 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSubjective Portrait Region Cropping in Landscape Videos with Temporal Annotation Smoothing
Apr 27, 2026With the rise of mobile video consumption on diverse handheld display resolutions and orientation modes, altering videos to aspect ratios poses challenges. Static cropping and border padding often compromises visual quality, while warping may distort a video's intended meaning. Here we advocate for a more effective approach: cropping significant regions within video frames in a temporal manner, while minimizing distortion and preserving essential content. One barrier to solving this problem is the lack of sufficiently large-scale database devoted to informing these tasks. Towards filling this gap, we introduce the LIVE-YouTube Video Cropping (LIVE-YT VC) database, featuring 1800 videos, annotated by 90 human subjects. Using videos sourced from the YouTube-UGC and LSVQ Databases, this new resource is the largest publicly-available subjective video portrait region cropping database. We also introduce a post-processed version of the database, called LIVE-YT VC++, whereby a novel intra-frame temporal filter was deployed to smooth subjective annotations within each video. We demonstrate the usefulness of this new data resource using the SmartVidCrop algorithm and state-of-the-art video grounding models, in hopes of establishing our subjective dataset as a benchmark for future research. Our contributions offer a resource for advancing video aspect ratio transformation models towards ensuring that reshaped mobile-friendly video content retains its quality and meaning. Since our labels bear resemblances to video saliency annotations, we also conducted an additional analysis to explore the similarity between our labels and video saliency predictions. Finally, we repurposed state-of-the-art video grounding models for aspect ratio change tasks, and fine-tuned them on our dataset. As a service to the research community, we plan to open source the project.
LumaFlux: Lifting 8-Bit Worlds to HDR Reality with Physically-Guided Diffusion Transformers
Apr 03, 2026The rapid adoption of HDR-capable devices has created a pressing need to convert the 8-bit Standard Dynamic Range (SDR) content into perceptually and physically accurate 10-bit High Dynamic Range (HDR). Existing inverse tone-mapping (ITM) methods often rely on fixed tone-mapping operators that struggle to generalize to real-world degradations, stylistic variations, and camera pipelines, frequently producing clipped highlights, desaturated colors, or unstable tone reproduction. We introduce LumaFlux, a first physically and perceptually guided diffusion transformer (DiT) for SDR-to-HDR reconstruction by adapting a large pretrained DiT. Our LumaFlux introduces (1) a Physically-Guided Adaptation (PGA) module that injects luminance, spatial descriptors, and frequency cues into attention through low-rank residuals; (2) a Perceptual Cross-Modulation (PCM) layer that stabilizes chroma and texture via FiLM conditioning from vision encoder features; and (3) an HDR Residual Coupler that fuses physical and perceptual signals under a timestep- and layer-adaptive modulation schedule. Finally, a lightweight Rational-Quadratic Spline decoder reconstructs smooth, interpretable tone fields for highlight and exposure expansion, enhancing the output of the VAE decoder to generate HDR. To enable robust HDR learning, we curate the first large-scale SDR-HDR training corpus. For fair and reproducible comparison, we further establish a new evaluation benchmark, comprising HDR references and corresponding expert-graded SDR versions. Across benchmarks, LumaFlux outperforms state-of-the-art baselines, achieving superior luminance reconstruction and perceptual color fidelity with minimal additional parameters.
Seeing Beyond 8bits: Subjective and Objective Quality Assessment of HDR-UGC Videos
Mar 01, 2026High Dynamic Range (HDR) user-generated (UGC) videos are rapidly proliferating across social platforms, yet most perceptual video quality assessment (VQA) systems remain tailored to Standard Dynamic Range (SDR). HDR has a higher bit depth, wide color gamut, and elevated luminance range, exposing distortions such as near-black crushing, highlight clipping, banding, and exposure flicker that amplify UGC artifacts and challenge SDR models. To catalyze progress, we curate Beyond8Bits, a large-scale subjective dataset of 44K videos from 6.5K sources with over 1.5M crowd ratings, spanning diverse scenes, capture conditions, and compression settings. We further introduce HDR-Q, the first Multimodal Large Language Model (MLLM) for HDR-UGC VQA. We propose (i) a novel HDR-aware vision encoder to produce HDR-sensitive embeddings, and (ii) HDR-Aware Policy Optimization (HAPO), an RL finetuning framework that anchors reasoning to HDR cues. HAPO augments GRPO via an HDR-SDR contrastive KL that encourages token reliance on HDR inputs and a Gaussian weighted regression reward for fine-grained MOS calibration. Across Beyond8Bits and public HDR-VQA benchmarks, HDR-Q delivers state-of-the-art performance.
