 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLoViF 2026 Challenge on Real-World All-in-One Image Restoration: Methods and Results
Apr 21, 2026This paper presents a review for the LoViF Challenge on Real-World All-in-One Image Restoration. The challenge aimed to advance research on real-world all-in-one image restoration under diverse real-world degradation conditions, including blur, low-light, haze, rain, and snow. It provided a unified benchmark to evaluate the robustness and generalization ability of restoration models across multiple degradation categories within a common framework. The competition attracted 124 registered participants and received 9 valid final submissions with corresponding fact sheets, significantly contributing to the progress of real-world all-in-one image restoration. This report provides a detailed analysis of the submitted methods and corresponding results, emphasizing recent progress in unified real-world image restoration. The analysis highlights effective approaches and establishes a benchmark for future research in real-world low-level vision.
The Fourth Challenge on Image Super-Resolution ($\times$4) at NTIRE 2026: Benchmark Results and Method Overview
Apr 16, 2026This paper presents the NTIRE 2026 image super-resolution ($\times$4) challenge, one of the associated competitions of the NTIRE 2026 Workshop at CVPR 2026. The challenge aims to reconstruct high-resolution (HR) images from low-resolution (LR) inputs generated through bicubic downsampling with a $\times$4 scaling factor. The objective is to develop effective super-resolution solutions and analyze recent advances in the field. To reflect the evolving objectives of image super-resolution, the challenge includes two tracks: (1) a restoration track, which emphasizes pixel-wise fidelity and ranks submissions based on PSNR; and (2) a perceptual track, which focuses on visual realism and evaluates results using a perceptual score. A total of 194 participants registered for the challenge, with 31 teams submitting valid entries. This report summarizes the challenge design, datasets, evaluation protocol, main results, and methods of participating teams. The challenge provides a unified benchmark and offers insights into current progress and future directions in image super-resolution.
NTIRE 2026 The Second Challenge on Day and Night Raindrop Removal for Dual-Focused Images: Methods and Results
Apr 12, 2026This paper presents an overview of the NTIRE 2026 Second Challenge on Day and Night Raindrop Removal for Dual-Focused Images. Building upon the success of the first edition, this challenge attracted a wide range of impressive solutions, all developed and evaluated on our real-world Raindrop Clarity dataset~\cite{jin2024raindrop}. For this edition, we adjust the dataset with 14,139 images for training, 407 images for validation, and 593 images for testing. The primary goal of this challenge is to establish a strong and practical benchmark for the removal of raindrops under various illumination and focus conditions. In total, 168 teams have registered for the competition, and 17 teams submitted valid final solutions and fact sheets for the testing phase. The submitted methods achieved strong performance on the Raindrop Clarity dataset, demonstrating the growing progress in this challenging task.
NTIRE 2026 Challenge on Short-form UGC Video Restoration in the Wild with Generative Models: Datasets, Methods and Results
Apr 12, 2026This paper presents an overview of the NTIRE 2026 Challenge on Short-form UGC Video Restoration in the Wild with Generative Models. This challenge utilizes a new short-form UGC (S-UGC) video restoration benchmark, termed KwaiVIR, which is contributed by USTC and Kuaishou Technology. It contains both synthetically distorted videos and real-world short-form UGC videos in the wild. For this edition, the released data include 200 synthetic training videos, 48 wild training videos, 11 validation videos, and 20 testing videos. The primary goal of this challenge is to establish a strong and practical benchmark for restoring short-form UGC videos under complex real-world degradations, especially in the emerging paradigm of generative-model-based S-UGC video restoration. This challenge has two tracks: (i) the primary track is a subjective track, where the evaluation is based on a user study; (ii) the second track is an objective track. These two tracks enable a comprehensive assessment of restoration quality. In total, 95 teams have registered for this competition. And 12 teams submitted valid final solutions and fact sheets for the testing phase. The submitted methods achieved strong performance on the KwaiVIR benchmark, demonstrating encouraging progress in short-form UGC video restoration in the wild.
