 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBridging Fidelity-Reality with Controllable One-Step Diffusion for Image Super-Resolution
Dec 16, 2025



Recent diffusion-based one-step methods have shown remarkable progress in the field of image super-resolution, yet they remain constrained by three critical limitations: (1) inferior fidelity performance caused by the information loss from compression encoding of low-quality (LQ) inputs; (2) insufficient region-discriminative activation of generative priors; (3) misalignment between text prompts and their corresponding semantic regions. To address these limitations, we propose CODSR, a controllable one-step diffusion network for image super-resolution. First, we propose an LQ-guided feature modulation module that leverages original uncompressed information from LQ inputs to provide high-fidelity conditioning for the diffusion process. We then develop a region-adaptive generative prior activation method to effectively enhance perceptual richness without sacrificing local structural fidelity. Finally, we employ a text-matching guidance strategy to fully harness the conditioning potential of text prompts. Extensive experiments demonstrate that CODSR achieves superior perceptual quality and competitive fidelity compared with state-of-the-art methods with efficient one-step inference.
FoundIR-v2: Optimizing Pre-Training Data Mixtures for Image Restoration Foundation Model
Dec 10, 2025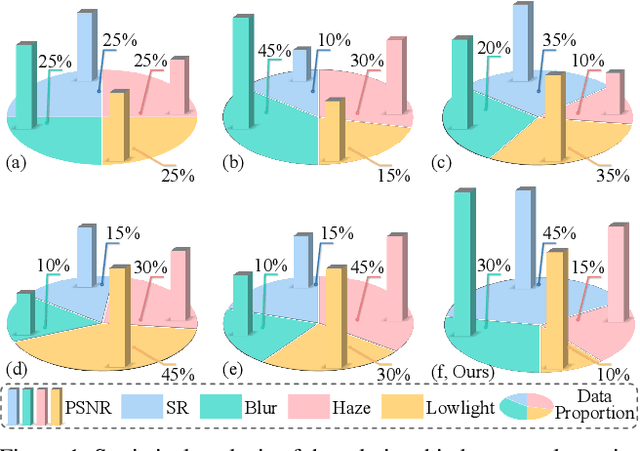
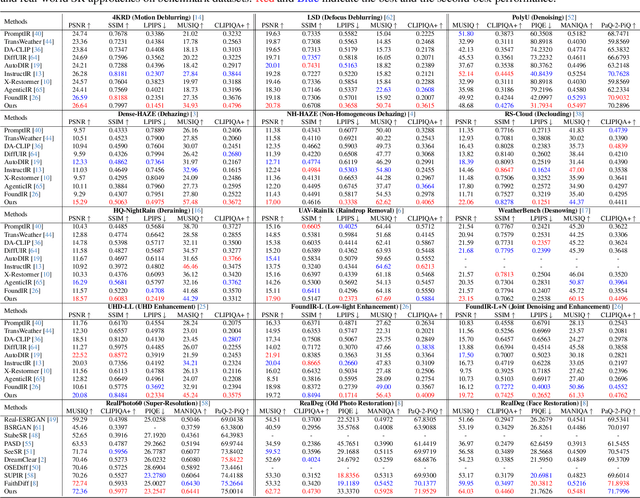
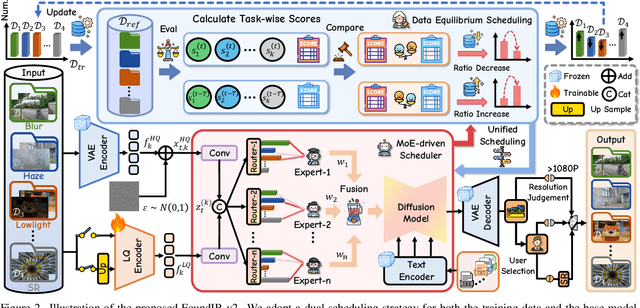
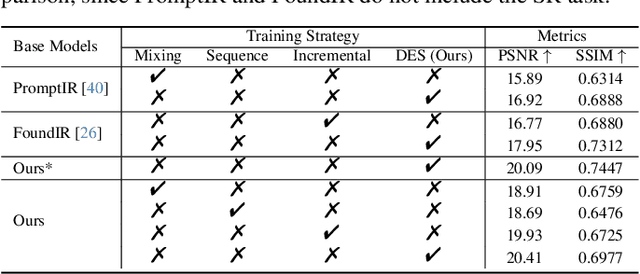
Recent studies have witnessed significant advances in image restoration foundation models driven by improvements in the scale and quality of pre-training data. In this work, we find that the data mixture proportions from different restoration tasks are also a critical factor directly determining the overall performance of all-in-one image restoration models. To this end, we propose a high-capacity diffusion-based image restoration foundation model, FoundIR-v2, which adopts a data equilibrium scheduling paradigm to dynamically optimize the proportions of mixed training datasets from different tasks. By leveraging the data mixing law, our method ensures a balanced dataset composition, enabling the model to achieve consistent generalization and comprehensive performance across diverse tasks. Furthermore, we introduce an effective Mixture-of-Experts (MoE)-driven scheduler into generative pre-training to flexibly allocate task-adaptive diffusion priors for each restoration task, accounting for the distinct degradation forms and levels exhibited by different tasks. Extensive experiments demonstrate that our method can address over 50 sub-tasks across a broader scope of real-world scenarios and achieves favorable performance against state-of-the-art approaches.
