 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging Compression to Construct Transferable Bitrate Ladders
Dec 15, 2025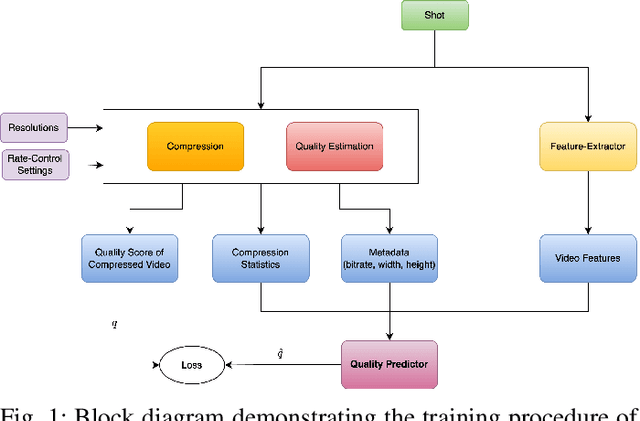


Over the past few years, per-title and per-shot video encoding techniques have demonstrated significant gains as compared to conventional techniques such as constant CRF encoding and the fixed bitrate ladder. These techniques have demonstrated that constructing content-gnostic per-shot bitrate ladders can provide significant bitrate gains and improved Quality of Experience (QoE) for viewers under various network conditions. However, constructing a convex hull for every video incurs a significant computational overhead. Recently, machine learning-based bitrate ladder construction techniques have emerged as a substitute for convex hull construction. These methods operate by extracting features from source videos to train machine learning (ML) models to construct content-adaptive bitrate ladders. Here, we present a new ML-based bitrate ladder construction technique that accurately predicts the VMAF scores of compressed videos, by analyzing the compression procedure and by making perceptually relevant measurements on the source videos prior to compression. We evaluate the performance of our proposed framework against leading prior methods on a large corpus of videos. Since training ML models on every encoder setting is time-consuming, we also investigate how per-shot bitrate ladders perform under different encoding settings. We evaluate the performance of all models against the fixed bitrate ladder and the best possible convex hull constructed using exhaustive encoding with Bjontegaard-delta metrics.
AIM 2024 Challenge on Efficient Video Super-Resolution for AV1 Compressed Content
Sep 25, 2024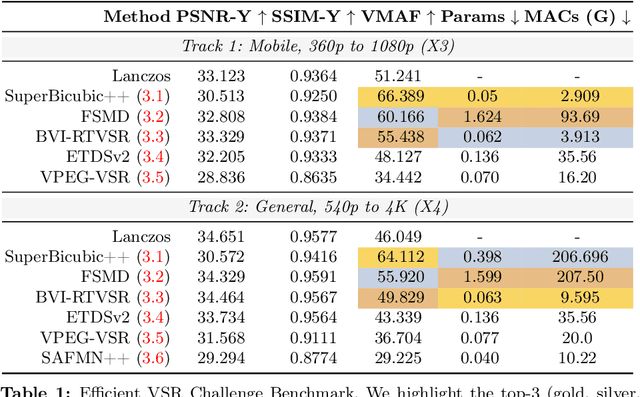

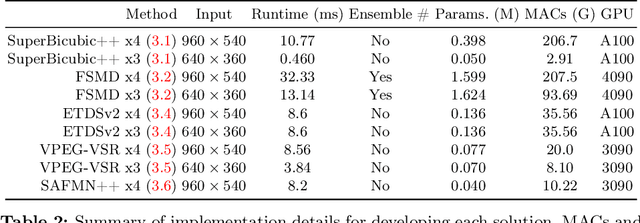

Video super-resolution (VSR) is a critical task for enhancing low-bitrate and low-resolution videos, particularly in streaming applications. While numerous solutions have been developed, they often suffer from high computational demands, resulting in low frame rates (FPS) and poor power efficiency, especially on mobile platforms. In this work, we compile different methods to address these challenges, the solutions are end-to-end real-time video super-resolution frameworks optimized for both high performance and low runtime. We also introduce a new test set of high-quality 4K videos to further validate the approaches. The proposed solutions tackle video up-scaling for two applications: 540p to 4K (x4) as a general case, and 360p to 1080p (x3) more tailored towards mobile devices. In both tracks, the solutions have a reduced number of parameters and operations (MACs), allow high FPS, and improve VMAF and PSNR over interpolation baselines. This report gauges some of the most efficient video super-resolution methods to date.
SVT-AV1 Encoding Bitrate Estimation Using Motion Search Information
Jul 08, 2024


