 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReal-Time 4K Super-Resolution of Compressed AVIF Images. AIS 2024 Challenge Survey
Apr 25, 2024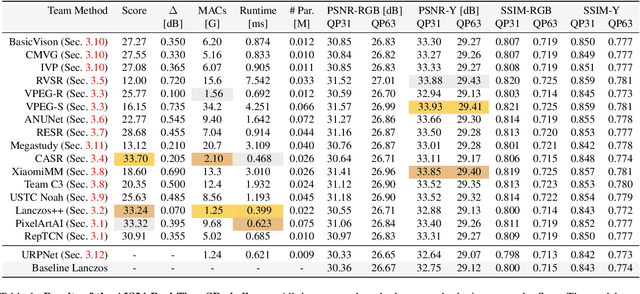
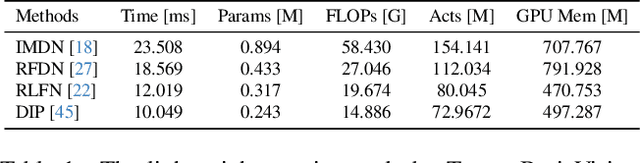
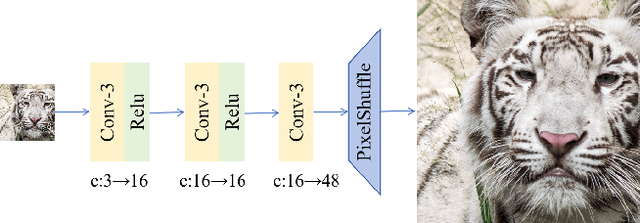
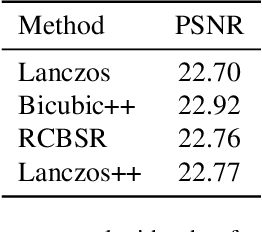
This paper introduces a novel benchmark as part of the AIS 2024 Real-Time Image Super-Resolution (RTSR) Challenge, which aims to upscale compressed images from 540p to 4K resolution (4x factor) in real-time on commercial GPUs. For this, we use a diverse test set containing a variety of 4K images ranging from digital art to gaming and photography. The images are compressed using the modern AVIF codec, instead of JPEG. All the proposed methods improve PSNR fidelity over Lanczos interpolation, and process images under 10ms. Out of the 160 participants, 25 teams submitted their code and models. The solutions present novel designs tailored for memory-efficiency and runtime on edge devices. This survey describes the best solutions for real-time SR of compressed high-resolution images.
Joint Quality Assessment and Example-Guided Image Processing by Disentangling Picture Appearance from Content
Apr 20, 2024
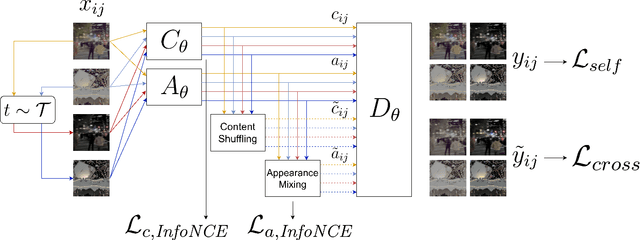
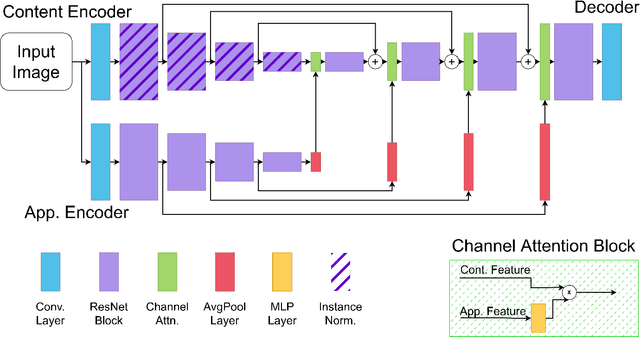

The deep learning revolution has strongly impacted low-level image processing tasks such as style/domain transfer, enhancement/restoration, and visual quality assessments. Despite often being treated separately, the aforementioned tasks share a common theme of understanding, editing, or enhancing the appearance of input images without modifying the underlying content. We leverage this observation to develop a novel disentangled representation learning method that decomposes inputs into content and appearance features. The model is trained in a self-supervised manner and we use the learned features to develop a new quality prediction model named DisQUE. We demonstrate through extensive evaluations that DisQUE achieves state-of-the-art accuracy across quality prediction tasks and distortion types. Moreover, we demonstrate that the same features may also be used for image processing tasks such as HDR tone mapping, where the desired output characteristics may be tuned using example input-output pairs.
Cut-FUNQUE: An Objective Quality Model for Compressed Tone-Mapped High Dynamic Range Videos
Apr 20, 2024