UniRain: Unified Image Deraining with RAG-based Dataset Distillation and Multi-objective Reweighted Optimization
Mar 04, 2026Despite significant progress has been made in image deraining, we note that most existing methods are often developed for only specific types of rain degradation and fail to generalize across diverse real-world rainy scenes. How to effectively model different rain degradations within a universal framework is important for real-world image deraining. In this paper, we propose UniRain, an effective unified image deraining framework capable of restoring images degraded by rain streak and raindrop under both daytime and nighttime conditions. To better enhance unified model generalization, we construct an intelligent retrieval augmented generation (RAG)-based dataset distillation pipeline that selects high-quality training samples from all public deraining datasets for better mixed training. Furthermore, we incorporate a simple yet effective multi-objective reweighted optimization strategy into the asymmetric mixture-of-experts (MoE) architecture to facilitate consistent performance and improve robustness across diverse scenes. Extensive experiments show that our framework performs favorably against the state-of-the-art models on our proposed benchmarks and multiple public datasets.
Bridging Fidelity-Reality with Controllable One-Step Diffusion for Image Super-Resolution
Dec 16, 2025



Recent diffusion-based one-step methods have shown remarkable progress in the field of image super-resolution, yet they remain constrained by three critical limitations: (1) inferior fidelity performance caused by the information loss from compression encoding of low-quality (LQ) inputs; (2) insufficient region-discriminative activation of generative priors; (3) misalignment between text prompts and their corresponding semantic regions. To address these limitations, we propose CODSR, a controllable one-step diffusion network for image super-resolution. First, we propose an LQ-guided feature modulation module that leverages original uncompressed information from LQ inputs to provide high-fidelity conditioning for the diffusion process. We then develop a region-adaptive generative prior activation method to effectively enhance perceptual richness without sacrificing local structural fidelity. Finally, we employ a text-matching guidance strategy to fully harness the conditioning potential of text prompts. Extensive experiments demonstrate that CODSR achieves superior perceptual quality and competitive fidelity compared with state-of-the-art methods with efficient one-step inference.