RegionRoute: Regional Style Transfer with Diffusion Model
Feb 22, 2026Precise spatial control in diffusion-based style transfer remains challenging. This challenge arises because diffusion models treat style as a global feature and lack explicit spatial grounding of style representations, making it difficult to restrict style application to specific objects or regions. To our knowledge, existing diffusion models are unable to perform true localized style transfer, typically relying on handcrafted masks or multi-stage post-processing that introduce boundary artifacts and limit generalization. To address this, we propose an attention-supervised diffusion framework that explicitly teaches the model where to apply a given style by aligning the attention scores of style tokens with object masks during training. Two complementary objectives, a Focus loss based on KL divergence and a Cover loss using binary cross-entropy, jointly encourage accurate localization and dense coverage. A modular LoRA-MoE design further enables efficient and scalable multi-style adaptation. To evaluate localized stylization, we introduce the Regional Style Editing Score, which measures Regional Style Matching through CLIP-based similarity within the target region and Identity Preservation via masked LPIPS and pixel-level consistency on unedited areas. Experiments show that our method achieves mask-free, single-object style transfer at inference, producing regionally accurate and visually coherent results that outperform existing diffusion-based editing approaches.
TABES: Trajectory-Aware Backward-on-Entropy Steering for Masked Diffusion Models
Jan 30, 2026Masked Diffusion Models (MDMs) have emerged as a promising non-autoregressive paradigm for generative tasks, offering parallel decoding and bidirectional context utilization. However, current sampling methods rely on simple confidence-based heuristics that ignore the long-term impact of local decisions, leading to trajectory lock-in where early hallucinations cascade into global incoherence. While search-based methods mitigate this, they incur prohibitive computational costs ($O(K)$ forward passes per step). In this work, we propose Backward-on-Entropy (BoE) Steering, a gradient-guided inference framework that approximates infinite-horizon lookahead via a single backward pass. We formally derive the Token Influence Score (TIS) from a first-order expansion of the trajectory cost functional, proving that the gradient of future entropy with respect to input embeddings serves as an optimal control signal for minimizing uncertainty. To ensure scalability, we introduce \texttt{ActiveQueryAttention}, a sparse adjoint primitive that exploits the structure of the masking objective to reduce backward pass complexity. BoE achieves a superior Pareto frontier for inference-time scaling compared to existing unmasking methods, demonstrating that gradient-guided steering offers a mathematically principled and efficient path to robust non-autoregressive generation. We will release the code.
Pro-Pose: Unpaired Full-Body Portrait Synthesis via Canonical UV Maps
Dec 19, 2025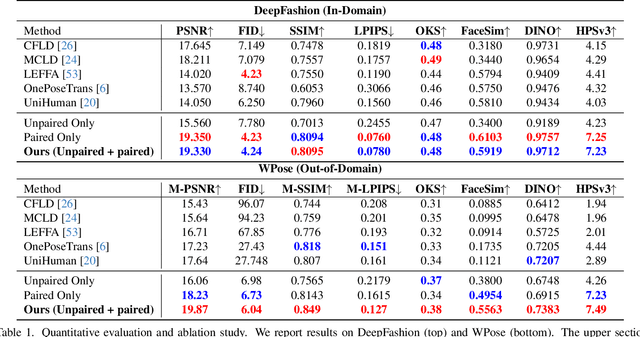
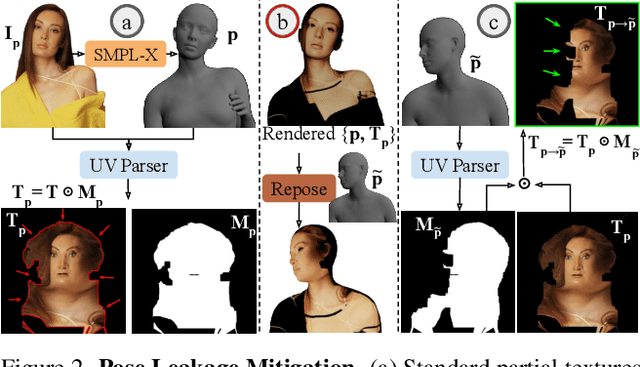
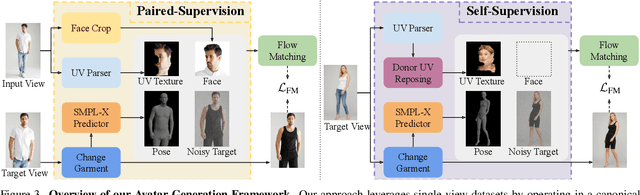

Photographs of people taken by professional photographers typically present the person in beautiful lighting, with an interesting pose, and flattering quality. This is unlike common photos people can take of themselves. In this paper, we explore how to create a ``professional'' version of a person's photograph, i.e., in a chosen pose, in a simple environment, with good lighting, and standard black top/bottom clothing. A key challenge is to preserve the person's unique identity, face and body features while transforming the photo. If there would exist a large paired dataset of the same person photographed both ``in the wild'' and by a professional photographer, the problem would potentially be easier to solve. However, such data does not exist, especially for a large variety of identities. To that end, we propose two key insights: 1) Our method transforms the input photo and person's face to a canonical UV space, which is further coupled with reposing methodology to model occlusions and novel view synthesis. Operating in UV space allows us to leverage existing unpaired datasets. 2) We personalize the output photo via multi image finetuning. Our approach yields high-quality, reposed portraits and achieves strong qualitative and quantitative performance on real-world imagery.
