 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJoint Quality Assessment and Example-Guided Image Processing by Disentangling Picture Appearance from Content
Paper and Code
Apr 20, 2024
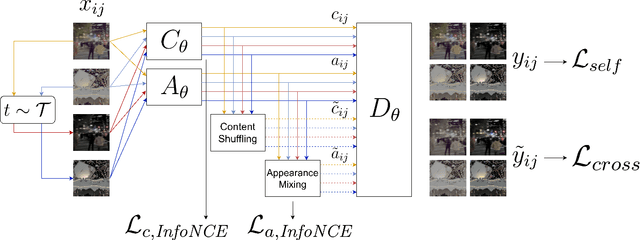
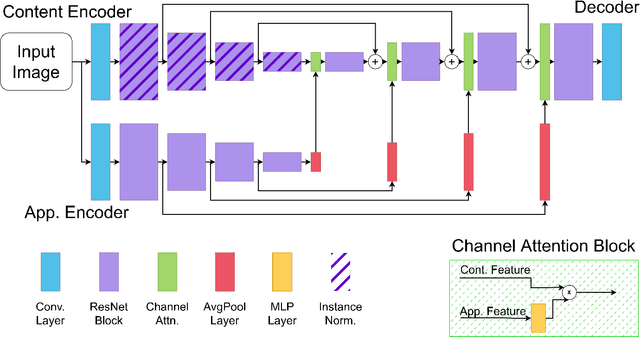

The deep learning revolution has strongly impacted low-level image processing tasks such as style/domain transfer, enhancement/restoration, and visual quality assessments. Despite often being treated separately, the aforementioned tasks share a common theme of understanding, editing, or enhancing the appearance of input images without modifying the underlying content. We leverage this observation to develop a novel disentangled representation learning method that decomposes inputs into content and appearance features. The model is trained in a self-supervised manner and we use the learned features to develop a new quality prediction model named DisQUE. We demonstrate through extensive evaluations that DisQUE achieves state-of-the-art accuracy across quality prediction tasks and distortion types. Moreover, we demonstrate that the same features may also be used for image processing tasks such as HDR tone mapping, where the desired output characteristics may be tuned using example input-output pairs.