FoundIR-v2: Optimizing Pre-Training Data Mixtures for Image Restoration Foundation Model
Dec 10, 2025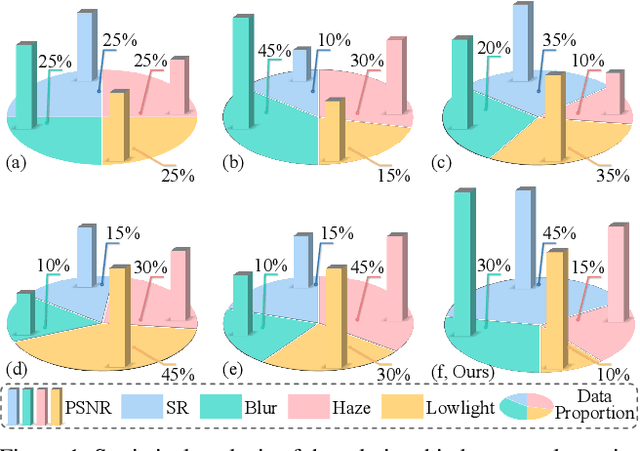
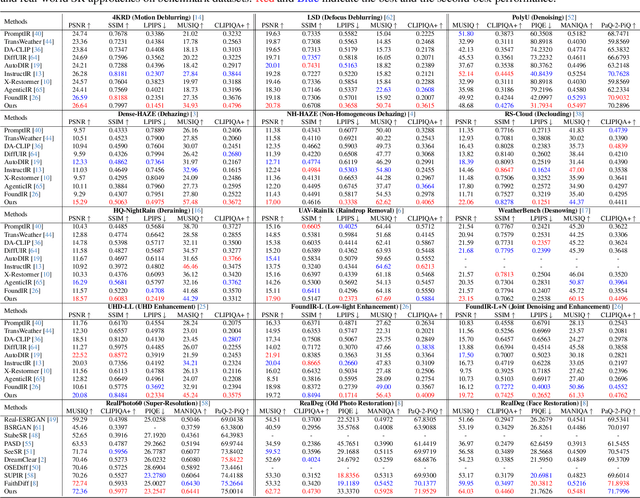
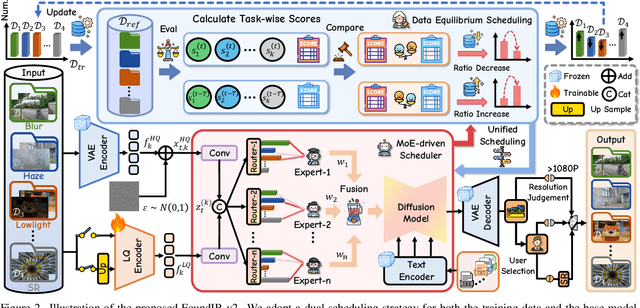
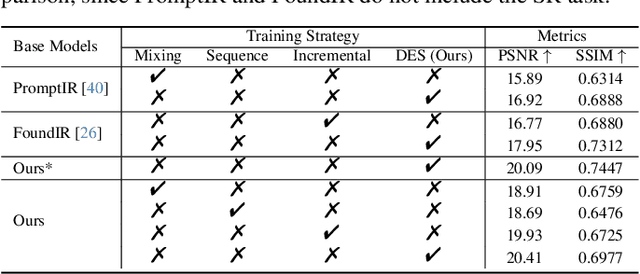
Recent studies have witnessed significant advances in image restoration foundation models driven by improvements in the scale and quality of pre-training data. In this work, we find that the data mixture proportions from different restoration tasks are also a critical factor directly determining the overall performance of all-in-one image restoration models. To this end, we propose a high-capacity diffusion-based image restoration foundation model, FoundIR-v2, which adopts a data equilibrium scheduling paradigm to dynamically optimize the proportions of mixed training datasets from different tasks. By leveraging the data mixing law, our method ensures a balanced dataset composition, enabling the model to achieve consistent generalization and comprehensive performance across diverse tasks. Furthermore, we introduce an effective Mixture-of-Experts (MoE)-driven scheduler into generative pre-training to flexibly allocate task-adaptive diffusion priors for each restoration task, accounting for the distinct degradation forms and levels exhibited by different tasks. Extensive experiments demonstrate that our method can address over 50 sub-tasks across a broader scope of real-world scenarios and achieves favorable performance against state-of-the-art approaches.
Plenodium: UnderWater 3D Scene Reconstruction with Plenoptic Medium Representation
May 27, 2025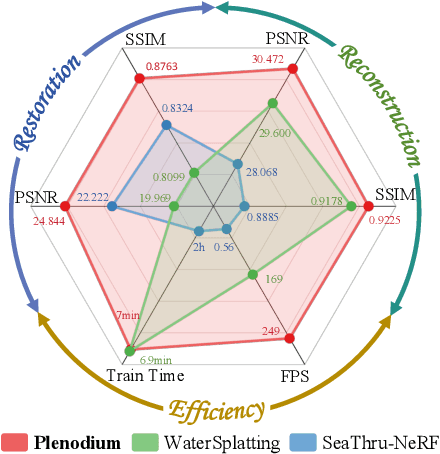
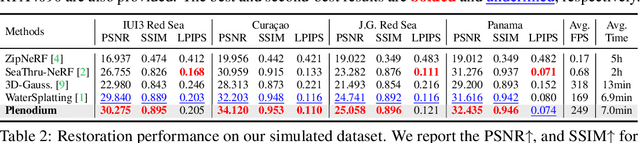
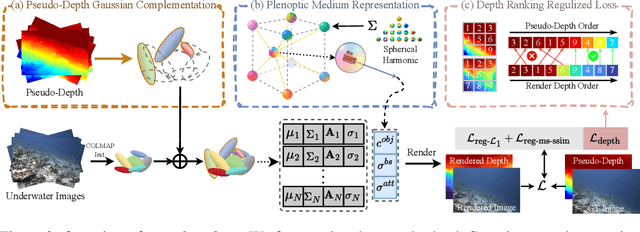
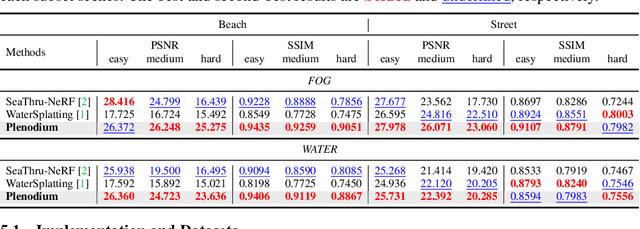
We present Plenodium (plenoptic medium), an effective and efficient 3D representation framework capable of jointly modeling both objects and participating media. In contrast to existing medium representations that rely solely on view-dependent modeling, our novel plenoptic medium representation incorporates both directional and positional information through spherical harmonics encoding, enabling highly accurate underwater scene reconstruction. To address the initialization challenge in degraded underwater environments, we propose the pseudo-depth Gaussian complementation to augment COLMAP-derived point clouds with robust depth priors. In addition, a depth ranking regularized loss is developed to optimize the geometry of the scene and