 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDivide and Conquer: Rethinking the Training Paradigm of Neural Radiance Fields
Jan 29, 2024Neural radiance fields (NeRFs) have exhibited potential in synthesizing high-fidelity views of 3D scenes but the standard training paradigm of NeRF presupposes an equal importance for each image in the training set. This assumption poses a significant challenge for rendering specific views presenting intricate geometries, thereby resulting in suboptimal performance. In this paper, we take a closer look at the implications of the current training paradigm and redesign this for more superior rendering quality by NeRFs. Dividing input views into multiple groups based on their visual similarities and training individual models on each of these groups enables each model to specialize on specific regions without sacrificing speed or efficiency. Subsequently, the knowledge of these specialized models is aggregated into a single entity via a teacher-student distillation paradigm, enabling spatial efficiency for online render-ing. Empirically, we evaluate our novel training framework on two publicly available datasets, namely NeRF synthetic and Tanks&Temples. Our evaluation demonstrates that our DaC training pipeline enhances the rendering quality of a state-of-the-art baseline model while exhibiting convergence to a superior minimum.
Rethinking Generalization in Few-Shot Classification
Jun 15, 2022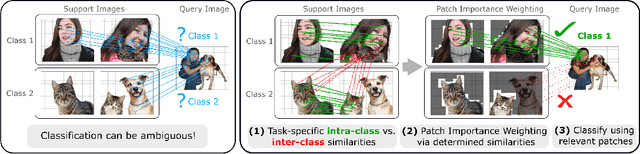
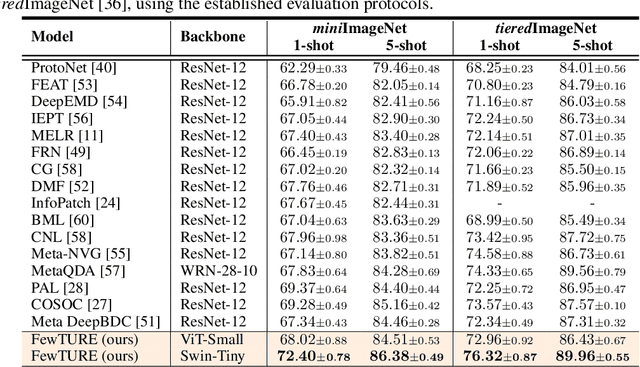
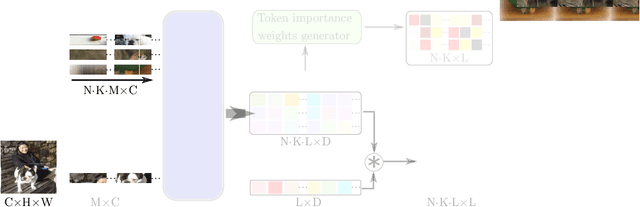
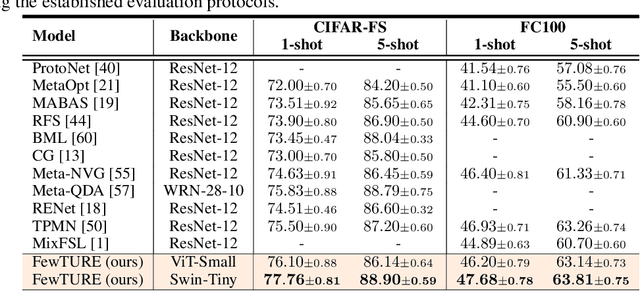
Single image-level annotations only correctly describe an often small subset of an image's content, particularly when complex real-world scenes are depicted. While this might be acceptable in many classification scenarios, it poses a significant challenge for applications where the set of classes differs significantly between training and test time. In this paper, we take a closer look at the implications in the context of $\textit{few-shot learning}$. Splitting the input samples into patches and encoding these via the help of Vision Transformers allows us to establish semantic correspondences between local regions across images and independent of their respective class. The most informative patch embeddings for the task at hand are then determined as a function of the support set via online optimization at inference time, additionally providing visual interpretability of `$\textit{what matters most}$' in the image. We build on recent advances in unsupervised training of networks via masked image modelling to overcome the lack of fine-grained labels and learn the more general statistical structure of the data while avoiding negative image-level annotation influence, $\textit{aka}$ supervision collapse. Experimental results show the competitiveness of our approach, achieving new state-of-the-art results on four popular few-shot classification benchmarks for $5$-shot and $1$-shot scenarios.
