 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePerceiving Longer Sequences With Bi-Directional Cross-Attention Transformers
Feb 19, 2024
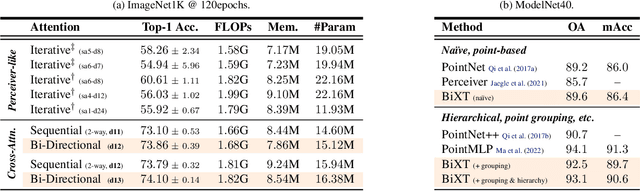
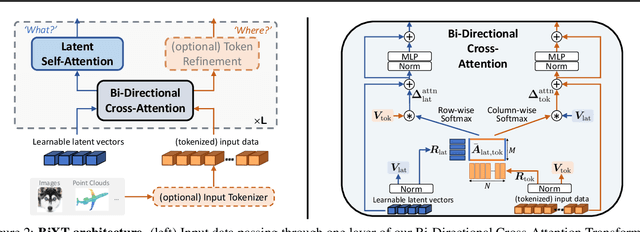
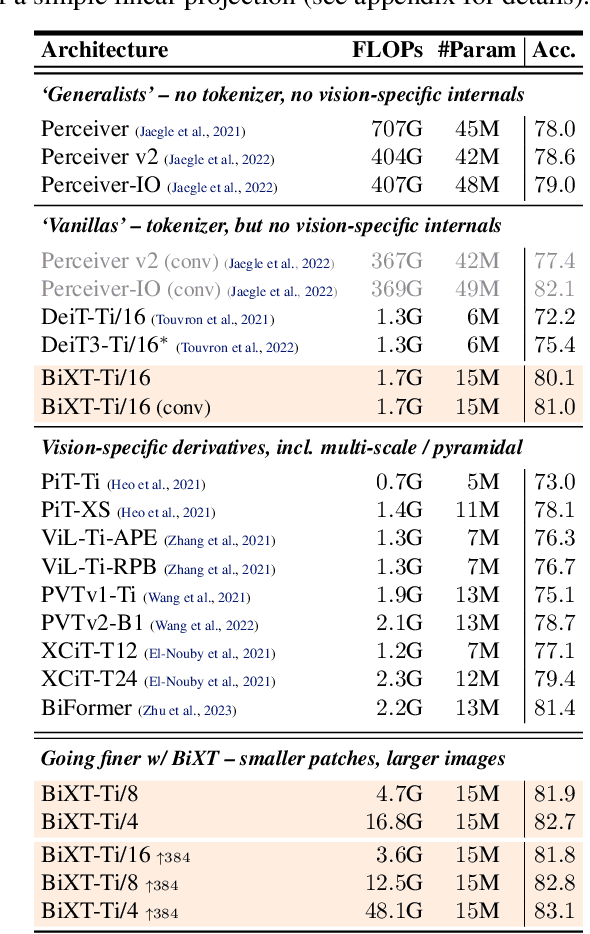
We present a novel bi-directional Transformer architecture (BiXT) which scales linearly with input size in terms of computational cost and memory consumption, but does not suffer the drop in performance or limitation to only one input modality seen with other efficient Transformer-based approaches. BiXT is inspired by the Perceiver architectures but replaces iterative attention with an efficient bi-directional cross-attention module in which input tokens and latent variables attend to each other simultaneously, leveraging a naturally emerging attention-symmetry between the two. This approach unlocks a key bottleneck experienced by Perceiver-like architectures and enables the processing and interpretation of both semantics (`what') and location (`where') to develop alongside each other over multiple layers -- allowing its direct application to dense and instance-based tasks alike. By combining efficiency with the generality and performance of a full Transformer architecture, BiXT can process longer sequences like point clouds or images at higher feature resolutions and achieves competitive performance across a range of tasks like point cloud part segmentation, semantic image segmentation and image classification.
