 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJoint Quality Assessment and Example-Guided Image Processing by Disentangling Picture Appearance from Content
Apr 20, 2024
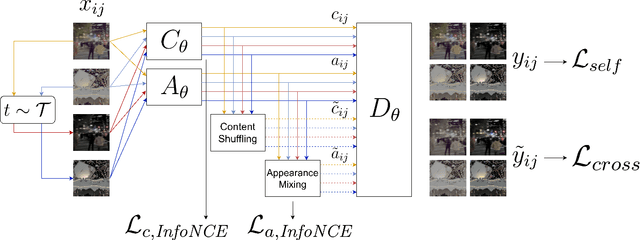
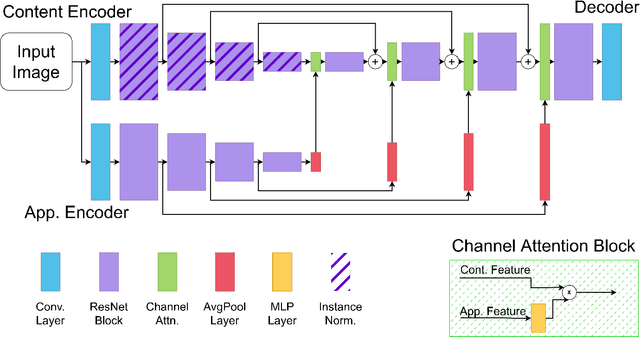

The deep learning revolution has strongly impacted low-level image processing tasks such as style/domain transfer, enhancement/restoration, and visual quality assessments. Despite often being treated separately, the aforementioned tasks share a common theme of understanding, editing, or enhancing the appearance of input images without modifying the underlying content. We leverage this observation to develop a novel disentangled representation learning method that decomposes inputs into content and appearance features. The model is trained in a self-supervised manner and we use the learned features to develop a new quality prediction model named DisQUE. We demonstrate through extensive evaluations that DisQUE achieves state-of-the-art accuracy across quality prediction tasks and distortion types. Moreover, we demonstrate that the same features may also be used for image processing tasks such as HDR tone mapping, where the desired output characteristics may be tuned using example input-output pairs.
Cut-FUNQUE: An Objective Quality Model for Compressed Tone-Mapped High Dynamic Range Videos
Apr 20, 2024



High Dynamic Range (HDR) videos have enjoyed a surge in popularity in recent years due to their ability to represent a wider range of contrast and color than Standard Dynamic Range (SDR) videos. Although HDR video capture has seen increasing popularity because of recent flagship mobile phones such as Apple iPhones, Google Pixels, and Samsung Galaxy phones, a broad swath of consumers still utilize legacy SDR displays that are unable to display HDR videos. As result, HDR videos must be processed, i.e., tone-mapped, before streaming to a large section of SDR-capable video consumers. However, server-side tone-mapping involves automating decisions regarding the choices of tone-mapping operators (TMOs) and their parameters to yield high-fidelity outputs. Moreover, these choices must be balanced against the effects of lossy compression, which is ubiquitous in streaming scenarios. In this work, we develop a novel, efficient model of objective video quality named Cut-FUNQUE that is able to accurately predict the visual quality of tone-mapped and compressed HDR videos. Finally, we evaluate Cut-FUNQUE on a large-scale crowdsourced database of such videos and show that it achieves state-of-the-art accuracy.
Subjective Quality Assessment of Compressed Tone-Mapped High Dynamic Range Videos
Mar 22, 2024



High Dynamic Range (HDR) videos are able to represent wider ranges of contrasts and colors than Standard Dynamic Range (SDR) videos, giving more vivid experiences. Due to this, HDR videos are expected to grow into the dominant video modality of the future. However, HDR videos are incompatible with existing SDR displays, which form the majority of affordable consumer displays on the market. Because of this, HDR videos must be processed by tone-mapping them to reduced bit-depths to service a broad swath of SDR-limited video consumers. Here, we analyze the impact of tone-mapping operators on the visual quality of streaming HDR videos. To this end, we built the first large-scale subjectively annotated open-source database of compressed tone-mapped HDR videos, containing 15,000 tone-mapped sequences derived from 40 unique HDR source contents. The videos in the database were labeled with more than 750,000 subjective quality annotations, collected from more than 1,600 unique human observers. We demonstrate the usefulness of the new subjective database by benchmarking objective models of visual quality on it. We envision that the new LIVE Tone-Mapped HDR (LIVE-TMHDR) database will enable significant progress on HDR video tone mapping and quality assessment in the future. To this end, we make the database freely available to the community at https://live.ece.utexas.edu/research/LIVE_TMHDR/index.html
A FUNQUE Approach to the Quality Assessment of Compressed HDR Videos
Dec 13, 2023