Leveraging Compression to Construct Transferable Bitrate Ladders
Dec 15, 2025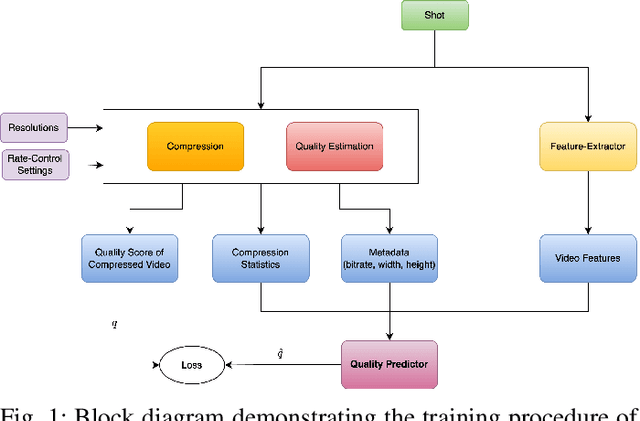
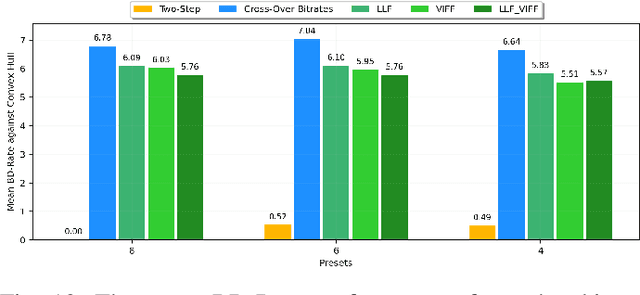


Over the past few years, per-title and per-shot video encoding techniques have demonstrated significant gains as compared to conventional techniques such as constant CRF encoding and the fixed bitrate ladder. These techniques have demonstrated that constructing content-gnostic per-shot bitrate ladders can provide significant bitrate gains and improved Quality of Experience (QoE) for viewers under various network conditions. However, constructing a convex hull for every video incurs a significant computational overhead. Recently, machine learning-based bitrate ladder construction techniques have emerged as a substitute for convex hull construction. These methods operate by extracting features from source videos to train machine learning (ML) models to construct content-adaptive bitrate ladders. Here, we present a new ML-based bitrate ladder construction technique that accurately predicts the VMAF scores of compressed videos, by analyzing the compression procedure and by making perceptually relevant measurements on the source videos prior to compression. We evaluate the performance of our proposed framework against leading prior methods on a large corpus of videos. Since training ML models on every encoder setting is time-consuming, we also investigate how per-shot bitrate ladders perform under different encoding settings. We evaluate the performance of all models against the fixed bitrate ladder and the best possible convex hull constructed using exhaustive encoding with Bjontegaard-delta metrics.