High Dynamic Range (HDR) videos have enjoyed a surge in popularity in recent years due to their ability to represent a wider range of contrast and color than Standard Dynamic Range (SDR) videos. Although HDR video capture has seen increasing popularity because of recent flagship mobile phones such as Apple iPhones, Google Pixels, and Samsung Galaxy phones, a broad swath of consumers still utilize legacy SDR displays that are unable to display HDR videos. As result, HDR videos must be processed, i.e., tone-mapped, before streaming to a large section of SDR-capable video consumers. However, server-side tone-mapping involves automating decisions regarding the choices of tone-mapping operators (TMOs) and their parameters to yield high-fidelity outputs. Moreover, these choices must be balanced against the effects of lossy compression, which is ubiquitous in streaming scenarios. In this work, we develop a novel, efficient model of objective video quality named Cut-FUNQUE that is able to accurately predict the visual quality of tone-mapped and compressed HDR videos. Finally, we evaluate Cut-FUNQUE on a large-scale crowdsourced database of such videos and show that it achieves state-of-the-art accuracy.
A FUNQUE Approach to the Quality Assessment of Compressed HDR Videos
Dec 13, 2023


Recent years have seen steady growth in the popularity and availability of High Dynamic Range (HDR) content, particularly videos, streamed over the internet. As a result, assessing the subjective quality of HDR videos, which are generally subjected to compression, is of increasing importance. In particular, we target the task of full-reference quality assessment of compressed HDR videos. The state-of-the-art (SOTA) approach HDRMAX involves augmenting off-the-shelf video quality models, such as VMAF, with features computed on non-linearly transformed video frames. However, HDRMAX increases the computational complexity of models like VMAF. Here, we show that an efficient class of video quality prediction models named FUNQUE+ achieves SOTA accuracy. This shows that the FUNQUE+ models are flexible alternatives to VMAF that achieve higher HDR video quality prediction accuracy at lower computational cost.
Bitrate Ladder Construction using Visual Information Fidelity
Dec 12, 2023



Recently proposed perceptually optimized per-title video encoding methods provide better BD-rate savings than fixed bitrate-ladder approaches that have been employed in the past. However, a disadvantage of per-title encoding is that it requires significant time and energy to compute bitrate ladders. Over the past few years, a variety of methods have been proposed to construct optimal bitrate ladders including using low-level features to predict cross-over bitrates, optimal resolutions for each bitrate, predicting visual quality, etc. Here, we deploy features drawn from Visual Information Fidelity (VIF) (VIF features) extracted from uncompressed videos to predict the visual quality (VMAF) of compressed videos. We present multiple VIF feature sets extracted from different scales and subbands of a video to tackle the problem of bitrate ladder construction. Comparisons are made against a fixed bitrate ladder and a bitrate ladder obtained from exhaustive encoding using Bjontegaard delta metrics.
One Transform To Compute Them All: Efficient Fusion-Based Full-Reference Video Quality Assessment
Apr 06, 2023The Visual Multimethod Assessment Fusion (VMAF) algorithm has recently emerged as a state-of-the-art approach to video quality prediction, that now pervades the streaming and social media industry. However, since VMAF requires the evaluation of a heterogeneous set of quality models, it is computationally expensive. Given other advances in hardware-accelerated encoding, quality assessment is emerging as a significant bottleneck in video compression pipelines. Towards alleviating this burden, we propose a novel Fusion of Unified Quality Evaluators (FUNQUE) framework, by enabling computation sharing and by using a transform that is sensitive to visual perception to boost accuracy. Further, we expand the FUNQUE framework to define a collection of improved low-complexity fused-feature models that advance the state-of-the-art of video quality performance with respect to both accuracy and computational efficiency.
FUNQUE: Fusion of Unified Quality Evaluators
Feb 23, 2022
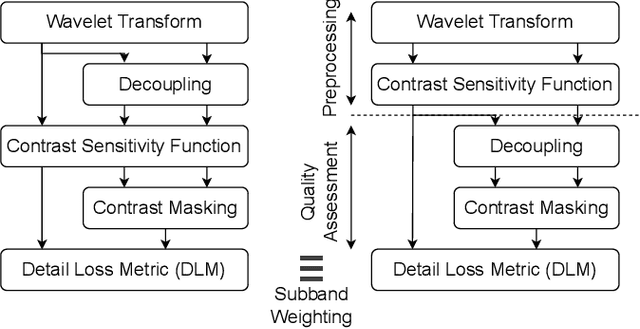
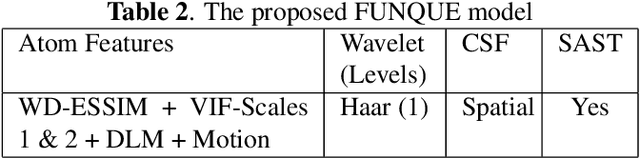
Fusion-based quality assessment has emerged as a powerful method for developing high-performance quality models from quality models that individually achieve lower performances. A prominent example of such an algorithm is VMAF, which has been widely adopted as an industry standard for video quality prediction along with SSIM. In addition to advancing the state-of-the-art, it is imperative to alleviate the computational burden presented by the use of a heterogeneous set of quality models. In this paper, we unify "atom" quality models by computing them on a common transform domain that accounts for the Human Visual System, and we propose FUNQUE, a quality model that fuses unified quality evaluators. We demonstrate that in comparison to the state-of-the-art, FUNQUE offers significant improvements in both correlation against subjective scores and efficiency, due to computation sharing.