Recent years have seen steady growth in the popularity and availability of High Dynamic Range (HDR) content, particularly videos, streamed over the internet. As a result, assessing the subjective quality of HDR videos, which are generally subjected to compression, is of increasing importance. In particular, we target the task of full-reference quality assessment of compressed HDR videos. The state-of-the-art (SOTA) approach HDRMAX involves augmenting off-the-shelf video quality models, such as VMAF, with features computed on non-linearly transformed video frames. However, HDRMAX increases the computational complexity of models like VMAF. Here, we show that an efficient class of video quality prediction models named FUNQUE+ achieves SOTA accuracy. This shows that the FUNQUE+ models are flexible alternatives to VMAF that achieve higher HDR video quality prediction accuracy at lower computational cost.
Joint Deep Image Restoration and Unsupervised Quality Assessment
Nov 27, 2023Deep learning techniques have revolutionized the fields of image restoration and image quality assessment in recent years. While image restoration methods typically utilize synthetically distorted training data for training, deep quality assessment models often require expensive labeled subjective data. However, recent studies have shown that activations of deep neural networks trained for visual modeling tasks can also be used for perceptual quality assessment of images. Following this intuition, we propose a novel attention-based convolutional neural network capable of simultaneously performing both image restoration and quality assessment. We achieve this by training a JPEG deblocking network augmented with "quality attention" maps and demonstrating state-of-the-art deblocking accuracy, achieving a high correlation of predicted quality with human opinion scores.
Quality Modeling Under A Relaxed Natural Scene Statistics Model
Nov 26, 2023Information-theoretic image quality assessment (IQA) models such as Visual Information Fidelity (VIF) and Spatio-temporal Reduced Reference Entropic Differences (ST-RRED) have enjoyed great success by seamlessly integrating natural scene statistics (NSS) with information theory. The Gaussian Scale Mixture (GSM) model that governs the wavelet subband coefficients of natural images forms the foundation for these algorithms. However, the explosion of user-generated content on social media, which is typically distorted by one or more of many possible unknown impairments, has revealed the limitations of NSS-based IQA models that rely on the simple GSM model. Here, we seek to elaborate the VIF index by deriving useful properties of the Multivariate Generalized Gaussian Distribution (MGGD), and using them to study the behavior of VIF under a Generalized GSM (GGSM) model.
Edge-Aware Image Color Appearance and Difference Modeling
Apr 20, 2023The perception of color is one of the most important aspects of human vision. From an evolutionary perspective, the accurate perception of color is crucial to distinguishing friend from foe, and food from fatal poison. As a result, humans have developed a keen sense of color and are able to detect subtle differences in appearance, while also robustly identifying colors across illumination and viewing conditions. In this paper, we shall briefly review methods for adapting traditional color appearance and difference models to complex image stimuli, and propose mechanisms to improve their performance. In particular, we find that applying contrast sensitivity functions and local adaptation rules in an edge-aware manner improves image difference predictions.
One Transform To Compute Them All: Efficient Fusion-Based Full-Reference Video Quality Assessment
Apr 06, 2023The Visual Multimethod Assessment Fusion (VMAF) algorithm has recently emerged as a state-of-the-art approach to video quality prediction, that now pervades the streaming and social media industry. However, since VMAF requires the evaluation of a heterogeneous set of quality models, it is computationally expensive. Given other advances in hardware-accelerated encoding, quality assessment is emerging as a significant bottleneck in video compression pipelines. Towards alleviating this burden, we propose a novel Fusion of Unified Quality Evaluators (FUNQUE) framework, by enabling computation sharing and by using a transform that is sensitive to visual perception to boost accuracy. Further, we expand the FUNQUE framework to define a collection of improved low-complexity fused-feature models that advance the state-of-the-art of video quality performance with respect to both accuracy and computational efficiency.
FUNQUE: Fusion of Unified Quality Evaluators
Feb 23, 2022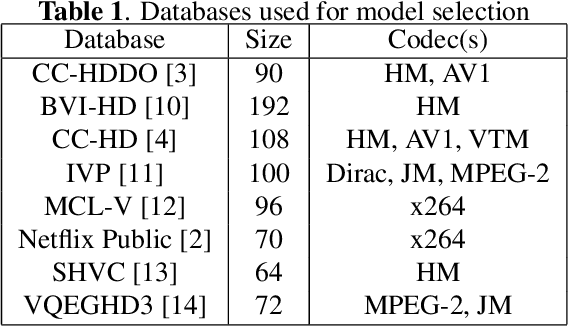
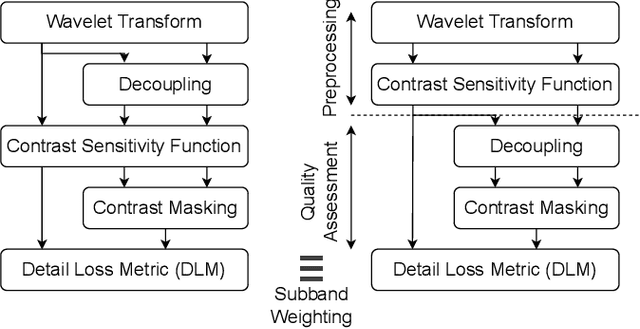
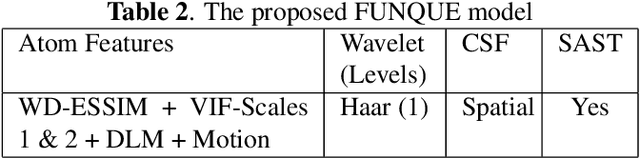
Fusion-based quality assessment has emerged as a powerful method for developing high-performance quality models from quality models that individually achieve lower performances. A prominent example of such an algorithm is VMAF, which has been widely adopted as an industry standard for video quality prediction along with SSIM. In addition to advancing the state-of-the-art, it is imperative to alleviate the computational burden presented by the use of a heterogeneous set of quality models. In this paper, we unify "atom" quality models by computing them on a common transform domain that accounts for the Human Visual System, and we propose FUNQUE, a quality model that fuses unified quality evaluators. We demonstrate that in comparison to the state-of-the-art, FUNQUE offers significant improvements in both correlation against subjective scores and efficiency, due to computation sharing.
A Hitchhiker's Guide to Structural Similarity
Jan 30, 2021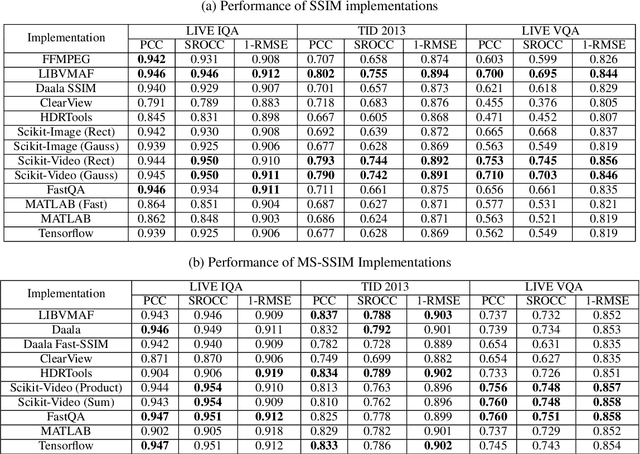