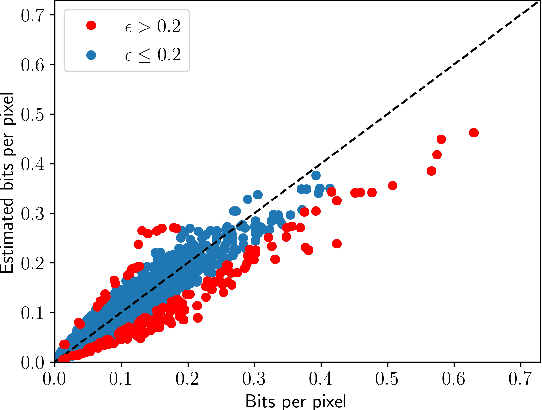
Enabling high compression efficiency while keeping encoding energy consumption at a low level, requires prioritization of which videos need more sophisticated encoding techniques. However, the effects vary highly based on the content, and information on how good a video can be compressed is required. This can be measured by estimating the encoded bitstream size prior to encoding. We identified the errors between estimated motion vectors from Motion Search, an algorithm that predicts temporal changes in videos, correlates well to the encoded bitstream size. Combining Motion Search with Random Forests, the encoding bitrate can be estimated with a Pearson correlation of above 0.96.
Real-Time 4K Super-Resolution of Compressed AVIF Images. AIS 2024 Challenge Survey
Apr 25, 2024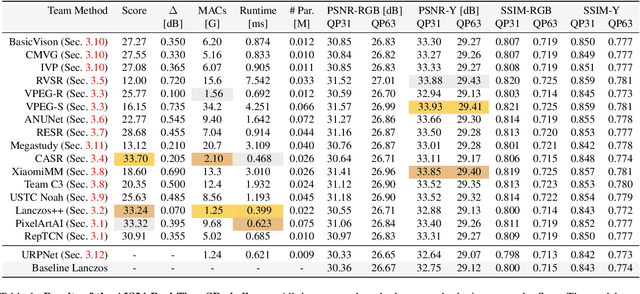
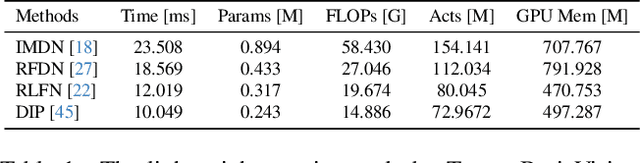
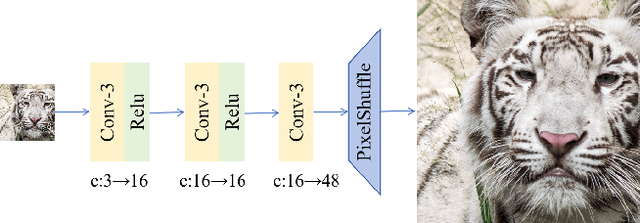
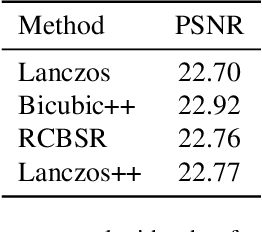
This paper introduces a novel benchmark as part of the AIS 2024 Real-Time Image Super-Resolution (RTSR) Challenge, which aims to upscale compressed images from 540p to 4K resolution (4x factor) in real-time on commercial GPUs. For this, we use a diverse test set containing a variety of 4K images ranging from digital art to gaming and photography. The images are compressed using the modern AVIF codec, instead of JPEG. All the proposed methods improve PSNR fidelity over Lanczos interpolation, and process images under 10ms. Out of the 160 participants, 25 teams submitted their code and models. The solutions present novel designs tailored for memory-efficiency and runtime on edge devices. This survey describes the best solutions for real-time SR of compressed high-resolution images.
Joint Quality Assessment and Example-Guided Image Processing by Disentangling Picture Appearance from Content
Apr 20, 2024
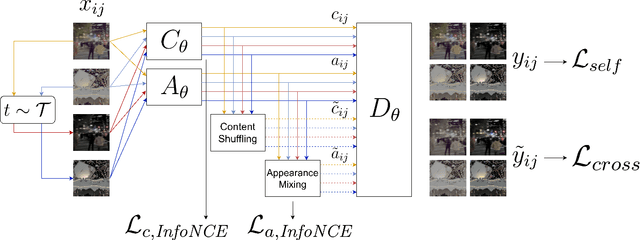
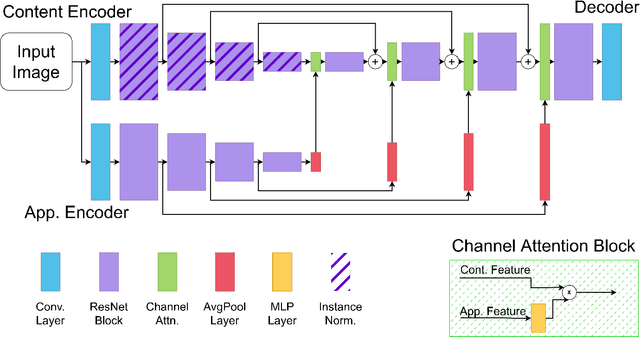