Learning Instance and Task-Aware Dynamic Kernels for Few Shot Learning
Dec 07, 2021



Learning and generalizing to novel concepts with few samples (Few-Shot Learning) is still an essential challenge to real-world applications. A principle way of achieving few-shot learning is to realize a model that can rapidly adapt to the context of a given task. Dynamic networks have been shown capable of learning content-adaptive parameters efficiently, making them suitable for few-shot learning. In this paper, we propose to learn the dynamic kernels of a convolution network as a function of the task at hand, enabling faster generalization. To this end, we obtain our dynamic kernels based on the entire task and each sample and develop a mechanism further conditioning on each individual channel and position independently. This results in dynamic kernels that simultaneously attend to the global information whilst also considering minuscule details available. We empirically show that our model improves performance on few-shot classification and detection tasks, achieving a tangible improvement over several baseline models. This includes state-of-the-art results on 4 few-shot classification benchmarks: mini-ImageNet, tiered-ImageNet, CUB and FC100 and competitive results on a few-shot detection dataset: MS COCO-PASCAL-VOC.
Adaptive Poincaré Point to Set Distance for Few-Shot Classification
Dec 03, 2021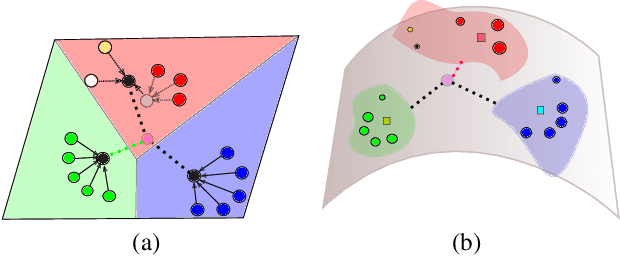

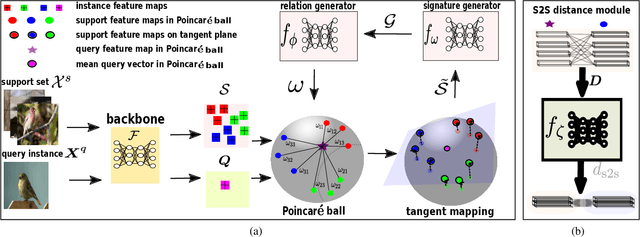

Learning and generalizing from limited examples, i,e, few-shot learning, is of core importance to many real-world vision applications. A principal way of achieving few-shot learning is to realize an embedding where samples from different classes are distinctive. Recent studies suggest that embedding via hyperbolic geometry enjoys low distortion for hierarchical and structured data, making it suitable for few-shot learning. In this paper, we propose to learn a context-aware hyperbolic metric to characterize the distance between a point and a set associated with a learned set to set distance. To this end, we formulate the metric as a weighted sum on the tangent bundle of the hyperbolic space and develop a mechanism to obtain the weights adaptively and based on the constellation of the points. This not only makes the metric local but also dependent on the task in hand, meaning that the metric will adapt depending on the samples that it compares. We empirically show that such metric yields robustness in the presence of outliers and achieves a tangible improvement over baseline models. This includes the state-of-the-art results on five popular few-shot classification benchmarks, namely mini-ImageNet, tiered-ImageNet, Caltech-UCSD Birds-200-2011 (CUB), CIFAR-FS, and FC100.
Learning Online for Unified Segmentation and Tracking Models
Nov 12, 2021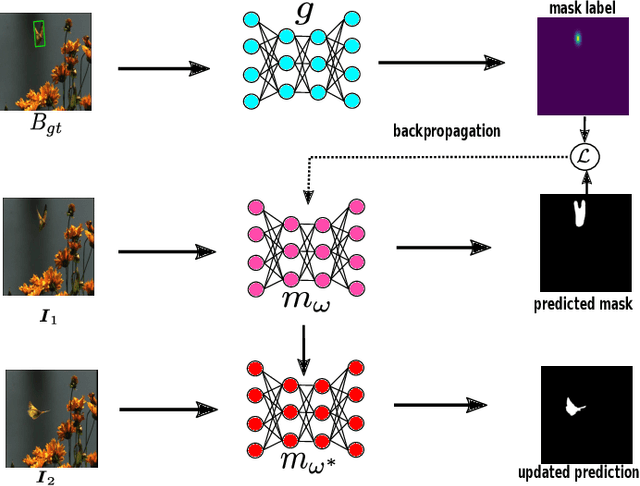
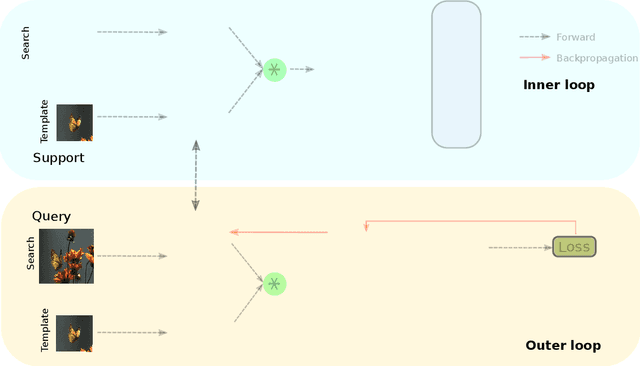

Tracking requires building a discriminative model for the target in the inference stage. An effective way to achieve this is online learning, which can comfortably outperform models that are only trained offline. Recent research shows that visual tracking benefits significantly from the unification of visual tracking and segmentation due to its pixel-level discrimination. However, it imposes a great challenge to perform online learning for such a unified model. A segmentation model cannot easily learn from prior information given in the visual tracking scenario. In this paper, we propose TrackMLP: a novel meta-learning method optimized to learn from only partial information to resolve the imposed challenge. Our model is capable of extensively exploiting limited prior information hence possesses much stronger target-background discriminability than other online learning methods. Empirically, we show that our model achieves state-of-the-art performance and tangible improvement over competing models. Our model achieves improved average overlaps of66.0%,67.1%, and68.5% in VOT2019, VOT2018, and VOT2016 datasets, which are 6.4%,7.3%, and6.4% higher than our baseline. Code will be made publicly available.