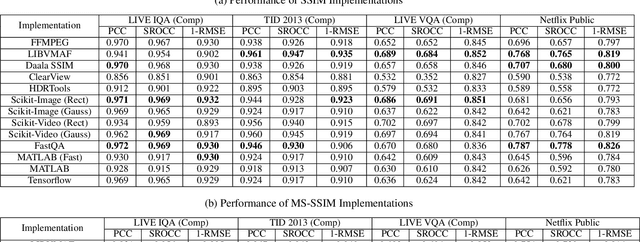
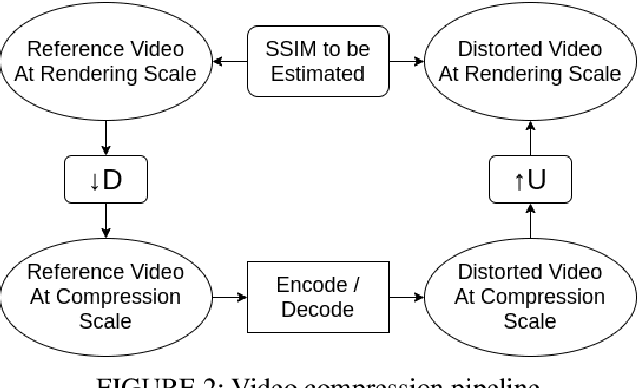
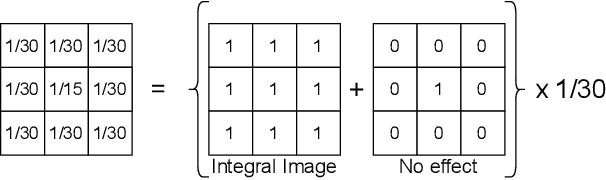
The Structural Similarity (SSIM) Index is a very widely used image/video quality model that continues to play an important role in the perceptual evaluation of compression algorithms, encoding recipes and numerous other image/video processing algorithms. Several public implementations of the SSIM and Multiscale-SSIM (MS-SSIM) algorithms have been developed, which differ in efficiency and performance. This "bendable ruler" makes the process of quality assessment of encoding algorithms unreliable. To address this situation, we studied and compared the functions and performances of popular and widely used implementations of SSIM, and we also considered a variety of design choices. Based on our studies and experiments, we have arrived at a collection of recommendations on how to use SSIM most effectively, including ways to reduce its computational burden.