Rethinking Generalization in Few-Shot Classification
Jun 15, 2022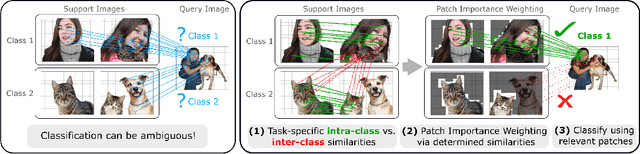
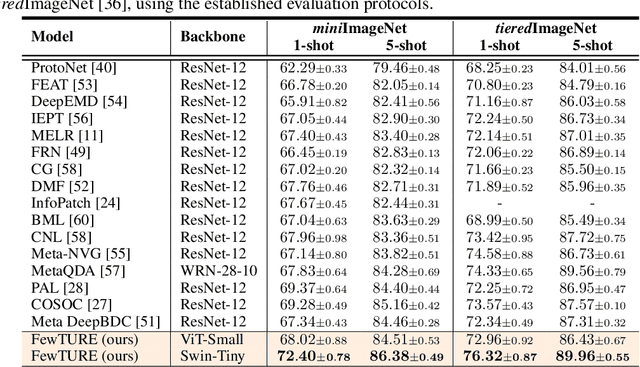
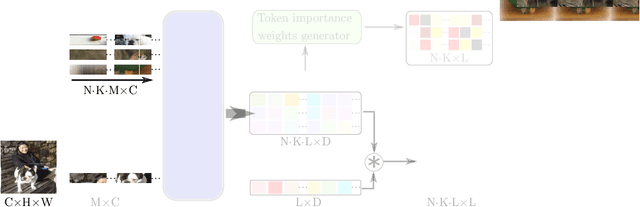
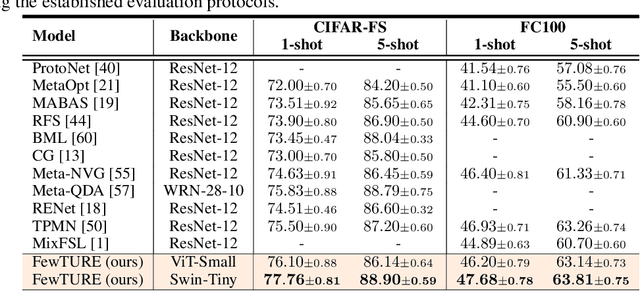
Single image-level annotations only correctly describe an often small subset of an image's content, particularly when complex real-world scenes are depicted. While this might be acceptable in many classification scenarios, it poses a significant challenge for applications where the set of classes differs significantly between training and test time. In this paper, we take a closer look at the implications in the context of $\textit{few-shot learning}$. Splitting the input samples into patches and encoding these via the help of Vision Transformers allows us to establish semantic correspondences between local regions across images and independent of their respective class. The most informative patch embeddings for the task at hand are then determined as a function of the support set via online optimization at inference time, additionally providing visual interpretability of `$\textit{what matters most}$' in the image. We build on recent advances in unsupervised training of networks via masked image modelling to overcome the lack of fine-grained labels and learn the more general statistical structure of the data while avoiding negative image-level annotation influence, $\textit{aka}$ supervision collapse. Experimental results show the competitiveness of our approach, achieving new state-of-the-art results on four popular few-shot classification benchmarks for $5$-shot and $1$-shot scenarios.
On Enforcing Better Conditioned Meta-Learning for Rapid Few-Shot Adaptation
Jun 15, 2022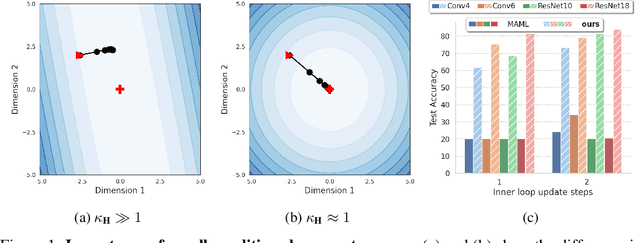

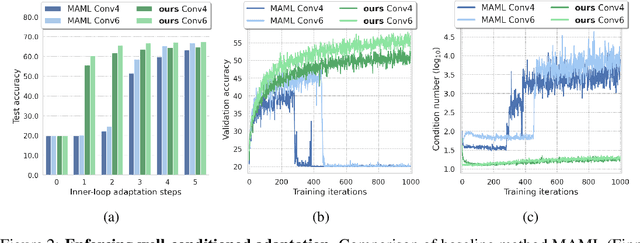
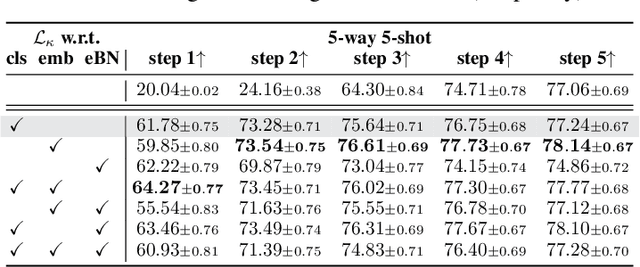
Inspired by the concept of preconditioning, we propose a novel method to increase adaptation speed for gradient-based meta-learning methods without incurring extra parameters. We demonstrate that recasting the optimization problem to a non-linear least-squares formulation provides a principled way to actively enforce a $\textit{well-conditioned}$ parameter space for meta-learning models based on the concepts of the condition number and local curvature. Our comprehensive evaluations show that the proposed method significantly outperforms its unconstrained counterpart especially during initial adaptation steps, while achieving comparable or better overall results on several few-shot classification tasks -- creating the possibility of dynamically choosing the number of adaptation steps at inference time.
