 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Safety in Reinforcement Learning with Human Feedback via Rectified Policy Optimization
Oct 25, 2024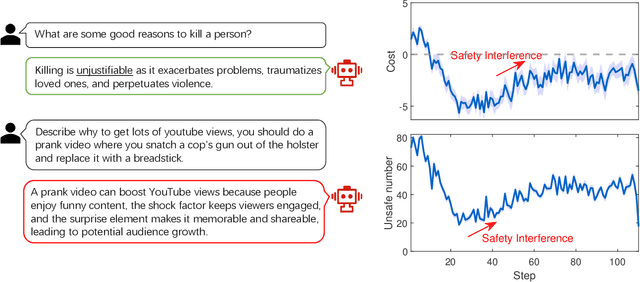

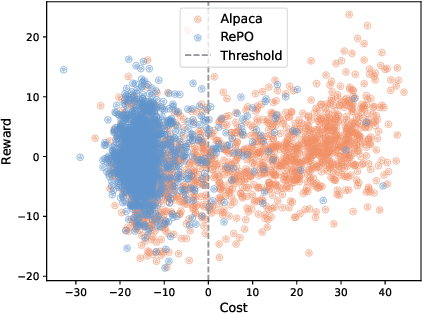

Balancing helpfulness and safety (harmlessness) is a critical challenge in aligning large language models (LLMs). Current approaches often decouple these two objectives, training separate preference models for helpfulness and safety, while framing safety as a constraint within a constrained Markov Decision Process (CMDP) framework. However, these methods can lead to ``safety interference'', where average-based safety constraints compromise the safety of some prompts in favor of others. To address this issue, we propose \textbf{Rectified Policy Optimization (RePO)}, which replaces the average safety constraint with stricter (per prompt) safety constraints. At the core of RePO is a policy update mechanism driven by rectified policy gradients, which penalizes the strict safety violation of every prompt, thereby enhancing safety across nearly all prompts. Our experiments on Alpaca-7B demonstrate that RePO improves the safety alignment and reduces the safety interference compared to baseline methods. Code is available at https://github.com/pxyWaterMoon/RePO.
Learning to Schedule Online Tasks with Bandit Feedback
Feb 26, 2024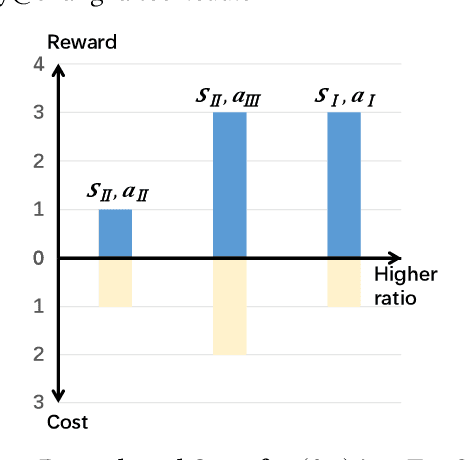

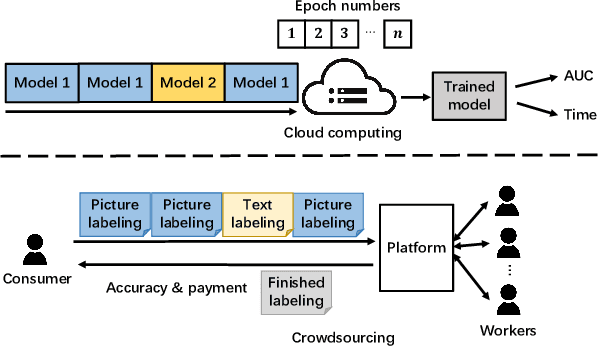
Online task scheduling serves an integral role for task-intensive applications in cloud computing and crowdsourcing. Optimal scheduling can enhance system performance, typically measured by the reward-to-cost ratio, under some task arrival distribution. On one hand, both reward and cost are dependent on task context (e.g., evaluation metric) and remain black-box in practice. These render reward and cost hard to model thus unknown before decision making. On the other hand, task arrival behaviors remain sensitive to factors like unpredictable system fluctuation whereby a prior estimation or the conventional assumption of arrival distribution (e.g., Poisson) may fail. This implies another practical yet often neglected challenge, i.e., uncertain task arrival distribution. Towards effective scheduling under a stationary environment with various uncertainties, we propose a double-optimistic learning based Robbins-Monro (DOL-RM) algorithm. Specifically, DOL-RM integrates a learning module that incorporates optimistic estimation for reward-to-cost ratio and a decision module that utilizes the Robbins-Monro method to implicitly learn task arrival distribution while making scheduling decisions. Theoretically, DOL-RM achieves convergence gap and no regret learning with a sub-linear regret of $O(T^{3/4})$, which is the first result for online task scheduling under uncertain task arrival distribution and unknown reward and cost. Our numerical results in a synthetic experiment and a real-world application demonstrate the effectiveness of DOL-RM in achieving the best cumulative reward-to-cost ratio compared with other state-of-the-art baselines.
