 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn AI-native experimental laboratory for autonomous biomolecular engineering
Jul 03, 2025



Autonomous scientific research, capable of independently conducting complex experiments and serving non-specialists, represents a long-held aspiration. Achieving it requires a fundamental paradigm shift driven by artificial intelligence (AI). While autonomous experimental systems are emerging, they remain confined to areas featuring singular objectives and well-defined, simple experimental workflows, such as chemical synthesis and catalysis. We present an AI-native autonomous laboratory, targeting highly complex scientific experiments for applications like autonomous biomolecular engineering. This system autonomously manages instrumentation, formulates experiment-specific procedures and optimization heuristics, and concurrently serves multiple user requests. Founded on a co-design philosophy of models, experiments, and instruments, the platform supports the co-evolution of AI models and the automation system. This establishes an end-to-end, multi-user autonomous laboratory that handles complex, multi-objective experiments across diverse instrumentation. Our autonomous laboratory supports fundamental nucleic acid functions-including synthesis, transcription, amplification, and sequencing. It also enables applications in fields such as disease diagnostics, drug development, and information storage. Without human intervention, it autonomously optimizes experimental performance to match state-of-the-art results achieved by human scientists. In multi-user scenarios, the platform significantly improves instrument utilization and experimental efficiency. This platform paves the way for advanced biomaterials research to overcome dependencies on experts and resource barriers, establishing a blueprint for science-as-a-service at scale.
Efficient Core-selecting Incentive Mechanism for Data Sharing in Federated Learning
Sep 26, 2023
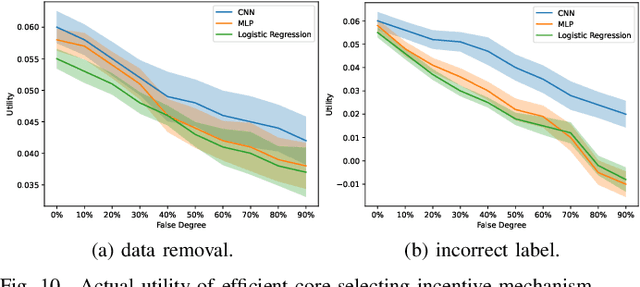
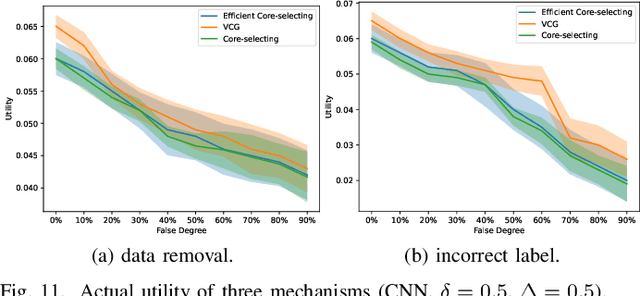
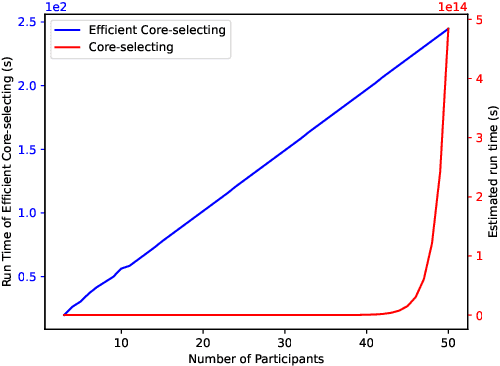
Federated learning is a distributed machine learning system that uses participants' data to train an improved global model. In federated learning, participants cooperatively train a global model, and they will receive the global model and payments. Rational participants try to maximize their individual utility, and they will not input their high-quality data truthfully unless they are provided with satisfactory payments based on their data quality. Furthermore, federated learning benefits from the cooperative contributions of participants. Accordingly, how to establish an incentive mechanism that both incentivizes inputting data truthfully and promotes stable cooperation has become an important issue to consider. In this paper, we introduce a data sharing game model for federated learning and employ game-theoretic approaches to design a core-selecting incentive mechanism by utilizing a popular concept in cooperative games, the core. In federated learning, the core can be empty, resulting in the core-selecting mechanism becoming infeasible. To address this, our core-selecting mechanism employs a relaxation method and simultaneously minimizes the benefits of inputting false data for all participants. However, this mechanism is computationally expensive because it requires aggregating exponential models for all possible coalitions, which is infeasible in federated learning. To address this, we propose an efficient core-selecting mechanism based on sampling approximation that only aggregates models on sampled coalitions to approximate the exact result. Extensive experiments verify that the efficient core-selecting mechanism can incentivize inputting high-quality data and stable cooperation, while it reduces computational overhead compared to the core-selecting mechanism.
