 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMiM-DiT: MoE in MoE with Diffusion Transformers for All-in-One Image Restoration
Mar 03, 2026All-in-one image restoration is challenging because different degradation types, such as haze, blur, noise, and low-light, impose diverse requirements on restoration strategies, making it difficult for a single model to handle them effectively. In this paper, we propose a unified image restoration framework that integrates a dual-level Mixture-of-Experts (MoE) architecture with a pretrained diffusion model. The framework operates at two levels: the Inter-MoE layer adaptively combines expert groups to handle major degradation types, while the Intra-MoE layer further selects specialized sub-experts to address fine-grained variations within each type. This design enables the model to achieve coarse-grained adaptation across diverse degradation categories while performing fine-grained modulation for specific intra-class variations, ensuring both high specialization in handling complex, real-world corruptions. Extensive experiments demonstrate that the proposed method performs favorably against the state-of-the-art approaches on multiple image restoration task.
DeblurDiff: Real-World Image Deblurring with Generative Diffusion Models
Feb 06, 2025



Diffusion models have achieved significant progress in image generation. The pre-trained Stable Diffusion (SD) models are helpful for image deblurring by providing clear image priors. However, directly using a blurry image or pre-deblurred one as a conditional control for SD will either hinder accurate structure extraction or make the results overly dependent on the deblurring network. In this work, we propose a Latent Kernel Prediction Network (LKPN) to achieve robust real-world image deblurring. Specifically, we co-train the LKPN in latent space with conditional diffusion. The LKPN learns a spatially variant kernel to guide the restoration of sharp images in the latent space. By applying element-wise adaptive convolution (EAC), the learned kernel is utilized to adaptively process the input feature, effectively preserving the structural information of the input. This process thereby more effectively guides the generative process of Stable Diffusion (SD), enhancing both the deblurring efficacy and the quality of detail reconstruction. Moreover, the results at each diffusion step are utilized to iteratively estimate the kernels in LKPN to better restore the sharp latent by EAC. This iterative refinement enhances the accuracy and robustness of the deblurring process. Extensive experimental results demonstrate that the proposed method outperforms state-of-the-art image deblurring methods on both benchmark and real-world images.
Efficient Visual State Space Model for Image Deblurring
May 23, 2024Convolutional neural networks (CNNs) and Vision Transformers (ViTs) have achieved excellent performance in image restoration. ViTs typically yield superior results in image restoration compared to CNNs due to their ability to capture long-range dependencies and input-dependent characteristics. However, the computational complexity of Transformer-based models grows quadratically with the image resolution, limiting their practical appeal in high-resolution image restoration tasks. In this paper, we propose a simple yet effective visual state space model (EVSSM) for image deblurring, leveraging the benefits of state space models (SSMs) to visual data. In contrast to existing methods that employ several fixed-direction scanning for feature extraction, which significantly increases the computational cost, we develop an efficient visual scan block that applies various geometric transformations before each SSM-based module, capturing useful non-local information and maintaining high efficiency. Extensive experimental results show that the proposed EVSSM performs favorably against state-of-the-art image deblurring methods on benchmark datasets and real-captured images.