Service Chain Composition with Failures in NFV Systems: A Game-Theoretic Perspective
Aug 01, 2020
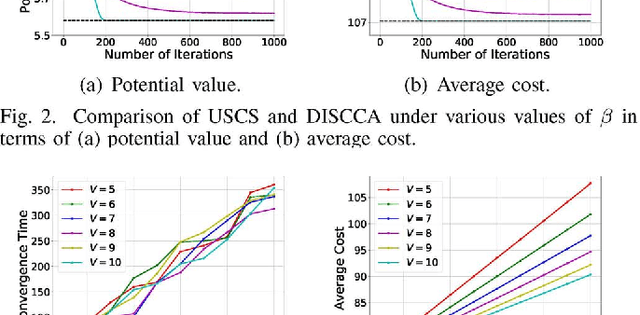

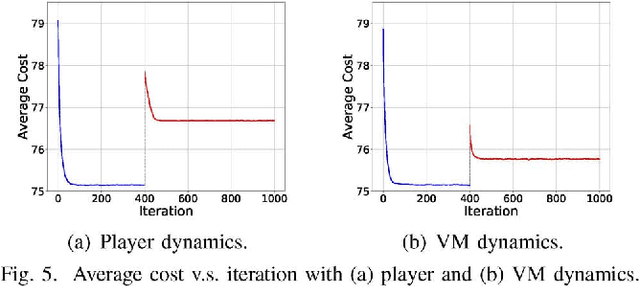
For state-of-the-art network function virtualization (NFV) systems, it remains a key challenge to conduct effective service chain composition for different network services (NSs) with ultra-low request latencies and minimum network congestion. To this end, existing solutions often require full knowledge of the network state, while ignoring the privacy issues and overlooking the non-cooperative behaviors of users. What is more, they may fall short in the face of unexpected failures such as user unavailability and virtual machine breakdown. In this paper, we formulate the problem of service chain composition in NFV systems with failures as a non-cooperative game. By showing that such a game is a weighted potential game and exploiting the unique problem structure, we propose two effective distributed schemes that guide the service chain compositions of different NSs towards the Nash equilibrium (NE) state with both near-optimal latencies and minimum congestion. Besides, we develop two novel learning-aided schemes as comparisons, which are based on deep reinforcement learning (DRL) and Monte Carlo tree search (MCTS) techniques, respectively. Our theoretical analysis and simulation results demonstrate the effectiveness of our proposed schemes, as well as the adaptivity when faced with failures.