Looking Beyond Two Frames: End-to-End Multi-Object Tracking Using Spatial and Temporal Transformers
Mar 27, 2021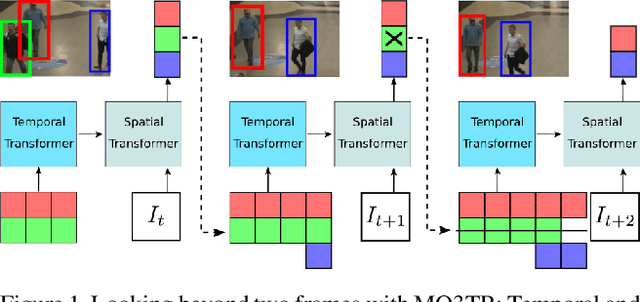
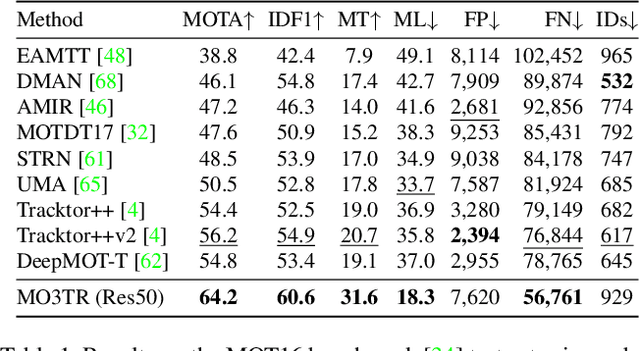
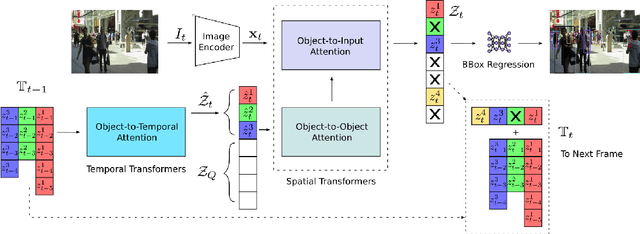
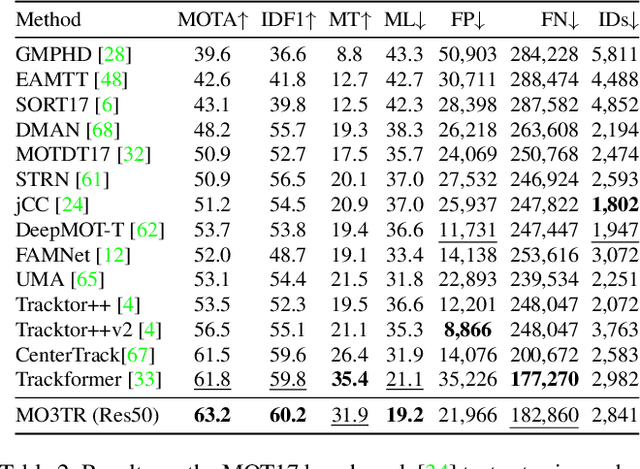
Tracking a time-varying indefinite number of objects in a video sequence over time remains a challenge despite recent advances in the field. Ignoring long-term temporal information, most existing approaches are not able to properly handle multi-object tracking challenges such as occlusion. To address these shortcomings, we present MO3TR: a truly end-to-end Transformer-based online multi-object tracking (MOT) framework that learns to handle occlusions, track initiation and termination without the need for an explicit data association module or any heuristics/post-processing. MO3TR encodes object interactions into long-term temporal embeddings using a combination of spatial and temporal Transformers, and recursively uses the information jointly with the input data to estimate the states of all tracked objects over time. The spatial attention mechanism enables our framework to learn implicit representations between all the objects and the objects to the measurements, while the temporal attention mechanism focuses on specific parts of past information, allowing our approach to resolve occlusions over multiple frames. Our experiments demonstrate the potential of this new approach, reaching new state-of-the-art results on multiple MOT metrics for two popular multi-object tracking benchmarks. Our code will be made publicly available.