Looking Beyond Two Frames: End-to-End Multi-Object Tracking Using Spatial and Temporal Transformers
Mar 27, 2021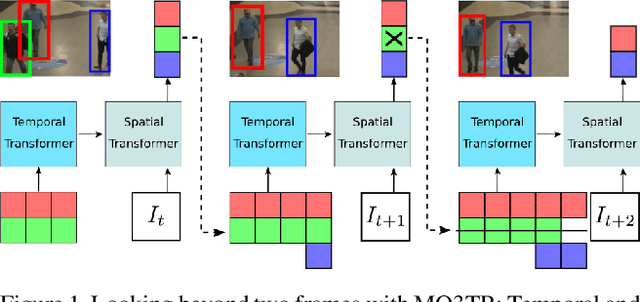
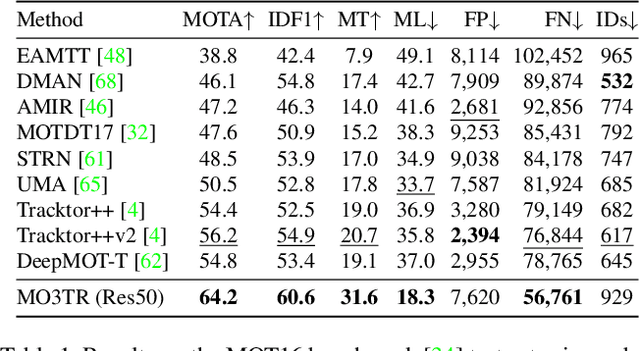
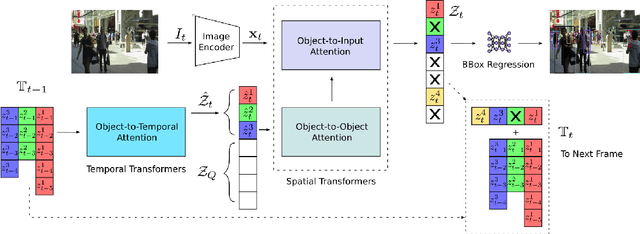
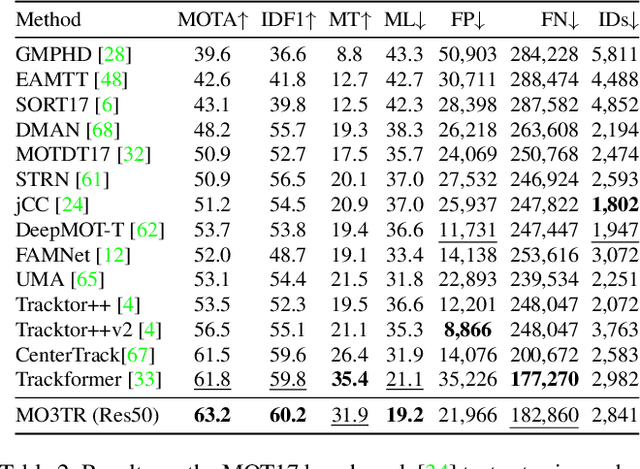
Tracking a time-varying indefinite number of objects in a video sequence over time remains a challenge despite recent advances in the field. Ignoring long-term temporal information, most existing approaches are not able to properly handle multi-object tracking challenges such as occlusion. To address these shortcomings, we present MO3TR: a truly end-to-end Transformer-based online multi-object tracking (MOT) framework that learns to handle occlusions, track initiation and termination without the need for an explicit data association module or any heuristics/post-processing. MO3TR encodes object interactions into long-term temporal embeddings using a combination of spatial and temporal Transformers, and recursively uses the information jointly with the input data to estimate the states of all tracked objects over time. The spatial attention mechanism enables our framework to learn implicit representations between all the objects and the objects to the measurements, while the temporal attention mechanism focuses on specific parts of past information, allowing our approach to resolve occlusions over multiple frames. Our experiments demonstrate the potential of this new approach, reaching new state-of-the-art results on multiple MOT metrics for two popular multi-object tracking benchmarks. Our code will be made publicly available.