Learning A Sparse Transformer Network for Effective Image Deraining
Mar 21, 2023Transformers-based methods have achieved significant performance in image deraining as they can model the non-local information which is vital for high-quality image reconstruction. In this paper, we find that most existing Transformers usually use all similarities of the tokens from the query-key pairs for the feature aggregation. However, if the tokens from the query are different from those of the key, the self-attention values estimated from these tokens also involve in feature aggregation, which accordingly interferes with the clear image restoration. To overcome this problem, we propose an effective DeRaining network, Sparse Transformer (DRSformer) that can adaptively keep the most useful self-attention values for feature aggregation so that the aggregated features better facilitate high-quality image reconstruction. Specifically, we develop a learnable top-k selection operator to adaptively retain the most crucial attention scores from the keys for each query for better feature aggregation. Simultaneously, as the naive feed-forward network in Transformers does not model the multi-scale information that is important for latent clear image restoration, we develop an effective mixed-scale feed-forward network to generate better features for image deraining. To learn an enriched set of hybrid features, which combines local context from CNN operators, we equip our model with mixture of experts feature compensator to present a cooperation refinement deraining scheme. Extensive experimental results on the commonly used benchmarks demonstrate that the proposed method achieves favorable performance against state-of-the-art approaches. The source code and trained models are available at https://github.com/cschenxiang/DRSformer.
* Accepted as a highlight paper in CVPR 2023
Efficient Frequency Domain-based Transformers for High-Quality Image Deblurring
Nov 22, 2022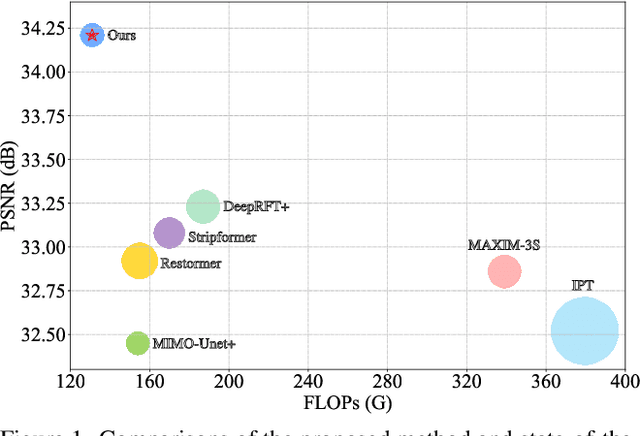
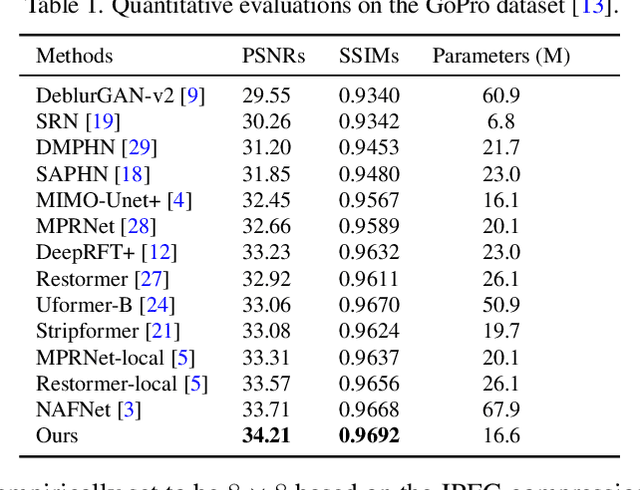
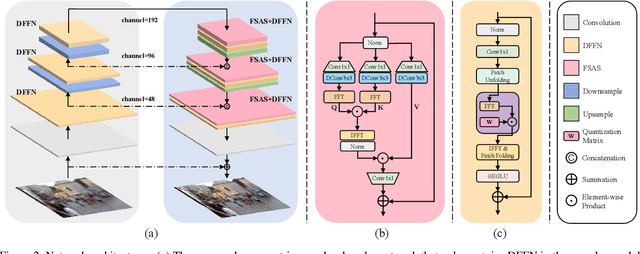
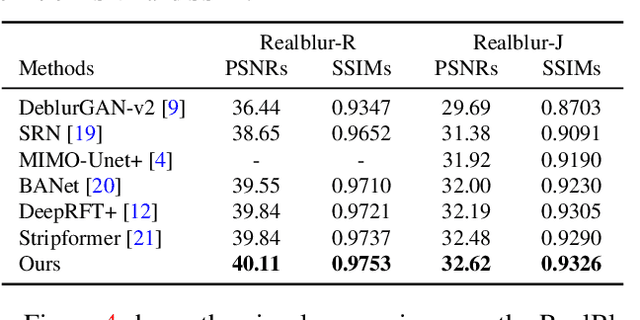
We present an effective and efficient method that explores the properties of Transformers in the frequency domain for high-quality image deblurring. Our method is motivated by the convolution theorem that the correlation or convolution of two signals in the spatial domain is equivalent to an element-wise product of them in the frequency domain. This inspires us to develop an efficient frequency domain-based self-attention solver (FSAS) to estimate the scaled