Adapting Large VLMs with Iterative and Manual Instructions for Generative Low-light Enhancement
Jul 24, 2025Most existing low-light image enhancement (LLIE) methods rely on pre-trained model priors, low-light inputs, or both, while neglecting the semantic guidance available from normal-light images. This limitation hinders their effectiveness in complex lighting conditions. In this paper, we propose VLM-IMI, a novel framework that leverages large vision-language models (VLMs) with iterative and manual instructions (IMIs) for LLIE. VLM-IMI incorporates textual descriptions of the desired normal-light content as enhancement cues, enabling semantically informed restoration. To effectively integrate cross-modal priors, we introduce an instruction prior fusion module, which dynamically aligns and fuses image and text features, promoting the generation of detailed and semantically coherent outputs. During inference, we adopt an iterative and manual instruction strategy to refine textual instructions, progressively improving visual quality. This refinement enhances structural fidelity, semantic alignment, and the recovery of fine details under extremely low-light conditions. Extensive experiments across diverse scenarios demonstrate that VLM-IMI outperforms state-of-the-art methods in both quantitative metrics and perceptual quality. The source code is available at https://github.com/sunxiaoran01/VLM-IMI.
Learning Deblurring Texture Prior from Unpaired Data with Diffusion Model
Jul 18, 2025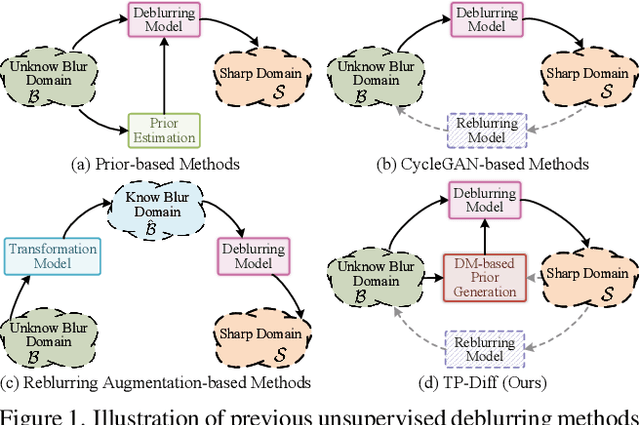
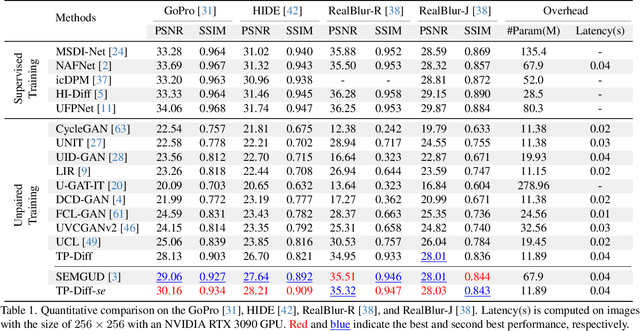
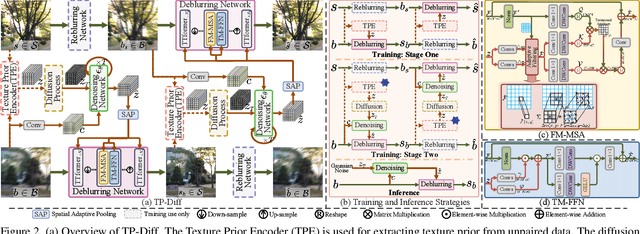
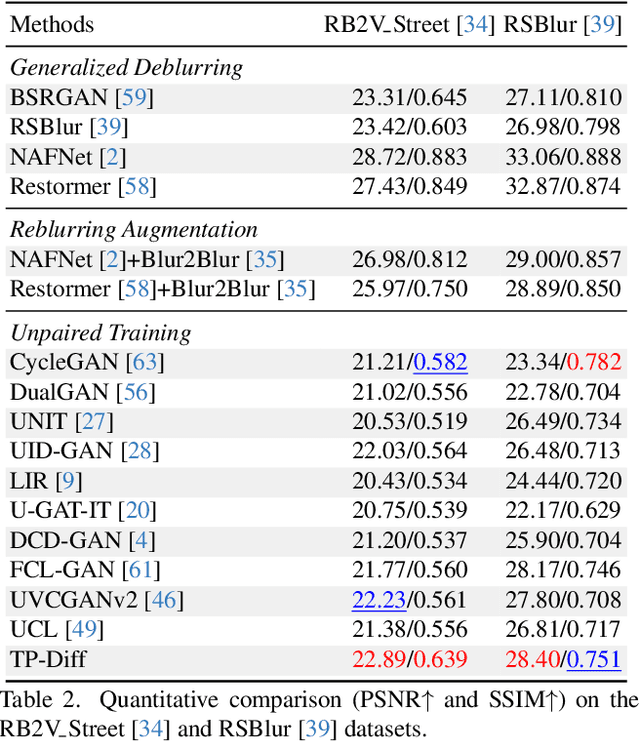
Since acquiring large amounts of realistic blurry-sharp image pairs is difficult and expensive, learning blind image deblurring from unpaired data is a more practical and promising solution. Unfortunately, dominant approaches rely heavily on adversarial learning to bridge the gap from blurry domains to sharp domains, ignoring the complex and unpredictable nature of real-world blur patterns. In this paper, we propose a novel diffusion model (DM)-based framework, dubbed \ours, for image deblurring by learning spatially varying texture prior from unpaired data. In particular, \ours performs DM to generate the prior knowledge that aids in recovering the textures of blurry images. To implement this, we propose a Texture Prior Encoder (TPE) that introduces a memory mechanism to represent the image textures and provides supervision for DM training. To fully exploit the generated texture priors, we present the Texture Transfer Transformer layer (TTformer), in which a novel Filter-Modulated Multi-head Self-Attention (FM-MSA) efficiently removes spatially varying blurring through adaptive filtering. Furthermore, we implement a wavelet-based adversarial loss to preserve high-frequency texture details. Extensive evaluations show that \ours provides a promising unsupervised deblurring solution and outperforms SOTA methods in widely-used benchmarks.
Frequency Domain-Based Diffusion Model for Unpaired Image Dehazing
