 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSocial-MAE: Social Masked Autoencoder for Multi-person Motion Representation Learning
Apr 08, 2024


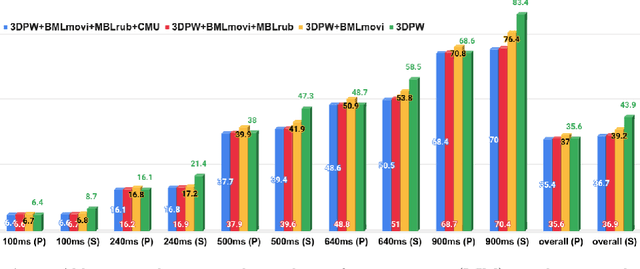
For a complete comprehension of multi-person scenes, it is essential to go beyond basic tasks like detection and tracking. Higher-level tasks, such as understanding the interactions and social activities among individuals, are also crucial. Progress towards models that can fully understand scenes involving multiple people is hindered by a lack of sufficient annotated data for such high-level tasks. To address this challenge, we introduce Social-MAE, a simple yet effective transformer-based masked autoencoder framework for multi-person human motion data. The framework uses masked modeling to pre-train the encoder to reconstruct masked human joint trajectories, enabling it to learn generalizable and data efficient representations of motion in human crowded scenes. Social-MAE comprises a transformer as the MAE encoder and a lighter-weight transformer as the MAE decoder which operates on multi-person joints' trajectory in the frequency domain. After the reconstruction task, the MAE decoder is replaced with a task-specific decoder and the model is fine-tuned end-to-end for a variety of high-level social tasks. Our proposed model combined with our pre-training approach achieves the state-of-the-art results on various high-level social tasks, including multi-person pose forecasting, social grouping, and social action understanding. These improvements are demonstrated across four popular multi-person datasets encompassing both human 2D and 3D body pose.
JRDB-Act: A Large-scale Multi-modal Dataset for Spatio-temporal Action, Social Group and Activity Detection
Jun 16, 2021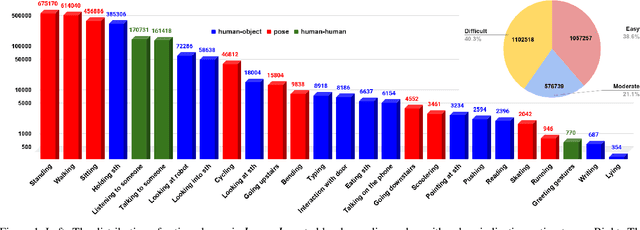
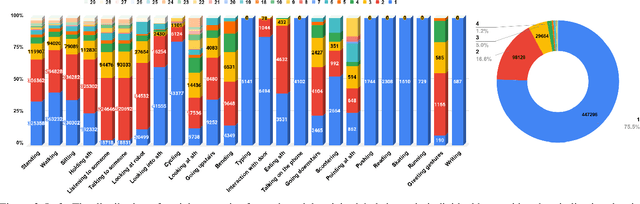
The availability of large-scale video action understanding datasets has facilitated advances in the interpretation of visual scenes containing people. However, learning to recognize human activities in an unconstrained real-world environment, with potentially highly unbalanced and long-tailed distributed data remains a significant challenge, not least owing to the lack of a reflective large-scale dataset. Most existing large-scale datasets are either collected from a specific or constrained environment, e.g. kitchens or rooms, or video sharing platforms such as YouTube. In this paper, we introduce JRDB-Act, a multi-modal dataset, as an extension of the existing JRDB, which is captured by asocial mobile manipulator and reflects a real distribution of human daily life actions in a university campus environment. JRDB-Act has been densely annotated with atomic actions, comprises over 2.8M action labels, constituting a large-scale spatio-temporal action detection dataset. Each human bounding box is labelled with one pose-based action label and multiple (optional) interaction-based action labels. Moreover JRDB-Act comes with social group identification annotations conducive to the task of grouping individuals based on their interactions in the scene to infer their social activities (common activities in each social group).