The deep learning revolution has strongly impacted low-level image processing tasks such as style/domain transfer, enhancement/restoration, and visual quality assessments. Despite often being treated separately, the aforementioned tasks share a common theme of understanding, editing, or enhancing the appearance of input images without modifying the underlying content. We leverage this observation to develop a novel disentangled representation learning method that decomposes inputs into content and appearance features. The model is trained in a self-supervised manner and we use the learned features to develop a new quality prediction model named DisQUE. We demonstrate through extensive evaluations that DisQUE achieves state-of-the-art accuracy across quality prediction tasks and distortion types. Moreover, we demonstrate that the same features may also be used for image processing tasks such as HDR tone mapping, where the desired output characteristics may be tuned using example input-output pairs.
Cut-FUNQUE: An Objective Quality Model for Compressed Tone-Mapped High Dynamic Range Videos
Apr 20, 2024



High Dynamic Range (HDR) videos have enjoyed a surge in popularity in recent years due to their ability to represent a wider range of contrast and color than Standard Dynamic Range (SDR) videos. Although HDR video capture has seen increasing popularity because of recent flagship mobile phones such as Apple iPhones, Google Pixels, and Samsung Galaxy phones, a broad swath of consumers still utilize legacy SDR displays that are unable to display HDR videos. As result, HDR videos must be processed, i.e., tone-mapped, before streaming to a large section of SDR-capable video consumers. However, server-side tone-mapping involves automating decisions regarding the choices of tone-mapping operators (TMOs) and their parameters to yield high-fidelity outputs. Moreover, these choices must be balanced against the effects of lossy compression, which is ubiquitous in streaming scenarios. In this work, we develop a novel, efficient model of objective video quality named Cut-FUNQUE that is able to accurately predict the visual quality of tone-mapped and compressed HDR videos. Finally, we evaluate Cut-FUNQUE on a large-scale crowdsourced database of such videos and show that it achieves state-of-the-art accuracy.
Encoding Time and Energy Model for SVT-AV1 based on Video Complexity
Jan 30, 2024The share of online video traffic in global carbon dioxide emissions is growing steadily. To comply with the demand for video media, dedicated compression techniques are continuously optimized, but at the expense of increasingly higher computational demands and thus rising energy consumption at the video encoder side. In order to find the best trade-off between compression and energy consumption, modeling encoding energy for a wide range of encoding parameters is crucial. We propose an encoding time and energy model for SVT-AV1 based on empirical relations between the encoding time and video parameters as well as encoder configurations. Furthermore, we model the influence of video content by established content descriptors such as spatial and temporal information. We then use the predicted encoding time to estimate the required energy demand and achieve a prediction error of 19.6 % for encoding time and 20.9 % for encoding energy.
A FUNQUE Approach to the Quality Assessment of Compressed HDR Videos
Dec 13, 2023


