 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntegrating Weather Foundation Model and Satellite to Enable Fine-Grained Solar Irradiance Forecasting
Mar 17, 2026Accurate day-ahead solar irradiance forecasting is essential for integrating solar energy into the power grid. However, it remains challenging due to the pronounced diurnal cycle and inherently complex cloud dynamics. Current methods either lack fine-scale resolution (e.g., numerical weather prediction, weather foundation models) or degrade at longer lead times (e.g., satellite extrapolation). We propose Baguan-solar, a two-stage multimodal framework that fuses forecasts from Baguan, a global weather foundation model, with high-resolution geostationary satellite imagery to produce 24- hour irradiance forecasts at kilometer scale. Its decoupled two-stage design first forecasts day-night continuous intermediates (e.g., cloud cover) and then infers irradiance, while its modality fusion jointly preserves fine-scale cloud structures from satellite and large-scale constraints from Baguan forecasts. Evaluated over East Asia using CLDAS as ground truth, Baguan-solar outperforms strong baselines (including ECMWF IFS, vanilla Baguan, and SolarSeer), reducing RMSE by 16.08% and better resolving cloud-induced transients. An operational deployment of Baguan-solar has supported solar power forecasting in an eastern province in China, since July 2025. Our code is accessible at https://github.com/DAMO-DI-ML/Baguansolar. git.
A Large-Scale Dataset for Molecular Structure-Language Description via a Rule-Regularized Method
Feb 02, 2026Molecular function is largely determined by structure. Accurately aligning molecular structure with natural language is therefore essential for enabling large language models (LLMs) to reason about downstream chemical tasks. However, the substantial cost of human annotation makes it infeasible to construct large-scale, high-quality datasets of structure-grounded descriptions. In this work, we propose a fully automated annotation framework for generating precise molecular structure descriptions at scale. Our approach builds upon and extends a rule-based chemical nomenclature parser to interpret IUPAC names and construct enriched, structured XML metadata that explicitly encodes molecular structure. This metadata is then used to guide LLMs in producing accurate natural-language descriptions. Using this framework, we curate a large-scale dataset of approximately $163$k molecule-description pairs. A rigorous validation protocol combining LLM-based and expert human evaluation on a subset of $2,000$ molecules demonstrates a high description precision of $98.6\%$. The resulting dataset provides a reliable foundation for future molecule-language alignment, and the proposed annotation method is readily extensible to larger datasets and broader chemical tasks that rely on structural descriptions.