TRiPOD: Human Trajectory and Pose Dynamics Forecasting in the Wild
Apr 08, 2021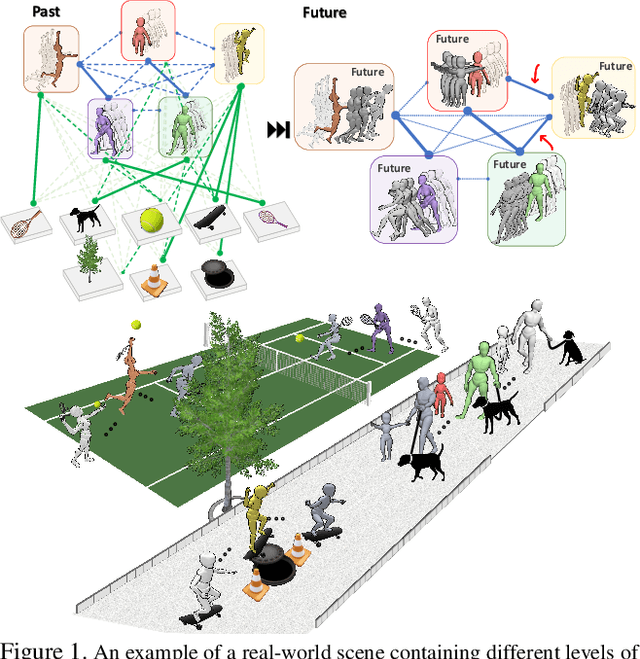
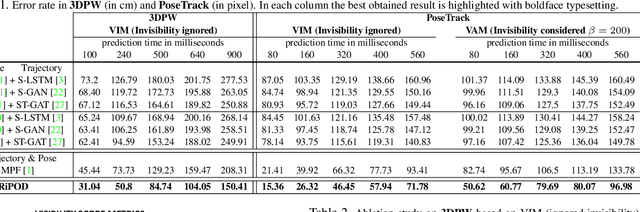
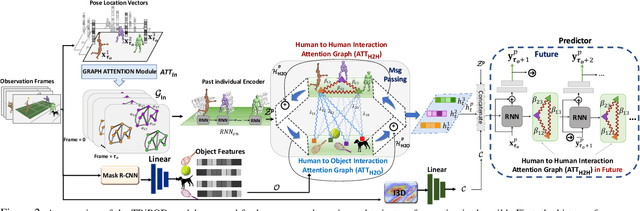
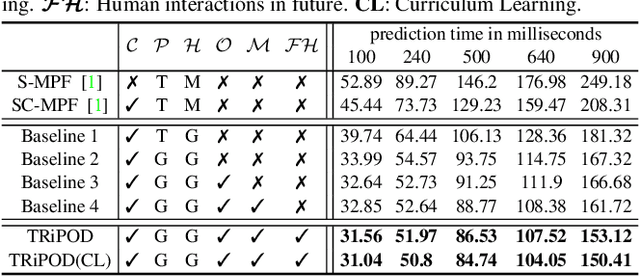
Joint forecasting of human trajectory and pose dynamics is a fundamental building block of various applications ranging from robotics and autonomous driving to surveillance systems. Predicting body dynamics requires capturing subtle information embedded in the humans' interactions with each other and with the objects present in the scene. In this paper, we propose a novel TRajectory and POse Dynamics (nicknamed TRiPOD) method based on graph attentional networks to model the human-human and human-object interactions both in the input space and the output space (decoded future output). The model is supplemented by a message passing interface over the graphs to fuse these different levels of interactions efficiently. Furthermore, to incorporate a real-world challenge, we propound to learn an indicator representing whether an estimated body joint is visible/invisible at each frame, e.g. due to occlusion or being outside the sensor field of view. Finally, we introduce a new benchmark for this joint task based on two challenging datasets (PoseTrack and 3DPW) and propose evaluation metrics to measure the effectiveness of predictions in the global space, even when there are invisible cases of joints. Our evaluation shows that TRiPOD outperforms all prior work and state-of-the-art specifically designed for each of the trajectory and pose forecasting tasks.