Efficient Frequency Domain-based Transformers for High-Quality Image Deblurring
Nov 22, 2022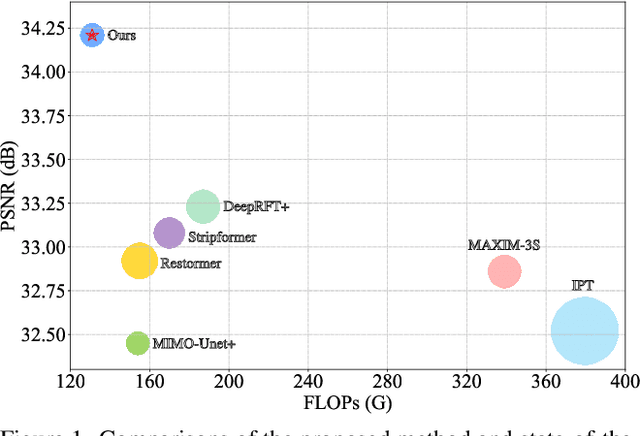
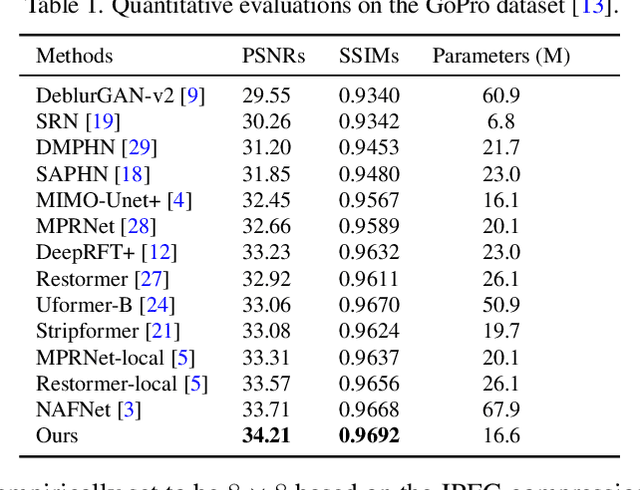
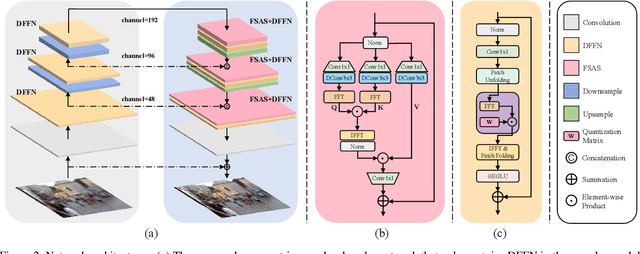
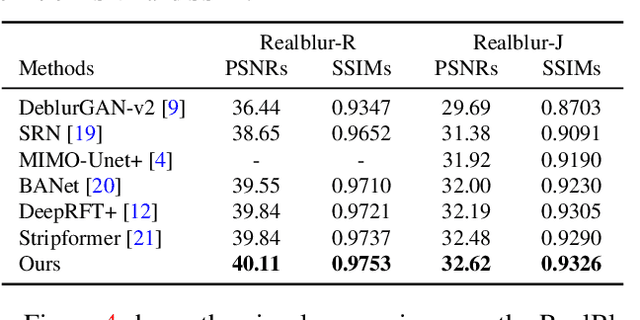
We present an effective and efficient method that explores the properties of Transformers in the frequency domain for high-quality image deblurring. Our method is motivated by the convolution theorem that the correlation or convolution of two signals in the spatial domain is equivalent to an element-wise product of them in the frequency domain. This inspires us to develop an efficient frequency domain-based self-attention solver (FSAS) to estimate the scaled dot-product attention by an element-wise product operation instead of the matrix multiplication in the spatial domain. In addition, we note that simply using the naive feed-forward network (FFN) in Transformers does not generate good deblurred results. To overcome this problem, we propose a simple yet effective discriminative frequency domain-based FFN (DFFN), where we introduce a gated mechanism in the FFN based on the Joint Photographic Experts Group (JPEG) compression algorithm to discriminatively determine which low- and high-frequency information of the features should be preserved for latent clear image restoration. We formulate the proposed FSAS and DFFN into an asymmetrical network based on an encoder and decoder architecture, where the FSAS is only used in the decoder module for better image deblurring. Experimental results show that the proposed method performs favorably against the state-of-the-art approaches. Code will be available at \url{https://github.com/kkkls/FFTformer}.
Efficient and Accurate Quantized Image Super-Resolution on Mobile NPUs, Mobile AI & AIM 2022 challenge: Report
Nov 07, 2022
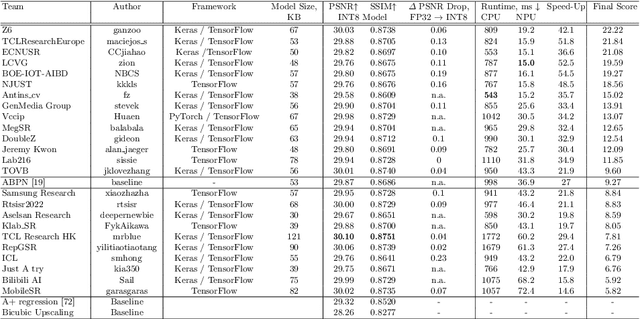
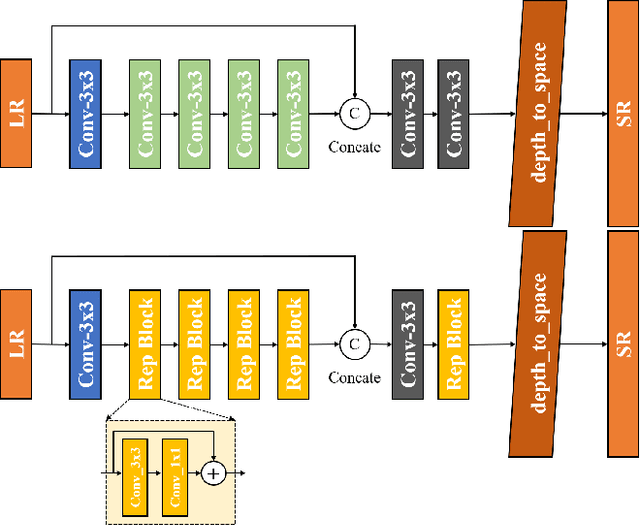
Image super-resolution is a common task on mobile and IoT devices, where one often needs to upscale and enhance low-resolution images and video frames. While numerous solutions have been proposed for this problem in the past, they are usually not compatible with low-power mobile NPUs having many computational and memory constraints. In this Mobile AI challenge, we address this problem and propose the participants to design an efficient quantized image super-resolution solution that can demonstrate a real-time performance on mobile NPUs. The participants were provided with the DIV2K dataset and trained INT8 models to do a high-quality 3X image upscaling. The runtime of all models was evaluated on the Synaptics VS680 Smart Home board with a dedicated edge NPU capable of accelerating quantized neural networks. All proposed solutions are fully compatible with the above NPU, demonstrating an up to 60 FPS rate when reconstructing Full HD resolution images. A detailed description of all models developed in the challenge is provided in this paper.