Jul 02, 2025Unpaired image dehazing has attracted increasing attention due to its flexible data requirements during model training. Dominant methods based on contrastive learning not only introduce haze-unrelated content information, but also ignore haze-specific properties in the frequency domain (\ie,~haze-related degradation is mainly manifested in the amplitude spectrum). To address these issues, we propose a novel frequency domain-based diffusion model, named \ours, for fully exploiting the beneficial knowledge in unpaired clear data. In particular, inspired by the strong generative ability shown by Diffusion Models (DMs), we tackle the dehazing task from the perspective of frequency domain reconstruction and perform the DMs to yield the amplitude spectrum consistent with the distribution of clear images. To implement it, we propose an Amplitude Residual Encoder (ARE) to extract the amplitude residuals, which effectively compensates for the amplitude gap from the hazy to clear domains, as well as provide supervision for the DMs training. In addition, we propose a Phase Correction Module (PCM) to eliminate artifacts by further refining the phase spectrum during dehazing with a simple attention mechanism. Experimental results demonstrate that our \ours outperforms other state-of-the-art methods on both synthetic and real-world datasets.
Mamba-Driven Topology Fusion for Monocular 3-D Human Pose Estimation
May 27, 2025Transformer-based methods for 3-D human pose estimation face significant computational challenges due to the quadratic growth of self-attention mechanism complexity with sequence length. Recently, the Mamba model has substantially reduced computational overhead and demonstrated outstanding performance in modeling long sequences by leveraging state space model (SSM). However, the ability of SSM to process sequential data is not suitable for 3-D joint sequences with topological structures, and the causal convolution structure in Mamba also lacks insight into local joint relationships. To address these issues, we propose the Mamba-Driven Topology Fusion framework in this paper. Specifically, the proposed Bone Aware Module infers the direction and length of bone vectors in the spherical coordinate system, providing effective topological guidance for the Mamba model in processing joint sequences. Furthermore, we enhance the convolutional structure within the Mamba model by integrating forward and backward graph convolutional network, enabling it to better capture local joint dependencies. Finally, we design a Spatiotemporal Refinement Module to model both temporal and spatial relationships within the sequence. Through the incorporation of skeletal topology, our approach effectively alleviates Mamba's limitations in capturing human structural relationships. We conduct extensive experiments on the Human3.6M and MPI-INF-3DHP datasets for testing and comparison, and the results show that the proposed method greatly reduces computational cost while achieving higher accuracy. Ablation studies further demonstrate the effectiveness of each proposed module. The code and models will be released.