dot-product attention by an element-wise product operation instead of the matrix multiplication in the spatial domain. In addition, we note that simply using the naive feed-forward network (FFN) in Transformers does not generate good deblurred results. To overcome this problem, we propose a simple yet effective discriminative frequency domain-based FFN (DFFN), where we introduce a gated mechanism in the FFN based on the Joint Photographic Experts Group (JPEG) compression algorithm to discriminatively determine which low- and high-frequency information of the features should be preserved for latent clear image restoration. We formulate the proposed FSAS and DFFN into an asymmetrical network based on an encoder and decoder architecture, where the FSAS is only used in the decoder module for better image deblurring. Experimental results show that the proposed method performs favorably against the state-of-the-art approaches. Code will be available at \url{https://github.com/kkkls/FFTformer}.
Blocked and Hierarchical Disentangled Representation From Information Theory Perspective
Jan 21, 2021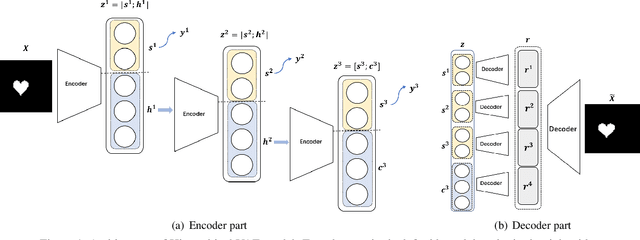

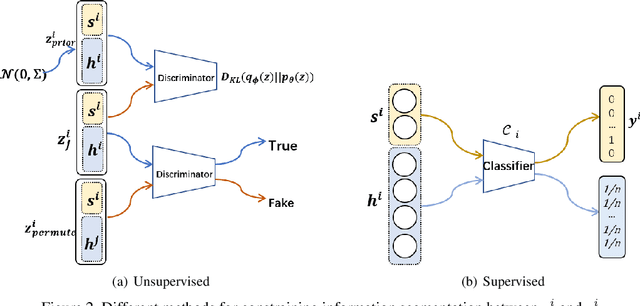
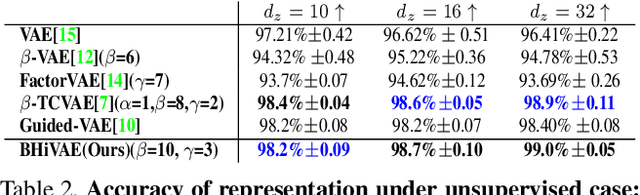
We propose a novel and theoretical model, blocked and hierarchical variational autoencoder (BHiVAE), to get better-disentangled representation. It is well known that information theory has an excellent explanatory meaning for the network, so we start to solve the disentanglement problem from the perspective of information theory. BHiVAE mainly comes from the information bottleneck theory and information maximization principle. Our main idea is that (1) Neurons block not only one neuron node is used to represent attribute, which can contain enough information; (2) Create a hierarchical structure with different attributes on different layers, so that we can segment the information within each layer to ensure that the final representation is disentangled. Furthermore, we present supervised and unsupervised BHiVAE, respectively, where the difference is mainly reflected in the separation of information between different blocks. In supervised BHiVAE, we utilize the label information as the standard to separate blocks. In unsupervised BHiVAE, without extra information, we use the Total Correlation (TC) measure to achieve independence, and we design a new prior distribution of the latent space to guide the representation learning. It also exhibits excellent disentanglement results in experiments and superior classification accuracy in representation learning.