Looking Beyond Two Frames: End-to-End Multi-Object Tracking Using Spatial and Temporal Transformers
Mar 27, 2021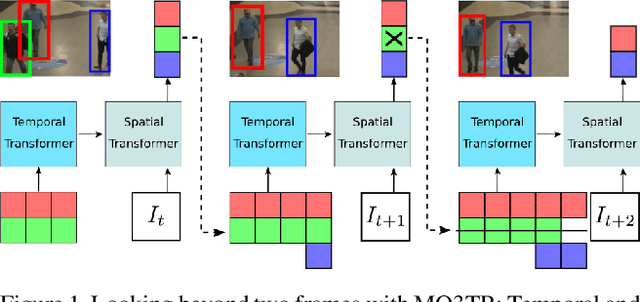
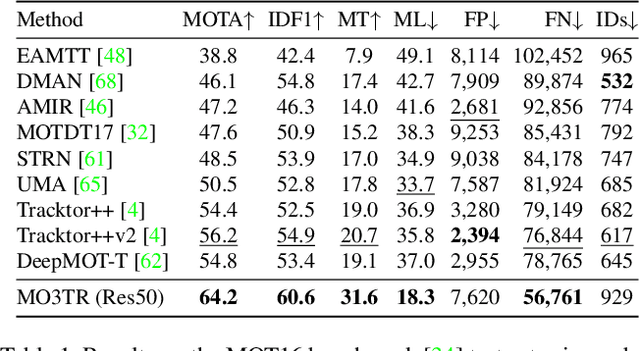
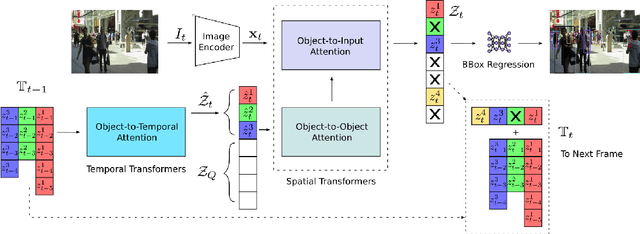
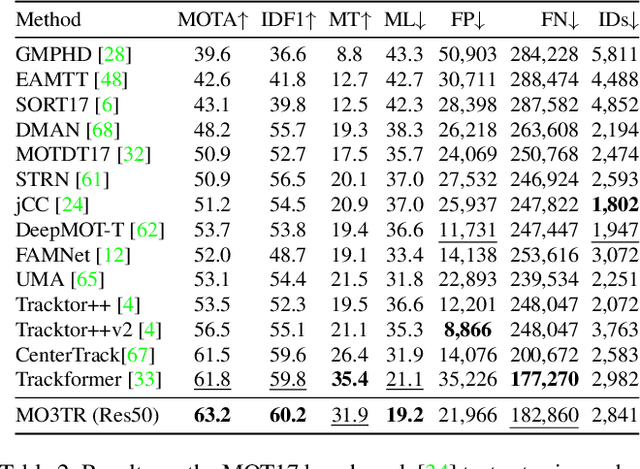
Tracking a time-varying indefinite number of objects in a video sequence over time remains a challenge despite recent advances in the field. Ignoring long-term temporal information, most existing approaches are not able to properly handle multi-object tracking challenges such as occlusion. To address these shortcomings, we present MO3TR: a truly end-to-end Transformer-based online multi-object tracking (MOT) framework that learns to handle occlusions, track initiation and termination without the need for an explicit data association module or any heuristics/post-processing. MO3TR encodes object interactions into long-term temporal embeddings using a combination of spatial and temporal Transformers, and recursively uses the information jointly with the input data to estimate the states of all tracked objects over time. The spatial attention mechanism enables our framework to learn implicit representations between all the objects and the objects to the measurements, while the temporal attention mechanism focuses on specific parts of past information, allowing our approach to resolve occlusions over multiple frames. Our experiments demonstrate the potential of this new approach, reaching new state-of-the-art results on multiple MOT metrics for two popular multi-object tracking benchmarks. Our code will be made publicly available.
