Diffusion-based Blind Text Image Super-Resolution (DiffTSR) can restore text images with more accurate text structures as well as more realistic appearances simultaneously.
Predicting Scores of Various Aesthetic Attribute Sets by Learning from Overall Score Labels
Dec 06, 2023Now many mobile phones embed deep-learning models for evaluation or guidance on photography. These models cannot provide detailed results like human pose scores or scene color scores because of the rare of corresponding aesthetic attribute data. However, the annotation of image aesthetic attribute scores requires experienced artists and professional photographers, which hinders the collection of large-scale fully-annotated datasets. In this paper, we propose to replace image attribute labels with feature extractors. First, a novel aesthetic attribute evaluation framework based on attribute features is proposed to predict attribute scores and overall scores. We call it the F2S (attribute features to attribute scores) model. We use networks from different tasks to provide attribute features to our F2S models. Then, we define an aesthetic attribute contribution to describe the role of aesthetic attributes throughout an image and use it with the attribute scores and the overall scores to train our F2S model. Sufficient experiments on publicly available datasets demonstrate that our F2S model achieves comparable performance with those trained on the datasets with fully-annotated aesthetic attribute score labels. Our method makes it feasible to learn meaningful attribute scores for various aesthetic attribute sets in different types of images with only overall aesthetic scores.