improve the ordinal consistency of the depth maps. Extensive experiments on real-world underwater datasets demonstrate that our method achieves significant improvements in 3D reconstruction. Furthermore, we conduct a simulated dataset with ground truth and the controllable scattering medium to demonstrate the restoration capability of our method in underwater scenarios. Our code and dataset are available at https://plenodium.github.io/.
NTIRE 2025 Challenge on Day and Night Raindrop Removal for Dual-Focused Images: Methods and Results
Apr 19, 2025



This paper reviews the NTIRE 2025 Challenge on Day and Night Raindrop Removal for Dual-Focused Images. This challenge received a wide range of impressive solutions, which are developed and evaluated using our collected real-world Raindrop Clarity dataset. Unlike existing deraining datasets, our Raindrop Clarity dataset is more diverse and challenging in degradation types and contents, which includes day raindrop-focused, day background-focused, night raindrop-focused, and night background-focused degradations. This dataset is divided into three subsets for competition: 14,139 images for training, 240 images for validation, and 731 images for testing. The primary objective of this challenge is to establish a new and powerful benchmark for the task of removing raindrops under varying lighting and focus conditions. There are a total of 361 participants in the competition, and 32 teams submitting valid solutions and fact sheets for the final testing phase. These submissions achieved state-of-the-art (SOTA) performance on the Raindrop Clarity dataset. The project can be found at https://lixinustc.github.io/CVPR-NTIRE2025-RainDrop-Competition.github.io/.
The Tenth NTIRE 2025 Efficient Super-Resolution Challenge Report
Apr 14, 2025This paper presents a comprehensive review of the NTIRE 2025 Challenge on Single-Image Efficient Super-Resolution (ESR). The challenge aimed to advance the development of deep models that optimize key computational metrics, i.e., runtime, parameters, and FLOPs, while achieving a PSNR of at least 26.90 dB on the $\operatorname{DIV2K\_LSDIR\_valid}$ dataset and 26.99 dB on the $\operatorname{DIV2K\_LSDIR\_test}$ dataset. A robust participation saw \textbf{244} registered entrants, with \textbf{43} teams submitting valid entries. This report meticulously analyzes these methods and results, emphasizing groundbreaking advancements in state-of-the-art single-image ESR techniques. The analysis highlights innovative approaches and establishes benchmarks for future research in the field.