Attend And Discriminate: Beyond the State-of-the-Art for Human Activity Recognition using Wearable Sensors
Jul 14, 2020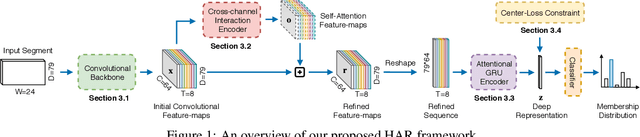

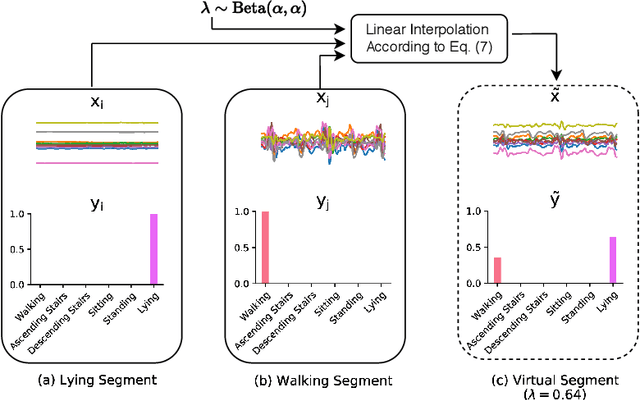
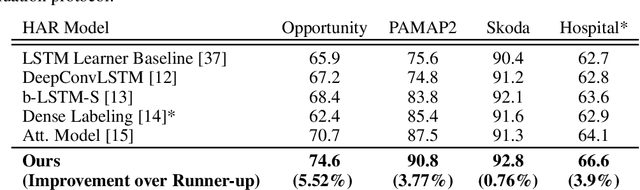
Wearables are fundamental to improving our understanding of human activities, especially for an increasing number of healthcare applications from rehabilitation to fine-grained gait analysis. Although our collective know-how to solve Human Activity Recognition (HAR) problems with wearables has progressed immensely with end-to-end deep learning paradigms, several fundamental opportunities remain overlooked. We rigorously explore these new opportunities to learn enriched and highly discriminating activity representations. We propose: i) learning to exploit the latent relationships between multi-channel sensor modalities and specific activities; ii) investigating the effectiveness of data-agnostic augmentation for multi-modal sensor data streams to regularize deep HAR models; and iii) incorporating a classification loss criterion to encourage minimal intra-class representation differences whilst maximising inter-class differences to achieve more discriminative features. Our contributions achieves new state-of-the-art performance on four diverse activity recognition problem benchmarks with large margins -- with up to 6% relative margin improvement. We extensively validate the contributions from our design concepts through extensive experiments, including activity misalignment measures, ablation studies and insights shared through both quantitative and qualitative studies.
Joint learning of Social Groups, Individuals Action and Sub-group Activities in Videos
Jul 06, 2020
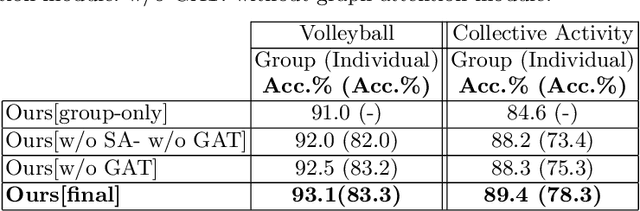
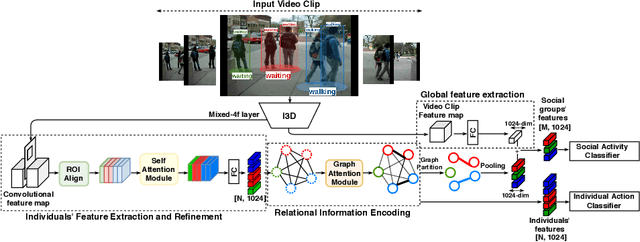
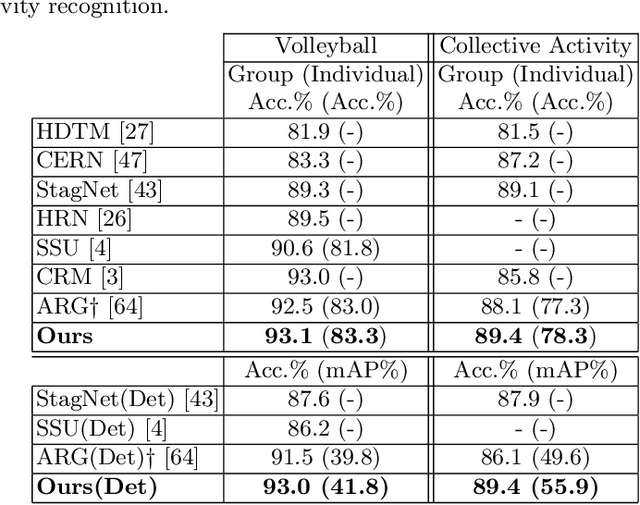
The state-of-the art solutions for human activity understanding from a video stream formulate the task as a spatio-temporal problem which requires joint localization of all individuals in the scene and classification of their actions or group activity over time. Who is interacting with whom, e.g. not everyone in a queue is interacting with each other, is often not predicted. There are scenarios where people are best to be split into sub-groups, which we call social groups, and each social group may be engaged in a different social activity. In this paper, we solve the problem of simultaneously grouping people by their social interactions, predicting their individual actions and the social activity of each social group, which we call the social task. Our main contributions are: i) we propose an end-to-end trainable framework for the social task; ii) our proposed method also sets the state-of-the-art results on two widely adopted benchmarks for the traditional group activity recognition task (assuming individuals of the scene form a single group and predicting a single group activity label for the scene); iii) we introduce new annotations on an existing group activity dataset, re-purposing it for the social task.