MolLangBench: A Comprehensive Benchmark for Language-Prompted Molecular Structure Recognition, Editing, and Generation
May 21, 2025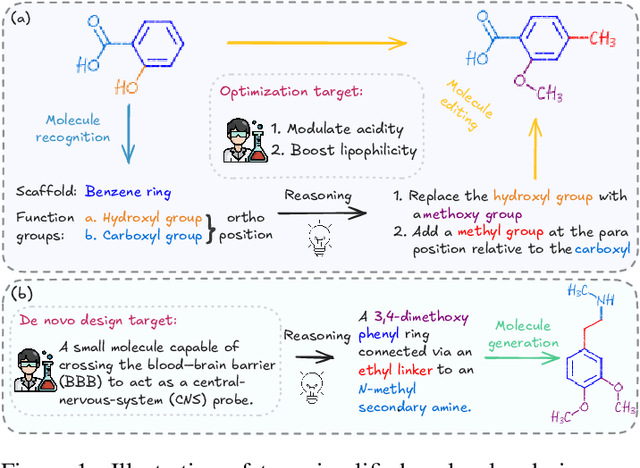
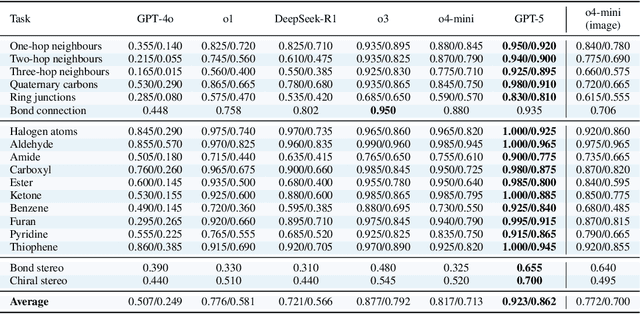
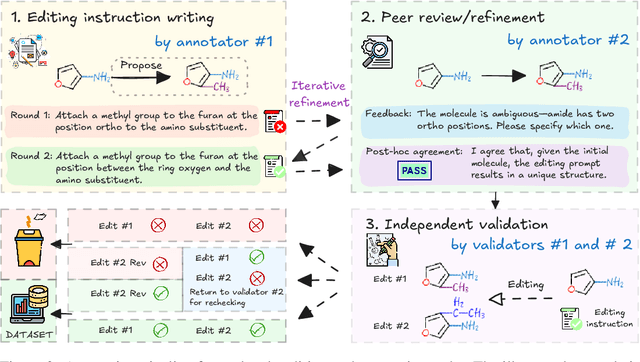

Precise recognition, editing, and generation of molecules are essential prerequisites for both chemists and AI systems tackling various chemical tasks. We present MolLangBench, a comprehensive benchmark designed to evaluate fundamental molecule-language interface tasks: language-prompted molecular structure recognition, editing, and generation. To ensure high-quality, unambiguous, and deterministic outputs, we construct the recognition tasks using automated cheminformatics tools, and curate editing and generation tasks through rigorous expert annotation and validation. MolLangBench supports the evaluation of models that interface language with different molecular representations, including linear strings, molecular images, and molecular graphs. Evaluations of state-of-the-art models reveal significant limitations: the strongest model (o3) achieves $79.2\%$ and $78.5\%$ accuracy on recognition and editing tasks, which are intuitively simple for humans, and performs even worse on the generation task, reaching only $29.0\%$ accuracy. These results highlight the shortcomings of current AI systems in handling even preliminary molecular recognition and manipulation tasks. We hope MolLangBench will catalyze further research toward more effective and reliable AI systems for chemical applications.
Video Quality Assessment: A Comprehensive Survey
Dec 04, 2024
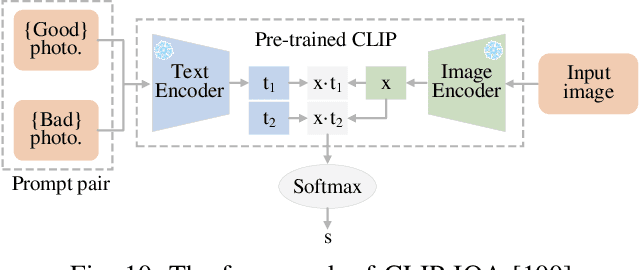
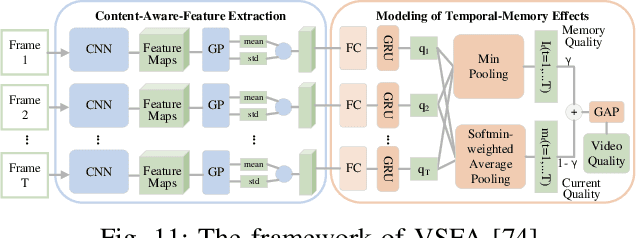
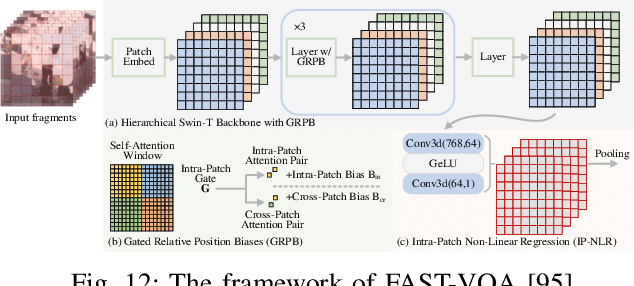
Video quality assessment (VQA) is an important processing task, aiming at predicting the quality of videos in a manner highly consistent with human judgments of perceived quality. Traditional VQA models based on natural image and/or video statistics, which are inspired both by models of projected images of the real world and by dual models of the human visual system, deliver only limited prediction performances on real-world user-generated content (UGC), as exemplified in recent large-scale VQA databases containing large numbers of diverse video contents crawled from the web. Fortunately, recent advances in deep neural networks and Large Multimodality Models (LMMs) have enabled significant progress in solving this problem, yielding better results than prior handcrafted models. Numerous deep learning-based VQA models have been developed, with progress in this direction driven by the creation of content-diverse, large-scale human-labeled databases that supply ground truth psychometric video quality data. Here, we present a comprehensive survey of recent progress in the development of VQA algorithms and the benchmarking studies and databases that make them possible. We also analyze open research directions on study design and VQA algorithm architectures.