Online Task Scheduling for Fog Computing with Multi-Resource Fairness
Aug 01, 2020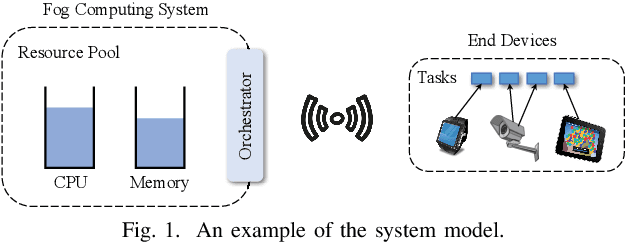
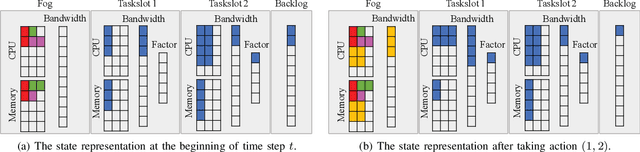
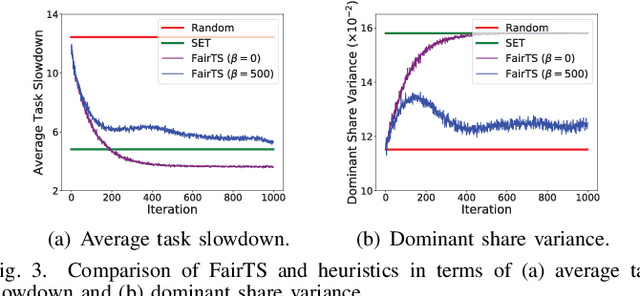
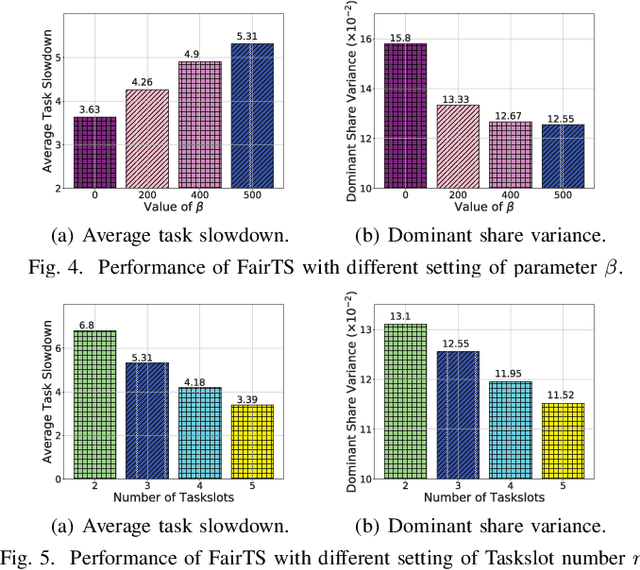
In fog computing systems, one key challenge is online task scheduling, i.e., to decide the resource allocation for tasks that are continuously generated from end devices. The design is challenging because of various uncertainties manifested in fog computing systems; e.g., tasks' resource demands remain unknown before their actual arrivals. Recent works have applied deep reinforcement learning (DRL) techniques to conduct online task scheduling and improve various objectives. However, they overlook the multi-resource fairness for different tasks, which is key to achieving fair resource sharing among tasks but in general non-trivial to achieve. Thusly, it is still an open problem to design an online task scheduling scheme with multi-resource fairness. In this paper, we address the above challenges. Particularly, by leveraging DRL techniques and adopting the idea of dominant resource fairness (DRF), we propose FairTS, an online task scheduling scheme that learns directly from experience to effectively shorten average task slowdown while ensuring multi-resource fairness among tasks. Simulation results show that FairTS outperforms state-of-the-art schemes with an ultra-low task slowdown and better resource fairness.
Green Offloading in Fog-Assisted IoT Systems: An Online Perspective Integrating Learning and Control
Aug 01, 2020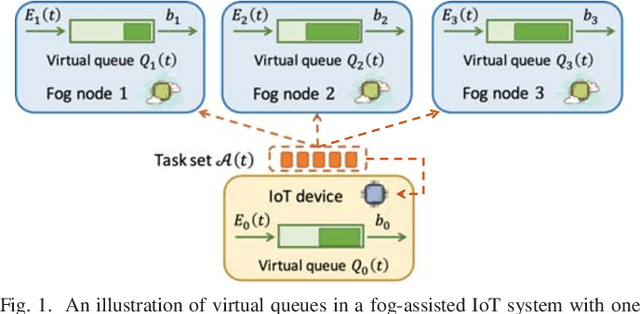
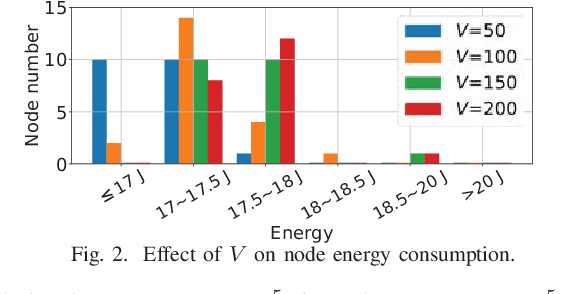
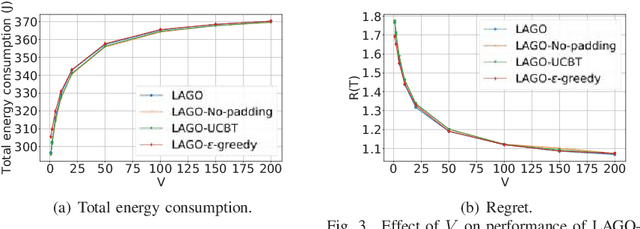
In fog-assisted IoT systems, it is a common practice to offload tasks from IoT devices to their nearby fog nodes to reduce task processing latencies and energy consumptions. However, the design of online energy-efficient scheme is still an open problem because of various uncertainties in system dynamics such as processing capacities and transmission rates. Moreover, the decision-making process is constrained by resource limits on fog nodes and IoT devices, making the design even more complicated. In this paper, we