 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideo Quality Assessment: A Comprehensive Survey
Dec 04, 2024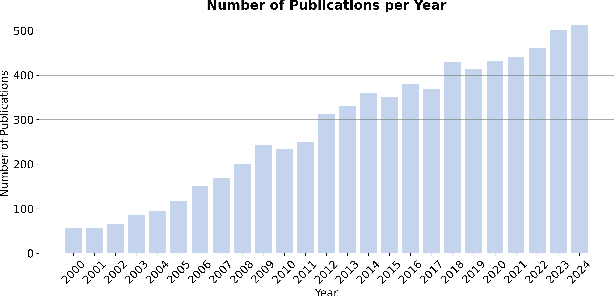
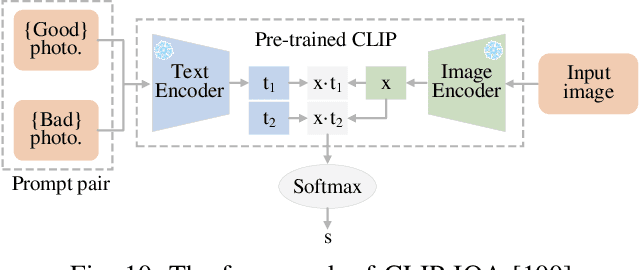
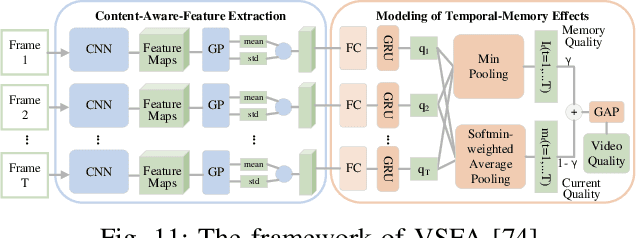
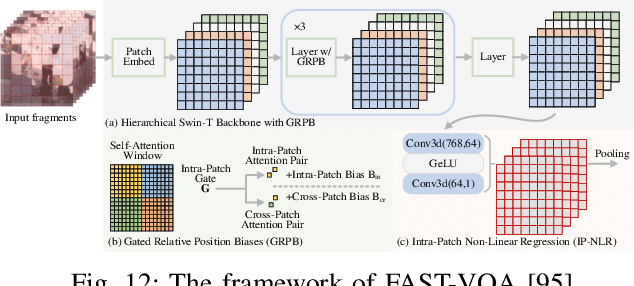
Video quality assessment (VQA) is an important processing task, aiming at predicting the quality of videos in a manner highly consistent with human judgments of perceived quality. Traditional VQA models based on natural image and/or video statistics, which are inspired both by models of projected images of the real world and by dual models of the human visual system, deliver only limited prediction performances on real-world user-generated content (UGC), as exemplified in recent large-scale VQA databases containing large numbers of diverse video contents crawled from the web. Fortunately, recent advances in deep neural networks and Large Multimodality Models (LMMs) have enabled significant progress in solving this problem, yielding better results than prior handcrafted models. Numerous deep learning-based VQA models have been developed, with progress in this direction driven by the creation of content-diverse, large-scale human-labeled databases that supply ground truth psychometric video quality data. Here, we present a comprehensive survey of recent progress in the development of VQA algorithms and the benchmarking studies and databases that make them possible. We also analyze open research directions on study design and VQA algorithm architectures.
Fast QTMT Partition for VVC Intra Coding Using U-Net Framework
Apr 06, 2023



Versatile Video Coding (VVC) has significantly increased encoding efficiency at the expense of numerous complex coding tools, particularly the flexible Quad-Tree plus Multi-type Tree (QTMT) block partition. This paper proposes a deep learning-based algorithm applied in fast QTMT partition for VVC intra coding. Our solution greatly reduces encoding time by early termination of less-likely intra prediction and partitions with negligible BD-BR increase. Firstly, a redesigned U-Net is recommended as the network's fundamental framework. Next, we design a Quality Parameter (QP) fusion network to regulate the effect of QPs on the partition results. Finally, we adopt a refined post-processing strategy to better balance encoding performance and complexity. Experimental results demonstrate that our solution outperforms the state-of-the-art works with a complexity reduction of 44.74% to 68.76% and a BD-BR increase of 0.60% to 2.33%.
An Error-Surface-Based Fractional Motion Estimation Algorithm and Hardware Implementation for VVC
Feb 13, 2023Versatile Video Coding (VVC) introduces more coding tools to improve compression efficiency compared to its predecessor High Efficiency Video Coding (HEVC). For inter-frame coding, Fractional Motion Estimation (FME) still has a high computational effort, which limits the real-time processing capability of the video encoder. In this context, this paper proposes an error-surface-based FME algorithm and the corresponding hardware implementation. The algorithm creates an error surface constructed by the Rate-Distortion (R-D) cost of the integer motion vector (IMV) and its neighbors. This method requires no iteration and interpolation, thus reducing the area and power consumption and increasing the throughput of the hardware. The experimental results show that the corresponding BDBR loss is only 0.47% compared to VTM 16.0 in LD-P configuration. The hardware implementation was synthesized using GF 28nm process. It can support 13 different sizes of CU varying from 128x128 to 8x8. The measured throughput can reach 4K@30fps at 400MHz, with a gate count of 192k and power consumption of 12.64 mW. And the throughput can reach 8K@30fps at 631MHz when only quadtree is searched. To the best of our knowledge, this work is the first hardware architecture for VVC FME with interpolation-free strategies