Unifying Graph Convolution and Contrastive Learning in Collaborative Filtering
Jun 20, 2024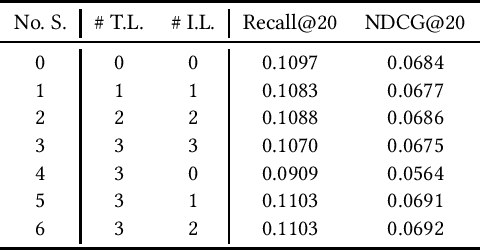
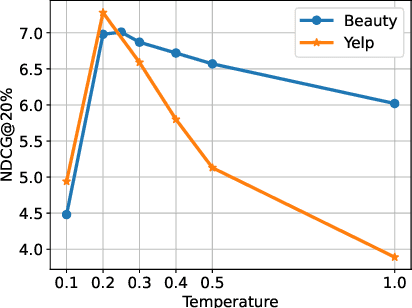
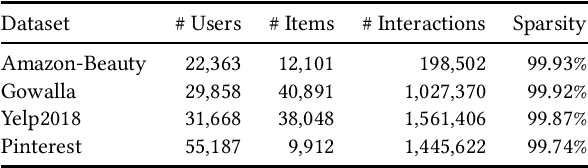
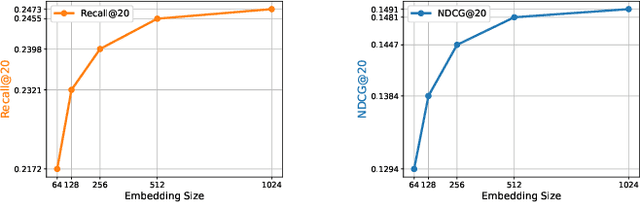
Graph-based models and contrastive learning have emerged as prominent methods in Collaborative Filtering (CF). While many existing models in CF incorporate these methods in their design, there seems to be a limited depth of analysis regarding the foundational principles behind them. This paper bridges graph convolution, a pivotal element of graph-based models, with contrastive learning through a theoretical framework. By examining the learning dynamics and equilibrium of the contrastive loss, we offer a fresh lens to understand contrastive learning via graph theory, emphasizing its capability to capture high-order connectivity. Building on this analysis, we further show that the graph convolutional layers often used in graph-based models are not essential for high-order connectivity modeling and might contribute to the risk of oversmoothing. Stemming from our findings, we introduce Simple Contrastive Collaborative Filtering (SCCF), a simple and effective algorithm based on a naive embedding model and a modified contrastive loss. The efficacy of the algorithm is demonstrated through extensive experiments across four public datasets. The experiment code is available at \url{https://github.com/wu1hong/SCCF}. \end{abstract}
Generalized Contrastive Learning for Multi-Modal Retrieval and Ranking
Apr 12, 2024



Contrastive learning has gained widespread adoption for retrieval tasks due to its minimal requirement for manual annotations. However, popular contrastive frameworks typically learn from binary relevance, making them ineffective at incorporating direct fine-grained rankings. In this paper, we curate a large-scale dataset featuring detailed relevance scores for each query-document pair to facilitate future research and evaluation. Subsequently, we propose Generalized Contrastive Learning for Multi-Modal Retrieval and Ranking (GCL), which is designed to learn from fine-grained rankings beyond binary relevance scores. Our results show that GCL achieves a 94.5% increase in NDCG@10 for in-domain and 26.3 to 48.8% increases for cold-start evaluations, all relative to the CLIP baseline and involving ground truth rankings.
History-Aware Conversational Dense Retrieval
Jan 30, 2024



Conversational search facilitates complex information retrieval by enabling multi-turn interactions between users and the system. Supporting such interactions requires a comprehensive understanding of the conversational inputs to formulate a good search query based on historical information. In particular, the search query should include the relevant information from the previous conversation turns. However, current approaches for conversational dense retrieval primarily rely on fine-tuning a pre-trained ad-hoc retriever using the whole conversational search session, which can be lengthy and noisy. Moreover, existing approaches are limited by the amount of manual supervision signals in the existing datasets. To address the aforementioned issues, we propose a History-Aware Conversational Dense Retrieval (HAConvDR) system, which incorporates two ideas: context-denoised query reformulation and automatic mining of supervision signals based on the actual impact of historical turns. Experiments on two public conversational search datasets demonstrate the improved history modeling capability of HAConvDR, in particular for long conversations with topic shifts.