Perceptual Classifiers: Detecting Generative Images using Perceptual Features
Jul 23, 2025Image Quality Assessment (IQA) models are employed in many practical image and video processing pipelines to reduce storage, minimize transmission costs, and improve the Quality of Experience (QoE) of millions of viewers. These models are sensitive to a diverse range of image distortions and can accurately predict image quality as judged by human viewers. Recent advancements in generative models have resulted in a significant influx of "GenAI" content on the internet. Existing methods for detecting GenAI content have progressed significantly with improved generalization performance on images from unseen generative models. Here, we leverage the capabilities of existing IQA models, which effectively capture the manifold of real images within a bandpass statistical space, to distinguish between real and AI-generated images. We investigate the generalization ability of these perceptual classifiers to the task of GenAI image detection and evaluate their robustness against various image degradations. Our results show that a two-layer network trained on the feature space of IQA models demonstrates state-of-the-art performance in detecting fake images across generative models, while maintaining significant robustness against image degradations.
HDRSDR-VQA: A Subjective Video Quality Dataset for HDR and SDR Comparative Evaluation
May 27, 2025We introduce HDRSDR-VQA, a large-scale video quality assessment dataset designed to facilitate comparative analysis between High Dynamic Range (HDR) and Standard Dynamic Range (SDR) content under realistic viewing conditions. The dataset comprises 960 videos generated from 54 diverse source sequences, each presented in both HDR and SDR formats across nine distortion levels. To obtain reliable perceptual quality scores, we conducted a comprehensive subjective study involving 145 participants and six consumer-grade HDR-capable televisions. A total of over 22,000 pairwise comparisons were collected and scaled into Just-Objectionable-Difference (JOD) scores. Unlike prior datasets that focus on a single dynamic range format or use limited evaluation protocols, HDRSDR-VQA enables direct content-level comparison between HDR and SDR versions, supporting detailed investigations into when and why one format is preferred over the other. The open-sourced part of the dataset is publicly available to support further research in video quality assessment, content-adaptive streaming, and perceptual model development.
Video Quality Assessment: A Comprehensive Survey
Dec 04, 2024
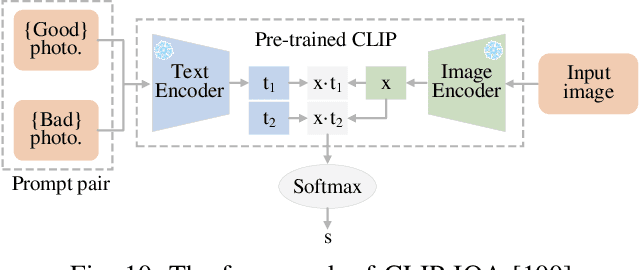
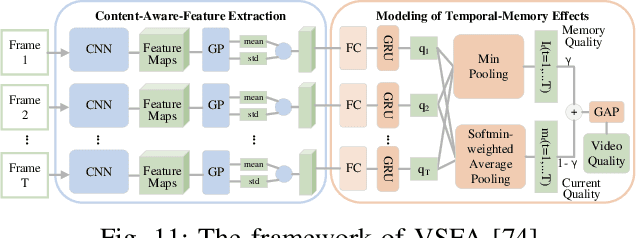
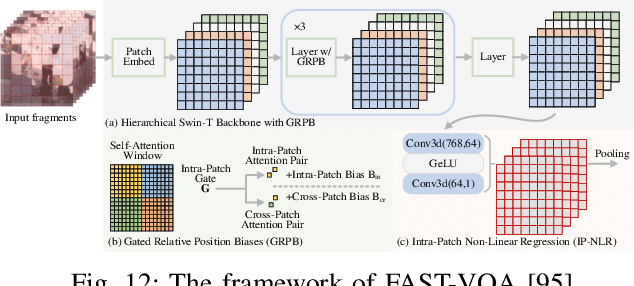
Video quality assessment (VQA) is an important processing task, aiming at predicting the quality of videos in a manner highly consistent with human judgments of perceived quality. Traditional VQA models based on natural image and/or video statistics, which are inspired both by models of projected images of the real world and by dual models of the human visual system, deliver only limited prediction performances on real-world user-generated content (UGC), as exemplified in recent large-scale VQA databases containing large numbers of diverse video contents crawled from the web. Fortunately, recent advances in deep neural networks and Large Multimodality Models (LMMs) have enabled significant progress in solving this problem, yielding better results than prior handcrafted models. Numerous deep learning-based VQA models have been developed, with progress in this direction driven by the creation of content-diverse, large-scale human-labeled databases that supply ground truth psychometric video quality data. Here, we present a comprehensive survey of recent progress in the development of VQA algorithms and the benchmarking studies and databases that make them possible. We also analyze open research directions on study design and VQA algorithm architectures.