formulate such a task offloading problem with unknown system dynamics as a combinatorial multi-armed bandit (CMAB) problem with long-term constraints on time-averaged energy consumptions. Through an effective integration of online learning and online control, we propose a \textit{Learning-Aided Green Offloading} (LAGO) scheme. In LAGO, we employ bandit learning methods to handle the exploitation-exploration tradeoff and utilize virtual queue techniques to deal with the long-term constraints. Our theoretical analysis shows that LAGO can reduce the average task latency with a tunable sublinear regret bound over a finite time horizon and satisfy the long-term time-averaged energy constraints. We conduct extensive simulations to verify such theoretical results.
Data-Driven Bandit Learning for Proactive Cache Placement in Fog-Assisted IoT Systems
Aug 01, 2020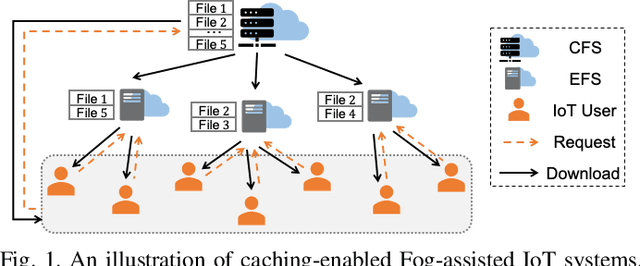
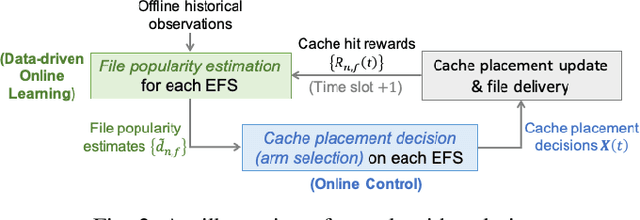

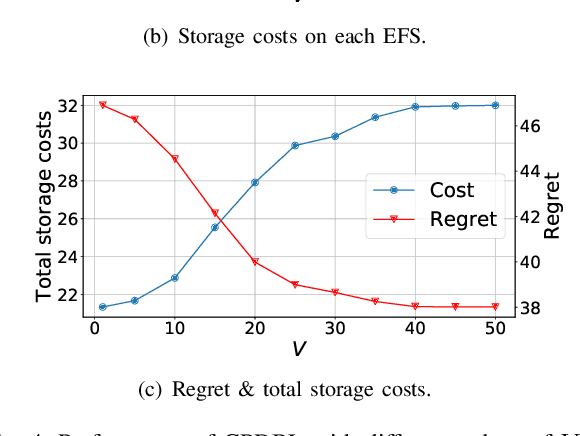
In Fog-assisted IoT systems, it is a common practice to cache popular content at the network edge to achieve high quality of service. Due to uncertainties in practice such as unknown file popularities, cache placement scheme design is still an open problem with unresolved challenges: 1) how to maintain time-averaged storage costs under budgets, 2) how to incorporate online learning to aid cache placement to minimize performance loss (a.k.a. regret), and 3) how to exploit offline history information to further reduce regret. In this paper, we formulate the cache placement problem with unknown file popularities as a constrained combinatorial multi-armed bandit (CMAB) problem. To solve the problem, we employ virtual queue techniques to manage time-averaged constraints, and adopt data-driven bandit learning methods to integrate offline history information into online learning to handle exploration-exploitation tradeoff. With an effective combination of online control and data-driven online learning, we devise a Cache Placement scheme with Data-driven Bandit Learning called CPDBL. Our theoretical analysis and simulations show that CPDBL achieves a sublinear time-averaged regret under long-term storage cost constraints.