 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Safety in Reinforcement Learning with Human Feedback via Rectified Policy Optimization
Paper and Code
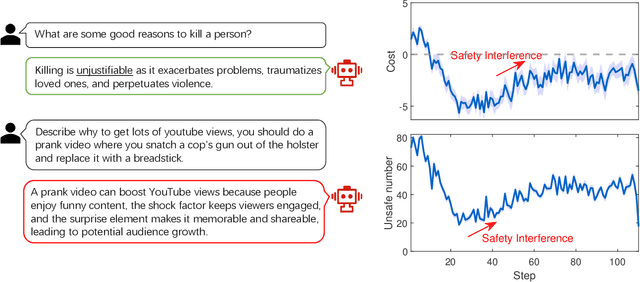

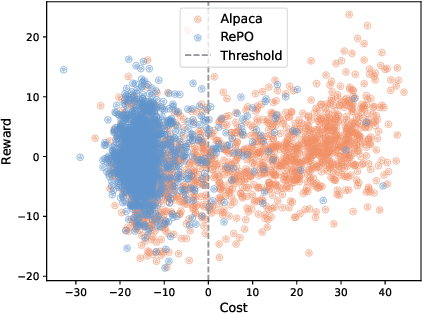

Balancing helpfulness and safety (harmlessness) is a critical challenge in aligning large language models (LLMs). Current approaches often decouple these two objectives, training separate preference models for helpfulness and safety, while framing safety as a constraint within a constrained Markov Decision Process (CMDP) framework. However, these methods can lead to ``safety interference'', where average-based safety constraints compromise the safety of some prompts in favor of others. To address this issue, we propose \textbf{Rectified Policy Optimization (RePO)}, which replaces the average safety constraint with stricter (per prompt) safety constraints. At the core of RePO is a policy update mechanism driven by rectified policy gradients, which penalizes the strict safety violation of every prompt, thereby enhancing safety across nearly all prompts. Our experiments on Alpaca-7B demonstrate that RePO improves the safety alignment and reduces the safety interference compared to baseline methods. Code is available at https://github.com/pxyWaterMoon/RePO.