Learning Topometric Semantic Maps from Occupancy Grids
Jan 10, 2020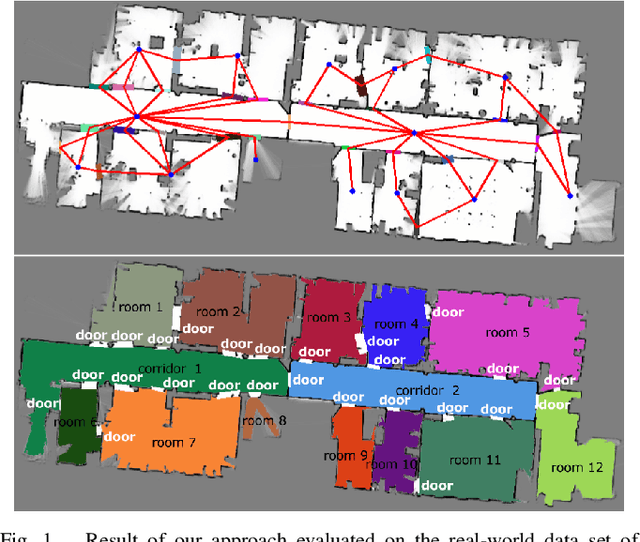
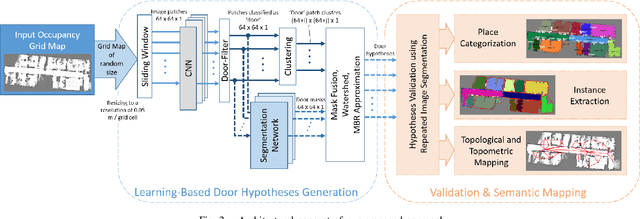
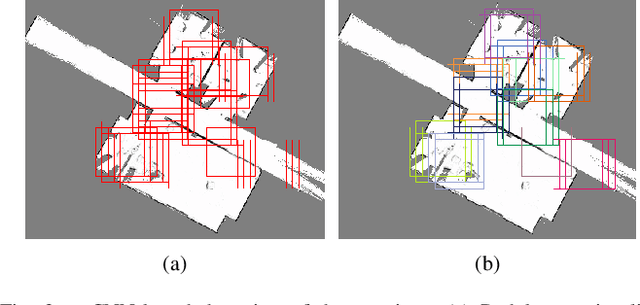
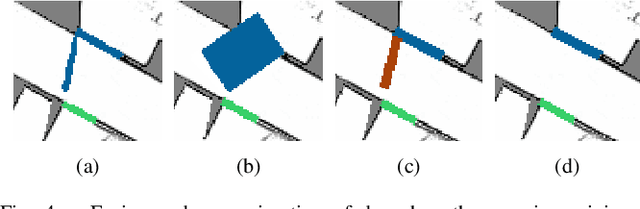
Today's mobile robots are expected to operate in complex environments they share with humans. To allow intuitive human-robot collaboration, robots require a human-like understanding of their surroundings in terms of semantically classified instances. In this paper, we propose a new approach for deriving such instance-based semantic maps purely from occupancy grids. We employ a combination of deep learning techniques to detect, segment and extract door hypotheses from a random-sized map. The extraction is followed by a post-processing chain to further increase the accuracy of our approach, as well as place categorization for the three classes room, door and corridor. All detected and classified entities are described as instances specified in a common coordinate system, while a topological map is derived to capture their spatial links. To train our two neural networks used for detection and map segmentation, we contribute a simulator that automatically creates and annotates the required training data. We further provide insight into which features are learned to detect doorways, and how the simulated training data can be augmented to train networks for the direct application on real-world grid maps. We evaluate our approach on several publicly available real-world data sets. Even though the used networks are solely trained on simulated data, our approach demonstrates high robustness and effectiveness in various real-world indoor environments.