Recent years have seen steady growth in the popularity and availability of High Dynamic Range (HDR) content, particularly videos, streamed over the internet. As a result, assessing the subjective quality of HDR videos, which are generally subjected to compression, is of increasing importance. In particular, we target the task of full-reference quality assessment of compressed HDR videos. The state-of-the-art (SOTA) approach HDRMAX involves augmenting off-the-shelf video quality models, such as VMAF, with features computed on non-linearly transformed video frames. However, HDRMAX increases the computational complexity of models like VMAF. Here, we show that an efficient class of video quality prediction models named FUNQUE+ achieves SOTA accuracy. This shows that the FUNQUE+ models are flexible alternatives to VMAF that achieve higher HDR video quality prediction accuracy at lower computational cost.
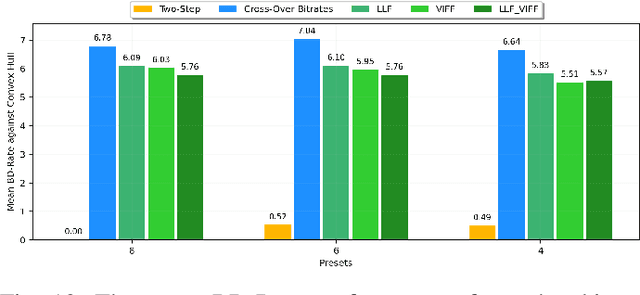
Bitrate Ladder Construction using Visual Information Fidelity
Dec 12, 2023



Recently proposed perceptually optimized per-title video encoding methods provide better BD-rate savings than fixed bitrate-ladder approaches that have been employed in the past. However, a disadvantage of per-title encoding is that it requires significant time and energy to compute bitrate ladders. Over the past few years, a variety of methods have been proposed to construct optimal bitrate ladders including using low-level features to predict cross-over bitrates, optimal resolutions for each bitrate, predicting visual quality, etc. Here, we deploy features drawn from Visual Information Fidelity (VIF) (VIF features) extracted from uncompressed videos to predict the visual quality (VMAF) of compressed videos. We present multiple VIF feature sets extracted from different scales and subbands of a video to tackle the problem of bitrate ladder construction. Comparisons are made against a fixed bitrate ladder and a bitrate ladder obtained from exhaustive encoding using Bjontegaard delta metrics.
Encoder Complexity Control in SVT-AV1 by Speed-Adaptive Preset Switching
Jul 11, 2023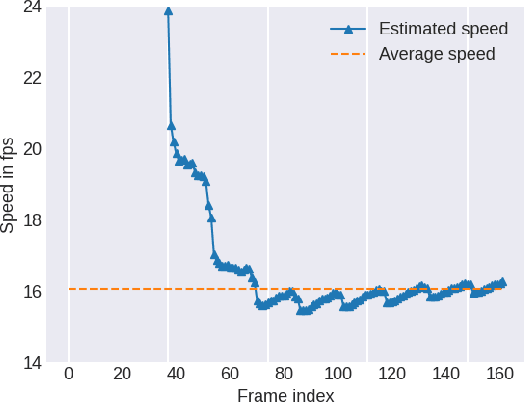


Current developments in video encoding technology lead to continuously improving compression performance but at the expense of increasingly higher computational demands. Regarding the online video traffic increases during the last years and the concomitant need for video encoding, encoder complexity control mechanisms are required to restrict the processing time to a sufficient extent in order to find a reasonable trade-off between performance and complexity. We present a complexity control mechanism in SVT-AV1 by using speed-adaptive preset switching to comply with the remaining time budget. This method enables encoding with a user-defined time constraint within the complete preset range with an average precision of 8.9 \% without introducing any additional latencies.