UltraVSR: Achieving Ultra-Realistic Video Super-Resolution with Efficient One-Step Diffusion Space
May 26, 2025Diffusion models have shown great potential in generating realistic image detail. However, adapting these models to video super-resolution (VSR) remains challenging due to their inherent stochasticity and lack of temporal modeling. In this paper, we propose UltraVSR, a novel framework that enables ultra-realistic and temporal-coherent VSR through an efficient one-step diffusion space. A central component of UltraVSR is the Degradation-aware Restoration Schedule (DRS), which estimates a degradation factor from the low-resolution input and transforms iterative denoising process into a single-step reconstruction from from low-resolution to high-resolution videos. This design eliminates randomness from diffusion noise and significantly speeds up inference. To ensure temporal consistency, we propose a lightweight yet effective Recurrent Temporal Shift (RTS) module, composed of an RTS-convolution unit and an RTS-attention unit. By partially shifting feature components along the temporal dimension, these two units collaboratively facilitate effective feature propagation, fusion, and alignment across neighboring frames, without relying on explicit temporal layers. The RTS module is integrated into a pretrained text-to-image diffusion model and is further enhanced through Spatio-temporal Joint Distillation (SJD), which improves temporal coherence while preserving realistic details. Additionally, we introduce a Temporally Asynchronous Inference (TAI) strategy to capture long-range temporal dependencies under limited memory constraints. Extensive experiments show that UltraVSR achieves state-of-the-art performance, both qualitatively and quantitatively, in a single sampling step.
Deep Learning-Driven Ultra-High-Definition Image Restoration: A Survey
May 22, 2025Ultra-high-definition (UHD) image restoration aims to specifically solve the problem of quality degradation in ultra-high-resolution images. Recent advancements in this field are predominantly driven by deep learning-based innovations, including enhancements in dataset construction, network architecture, sampling strategies, prior knowledge integration, and loss functions. In this paper, we systematically review recent progress in UHD image restoration, covering various aspects ranging from dataset construction to algorithm design. This serves as a valuable resource for understanding state-of-the-art developments in the field. We begin by summarizing degradation models for various image restoration subproblems, such as super-resolution, low-light enhancement, deblurring, dehazing, deraining, and desnowing, and emphasizing the unique challenges of their application to UHD image restoration. We then highlight existing UHD benchmark datasets and organize the literature according to degradation types and dataset construction methods. Following this, we showcase major milestones in deep learning-driven UHD image restoration, reviewing the progression of restoration tasks, technological developments, and evaluations of existing methods. We further propose a classification framework based on network architectures and sampling strategies, helping to clearly organize existing methods. Finally, we share insights into the current research landscape and propose directions for further advancements. A related repository is available at https://github.com/wlydlut/UHD-Image-Restoration-Survey.
NTIRE 2025 Challenge on Day and Night Raindrop Removal for Dual-Focused Images: Methods and Results
Apr 19, 2025



This paper reviews the NTIRE 2025 Challenge on Day and Night Raindrop Removal for Dual-Focused Images. This challenge received a wide range of impressive solutions, which are developed and evaluated using our collected real-world Raindrop Clarity dataset. Unlike existing deraining datasets, our Raindrop Clarity dataset is more diverse and challenging in degradation types and contents, which includes day raindrop-focused, day background-focused, night raindrop-focused, and night background-focused degradations. This dataset is divided into three subsets for competition: 14,139 images for training, 240 images for validation, and 731 images for testing. The primary objective of this challenge is to establish a new and powerful benchmark for the task of removing raindrops under varying lighting and focus conditions. There are a total of 361 participants in the competition, and 32 teams submitting valid solutions and fact sheets for the final testing phase. These submissions achieved state-of-the-art (SOTA) performance on the Raindrop Clarity dataset. The project can be found at https://lixinustc.github.io/CVPR-NTIRE2025-RainDrop-Competition.github.io/.
The Tenth NTIRE 2025 Efficient Super-Resolution Challenge Report
Apr 14, 2025This paper presents a comprehensive review of the NTIRE 2025 Challenge on Single-Image Efficient Super-Resolution (ESR). The challenge aimed to advance the development of deep models that optimize key computational metrics, i.e., runtime, parameters, and FLOPs, while achieving a PSNR of at least 26.90 dB on the $\operatorname{DIV2K\_LSDIR\_valid}$ dataset and 26.99 dB on the $\operatorname{DIV2K\_LSDIR\_test}$ dataset. A robust participation saw \textbf{244} registered entrants, with \textbf{43} teams submitting valid entries. This report meticulously analyzes these methods and results, emphasizing groundbreaking advancements in state-of-the-art single-image ESR techniques. The analysis highlights innovative approaches and establishes benchmarks for future research in the field.