Attack and Defense Analysis of Learned Image Compression
Jan 18, 2024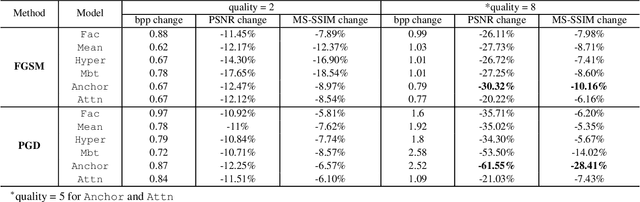

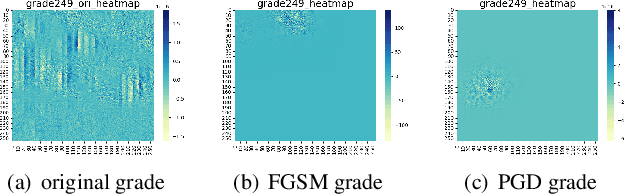
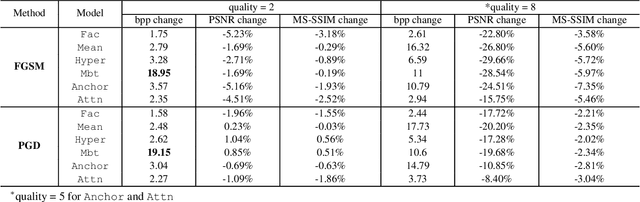
Learned image compression (LIC) is becoming more and more popular these years with its high efficiency and outstanding compression quality. Still, the practicality against modified inputs added with specific noise could not be ignored. White-box attacks such as FGSM and PGD use only gradient to compute adversarial images that mislead LIC models to output unexpected results. Our experiments compare the effects of different dimensions such as attack methods, models, qualities, and targets, concluding that in the worst case, there is a 61.55% decrease in PSNR or a 19.15 times increase in bit rate under the PGD attack. To improve their robustness, we conduct adversarial training by adding adversarial images into the training datasets, which obtains a 95.52% decrease in the R-D cost of the most vulnerable LIC model. We further test the robustness of H.266, whose better performance on reconstruction quality extends its possibility to defend one-step or iterative adversarial attacks.
Collaboration and Transition: Distilling Item Transitions into Multi-Query Self-Attention for Sequential Recommendation
Nov 02, 2023



Modern recommender systems employ various sequential modules such as self-attention to learn dynamic user interests. However, these methods are less effective in capturing collaborative and transitional signals within user interaction sequences. First, the self-attention architecture uses the embedding of a single item as the attention query, which is inherently challenging to capture collaborative signals. Second, these methods typically follow an auto-regressive framework, which is unable to learn global item transition patterns. To overcome these limitations, we propose a new method called Multi-Query Self-Attention with Transition-Aware Embedding Distillation (MQSA-TED). First, we propose an $L$-query self-attention module that employs flexible window sizes for attention queries to capture collaborative signals. In addition, we introduce a multi-query self-attention method that balances the bias-variance trade-off in modeling user preferences by combining long and short-query self-attentions. Second, we develop a transition-aware embedding distillation module that distills global item-to-item transition patterns into item embeddings, which enables the model to memorize and leverage transitional signals and serves as a calibrator for collaborative signals. Experimental results on four real-world datasets show the superiority of our proposed method over state-of-the-art sequential recommendation methods.
Knowledge Combination to Learn Rotated Detection Without Rotated Annotation
Apr 05, 2023



Rotated bounding boxes drastically reduce output ambiguity of elongated objects, making it superior to axis-aligned bounding boxes. Despite the effectiveness, rotated detectors are not widely employed. Annotating rotated bounding boxes is such a laborious process that they are not provided in many detection datasets where axis-aligned annotations are used instead. In this paper, we propose a framework that allows the model to predict precise rotated boxes only requiring cheaper axis-aligned annotation of the target dataset 1. To achieve this, we leverage the fact that neural networks are capable of learning richer representation of the target domain than what is utilized by the task. The under-utilized representation can be exploited to address a more detailed task. Our framework combines task knowledge of an out-of-domain source dataset with stronger annotation and domain knowledge of the target dataset with weaker annotation. A novel assignment process and projection loss are used to enable the co-training on the source and target datasets. As a result, the model is able to solve the more detailed task in the target domain, without additional computation overhead during inference. We extensively evaluate the method on various target datasets including fresh-produce dataset, HRSC2016 and SSDD. Results show that the proposed method consistently performs on par with the fully supervised approach.